标签:存储 job lib val map add yarn 磁盘存储 string
是一个并行计算框架(计算的数据源比较广泛-HDFS、RDBMS、NoSQL),Hadoop的 MR模块充分利用了HDFS中所有数据节点(datanode)所在机器的内存、CUP以及少量磁盘完成对大数据集的分布式计算。MapReduce将计算分为两个阶段:
I、计算流程
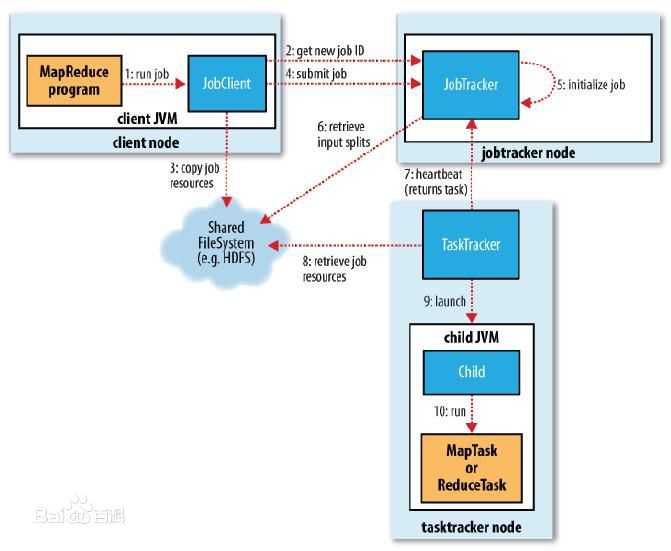
II、YARN环境搭建
配置文件
[root@CentOS ~]# vi /usr/hadoop-2.6.0/etc/hadoop/yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--Resource Manager-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>CentOS</value>
</property> [root@CentOS ~]# mv /usr/hadoop-2.6.0/etc/hadoop/mapred-site.xml.template /usr/hadoop-2.6.0/etc/hadoop/mapred-site.xml
[root@CentOS ~]# vi /usr/hadoop-2.6.0/etc/hadoop/mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>启动计算服务
[root@CentOS ~]# start-yarn.sh
[root@CentOS ~]# jps
1584 SecondaryNameNode
1364 NameNode
1446 DataNode
5229 Jps访问:http://centos:8088/
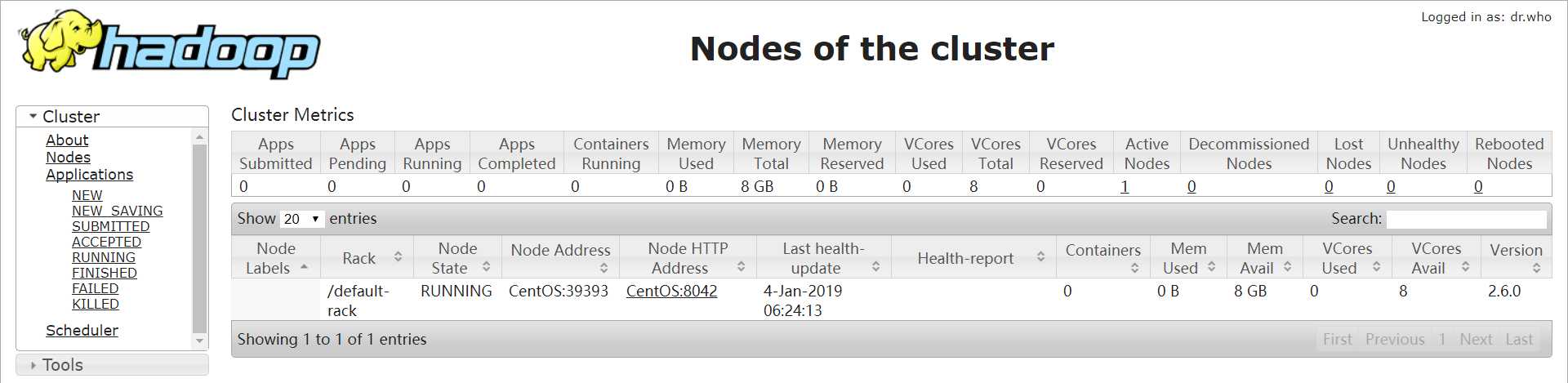
III、HelloWorld of MapReduce 编程
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.6.0</version>
</dependency>IpMapper
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @program: hadoop_01
* @description:
* @author: luoht
* @create: 2019-01-04 16:08
**/
public class IpMapper extends Mapper<LongWritable,Text,Text,IntWritable>{
/**
*192.168.0.12 1 001 click 5000 2019-01-04 14:44:00
* @param key :输入文本行字节偏移量
* @param value:输入文本行
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] tokens = value.toString().split("");
String ip = tokens[0];
context.write(new Text(ip),new IntWritable(1));
}
}IpReducer
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @program: hadoop_01
* @description:
* @author: luoht
* @create: 2019-01-04 16:13
**/
public class IpReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
/**
*
* @param key :ip
* @param values: Int[]{1,1,1,..}
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int total = 0;
for (IntWritable value : values) {
total+=value.get();
}
context.write(key,new IntWritable(total));
}
}
封装job
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* @program: hadoop_01
* @description:
* @author: luoht
* @create: 2019-01-04 16:15
**/
public class CustomJobSubmiter extends Configured implements Tool {
@Override
public int run(String[] strings) throws Exception {
/*1. 封装job 对象*/
Configuration conf=getConf();
Job job = Job.getInstance(conf);
/*2. 设置数据读入和写出的格式*/
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
/*3. 设置处理数据的路径*/
Path dst = new Path("/tt/test");
TextOutputFormat.setOutputPath(job,dst);
/*4. 设置数据计算逻辑*/
Path src=new Path("/tt/access");
TextInputFormat.addInputPath(job,src);
Path dst=new Path("/tt/result");
TextOutputFormat.setOutputPath(job,dst);
/*5. 设置Mapper和Reducer输出泛型*/
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
/*6. 提交任务*/
job.submit();
return 0;
}
public static void main(String[] args) throws Exception {
ToolRunner.run(new CustomJobSubmiter(),args);
}
}标签:存储 job lib val map add yarn 磁盘存储 string
原文地址:https://www.cnblogs.com/adrien/p/10222635.html