标签:激活 round rop 完全 结果 不同的 search ops proposal
2. SPP-Net : Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition)
传统CNN和SPP-Net流程对比如下图所示(引自http://www.image-net.org/challenges/LSVRC/2014/slides/sppnet_ilsvrc2014.pdf)
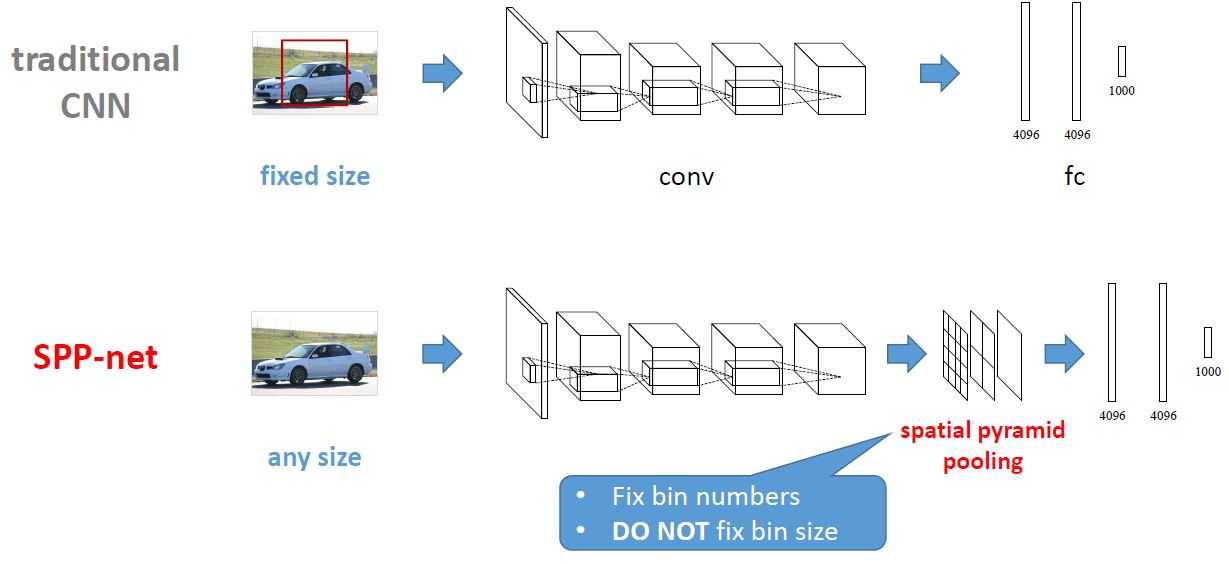
SPP-net具有以下特点:
1.传统CNN网络中,卷积层对输入图像大小不作特别要求,但全连接层要求输入图像具有统一尺寸大小。因此,在R-CNN中,对于selective search方法提出的不同大小的proposal需要先通过Crop操作或Wrap操作将proposal区域裁剪为统一大小,然后用CNN提取proposal特征。相比之下,SPP-net在最后一个卷积层与其后的全连接层之间添加了一个SPP (spatial pyramid pooling) layer,从而避免对propsal进行Crop或Warp操作。总而言之,SPP-layer适用于不同尺寸的输入图像,通过SPP-layer对最后一个卷积层特征进行pool操作并产生固定大小feature map,进而匹配后续的全连接层。
2.由于SPP-net支持不同尺寸输入图像,因此SPP-net提取得到的图像特征具有更好的尺度不变性,降低了训练过程中的过拟合可能性。
3.R-CNN在训练和测试是需要对每一个图像中每一个proposal进行一遍CNN前向特征提取,如果是2000个propsal,需要2000次前向CNN特征提取。但SPP-net只需要进行一次前向CNN特征提取,即对整图进行CNN特征提取,得到最后一个卷积层的feature map,然后采用SPP-layer根据空间对应关系得到相应proposal的特征。SPP-net速度可以比R-CNN速度快24~102倍,且准确率比R-CNN更高(下图引自SPP-net原作论文,可以看到SPP-net中spp-layer前有5个卷积层,第5个卷积层的输出特征在位置上可以对应到原来的图像,例如第一个图中左下角车轮在其conv5的图中显示为“^”的激活区域,因此基于此特性,SPP-net只需要对整图进行一遍前向卷积,在得到的conv5特征后,然后用SPP-net分别提取相应proposal的特征)。

SPP-Layer原理:
在RNN中,conv5后是pool5;在SPP-net中,用SPP-layer替代原来的pool5,其目标是为了使不同大小输入图像在经过SPP-Layer后得到的特征向量长度相同。其原理如图如下所示
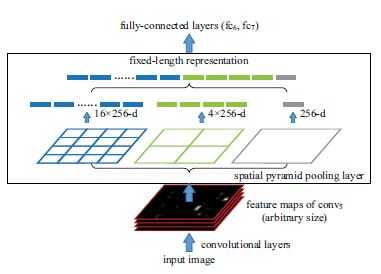
SPP与金字塔pooling类似,即我们先确定最终pooling得到的featuremap大小,例如4*4 bins,3*3 bins,2*2 bins,1*1 bins。那么我们已知conv5输出的featuremap大小(例如,256个13*13的feature map).那么,对于一个13*13的feature map,我们可以通过spatial pyramid pooling (SPP)的方式得到输出结果:当window=ceil(13/4)=4, stride=floor(13/4)=3,可以得到的4*4 bins;当window=ceil(13/3)=5, stride=floor(13/3)=4,可以得到的3*3 bins;当window=ceil(13/2)=7, stride=floor(13/2)=6,可以得到的2*2 bins;当window=ceil(13/1)=13, stride=floor(13/1)=13,可以得到的1*1 bins.因此SPP-layer后的输出是256*(4*4+3*3+2*2+1*1)=256*30长度的向量。不难看出,SPP的关键实现在于通过conv5输出的feature map宽高和SPP目标输出bin的宽高计算spatial pyramid pooling中不同分辨率Bins对应的pooling window和pool stride尺寸。
原作者在训练时采用两种不同的方式,即1.采用相同尺寸的图像训练SPP-net 2.采用不同尺寸的图像训练SPP-net。实验结果表明:使用不同尺寸输入图像训练得到的SPP-Net效果更好。
SPP-Net +SVM训练:
采用selective search可以提取到一系列proposals,由于已经训练完成SPP-Net,那么我们先将整图代入到SPP-Net中,得到的conv5的输出。接下来,区别于R-CNN,新方法不需要对不同尺寸的proposals进行Crop或Wrap,直接根据proposal在图中的相对位置关系计算得到proposal在整图conv5输出中的映射输出结果。这样,对于2000个proposal,我们事实上从conv1--->conv5只做了一遍前向,然后进行2000次conv5 featuremap的集合映射,再通过SPP-Layer,就可以得到的2000组长度相同的SPP-Layer输出向量,进而通过全连接层生成最终2000个proposal的卷积神经网络特征。接下来就和R-CNN类似,训练SVMs时对于所有proposal进行严格的标定(可以这样理解,当且仅当一个候选框完全包含ground truth区域且不属于ground truth部分不超过e.g,候选框区域的5%时认为该候选框标定结果为目标,否则位背景),然后将所有proposal经过CNN处理得到的特征和SVM新标定结果输入到SVMs分类器进行训练得到分类器预测模型。
当然,如果觉得SVM训练很麻烦,可以直接在SPP-Net后再加一个softmax层,用好的标定结果去训练最后的softmax层参数。
标签:激活 round rop 完全 结果 不同的 search ops proposal
原文地址:https://www.cnblogs.com/sddai/p/10230012.html