标签:bubuko iter 情况下 16px 收集 anti 选项 表示 png
接着上一篇,现在明确问题:在汇编克隆搜索文献中,有四种类型的克隆[15][16][17]:Type1.literally identical(字面相同);Type2.syntactically equivalent(语法等价);Type3.slightly modified(稍作修改);Type4.semantically similar(语义相似)。文章主要关注类型4克隆,虽然汇编代码有可能在语法上不同,但是在源代码层次函数的功能逻辑是相同的。例如,有混淆和没有混淆的相同代码,或者不同版本的之间的补丁源代码。
本文使用以下概念:
function:汇编函数
source function:用源代码(eg.C++)写的源函数
repository funcation:存储库中索引的汇编函数
target function:要查询的汇编函数(query)
问题定义:给定一个目标函数ft,搜索问题是从仓库中取出top-k repository funcations(fs属于RP),通过它们的语义相似度进行排名,这样就可以视为Type4克隆。
Asm2Vec模型总体工作流程如图所示:
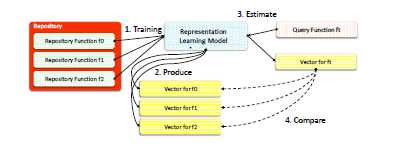
步骤1:给定汇编函数的存储库,首先为这些函数构建神经网络模型,只需要汇编代码作为训练数据不需要任何先验知识。
步骤2:在训练阶段后,模型为每一个存储库的函数生成一个向量表示。
步骤3:给定一个没有经过该模型训练的目标函数ft,使用该模型来生成它的向量表示。
步骤4:使用余弦将ft的向量与存储库中的其他向量进行比较,相似性检索排名前k的候选项作为结果。
训练过程是一次性的工作,可以有效地学习查询的表示。如果向存储库中添加了新的汇编函数,将按照步骤3中的相同过程来估计其向量表示。该模型可以定期进行再训练,以保证向量的质量。
汇编代码的表示学习
接下来讨论汇编代码的表示学习模型。具体来说,本文的设计基于PV-DM模型[20]。PV-DM模型基于文档中的tokens来学习文档表示,然而,文档是按顺序排列的和汇编代码不一样,汇编代码可以表示为图形,并具有特定的语法。首先介绍一下原始的PV-DM神经网络,它是用来学习文本段落的向量表示,然后建立Asm2Vec模型,并描述它是如何在给定函数的指令序列下进行训练的,最后阐述如何将控制流图建模为多个序列。
PV-DM模型是为文本数据而设计的,它是原word2vec模型的扩展,它可以为每个单词和每个段落共同学习向量表示。给定一个包含多个句子的文本段落,PV-DM在每个句子上应用一个滑动窗口。滑动窗口从句子的开头开始,每一步向前移动一个单词。例如在图中滑动窗口的大小为5。第一步,滑动窗口包含五个词“the‘’,“cat”,“sat”,“on”和“a”。中间的单词“sat”作为目标,周围的单词作为上下文。在第二步中,窗口向前移动一个单词包含“cat”,“sat”,“on”,“a”和mat,其中“on”是目标。每一步,PV-DM模型执行一个多层次预测任务(如图)
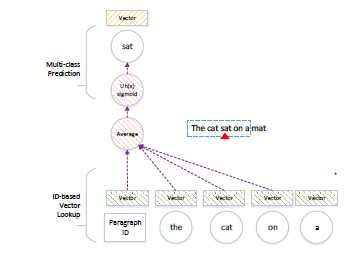
它将基于当前段ID把当前段映射成向量,基于文档中的word ID把每个word映射成向量。通过softmax分类中的单词表来平均这些向量和预测目标词。反向传播的分类错误将用于更新这些向量。
PV-DM是为按顺序排列的文本数据而设计的,然而,汇编代码比纯文本更具有丰富的语法。它包含与纯文本在结构上不同的操作,操作流和控制流。这些差异需要不同的模型架构设计,而PV-DM无法解决这些问题。
Asm2Vec 模型
汇编函数可以用控制流程图(CFG)来表示,本文将控制流程图建模为多个序列,每一个序列对应着一个包含线性排列的汇编指令的潜在执行路径。给定一个二进制文件,使用IDA pro反汇编去提取汇编函数及其基本块和控制流程图列表。
首先介绍Asm2Vec模型流程图中的步骤1和步骤2工作细节:
我们训练模型为每一个存储库的函数产生一个数值向量。下面是该模型用来处理汇编代码的神经网络结构:
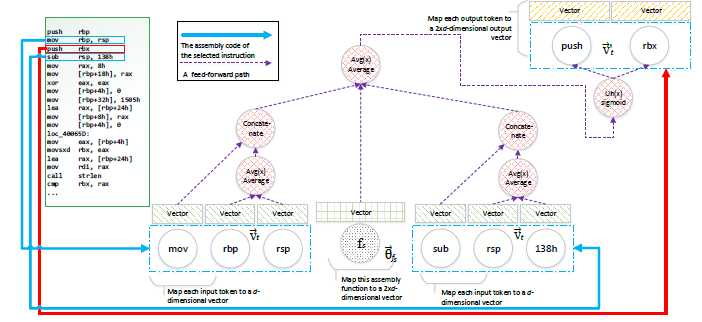
(The proposed Asm2Vec neural network model for assembly code)
首先,将存储库中的每一个函数映射成一个向量。收集了存储库中所有独特的tokens,在汇编代码中将操作和操作数视为tokens,将每一个token t 映射为一个数值向量t1和另一个数值向量t1`,在训练后t1表示为词汇语义,t1向量可视化了tokens之间的关系。t1`是用来做token预测的。所有的函数向量表示和token向量t1都初始化为在0附近的小随机值,所有的t1`向量都随机化为0。用一种定义2xd来把一条指令的操作和操作数联系起来。
然后,把存储库中的函数生成多个指令序列seqs,假设序列的顺序是随机的。每个序列有多条指令,当前的那条指令的定义包含了当前那条指令的所有的操作数和当前指令的一个操作。常量tokens被规范为十六进制形式。
对于函数中的每个序列seq,神经网络从序列的开端开始遍历指令。收集一个序列中的当前指令,之前一个指令和之后一个指令,忽略边界(当前seq)之外的指令。提出的模型试图在存储库函数中最大化以下日志概率:
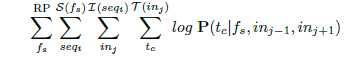
对于在给定的当前汇编函数和附近指令的情况下,它最大化了在当前指令处看到token的日志概率。直觉上是使用当前函数的向量和附近指令提供的上下文来预测当前指令。相邻指令提供的向量捕获有词汇语义关系。函数的向量记住了在特定环境下所能预测的东西。它为区分当前函数和其他函数在指令层次建模。
模型具体步骤流程:
1.对于一个给定的函数fs,通过之前构造的字典,首先查找它的向量表示。
2.为附近(一前一后)的指令建模:针对每条指令,先对其进行操作数的向量平均操作,然后对指令的操作和得到的平均向量进行连接合并操作。
3.将前指令连接合并得到的向量,后指令连接得到的向量,和给定函数找到的向量,三者进行平均操作。
标签:bubuko iter 情况下 16px 收集 anti 选项 表示 png
原文地址:https://www.cnblogs.com/Kluas/p/10234577.html