标签:机构 词汇 步骤 represent http 序列 分析 present token
接着上篇Asm2Vec神经网络模型流程继续,接下来探讨具体过程和细节。
一.为汇编函数建模
二.训练,评估
先来看第一部分为汇编函数建模,这个过程是将存储库中的每一个汇编函数建模为多个序列。由于控制流图的原始线性布局覆盖了一些无效的执行路径,不能直接使用它作为训练序列。相反,可以将控制流程图建模为边缘覆盖序列和随机游动,除此之外,还要考虑函数内联等编译器优化。
1.1选择性被扩张. 函数内联这种技术,用被调用函数的主体替换调用指令。扩展了原来的汇编函数,并通过删除调用开销提高了其性能。它显著地修改了控制流图,是汇编克隆搜索[12][13]的一个主要挑战。本文采用让函数调用指令有选择地被调用函数的主体展开,BinGo[12]内联所有标准库调用,以确保语义正确。本文不用内联任何库调用,因为库调用tokens之间的词汇语义已经被模型很好地捕获了(之前提到过的这些训练汇编代码不包含任何库内联调用,直接用普通的汇编代码训练Asm2Vec模型,得到三类tokens(操作数,操作,库函数调用)每一个token的200维数值向量)。对于递归调用的处理,采用被调用函数的入度和出度比作为解耦指标,决定被调用函数是否展开。
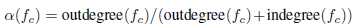
设置阈值为0.01,调用别人为出度,被别人调用为入度。如果发现被调用函数比调用函数具有相当的长度,展开后类似于被调用函数。因此,添加一个额外的度量来过滤掉冗长的调用:
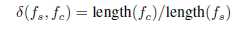
如果被调用函数长度占调用函数长度的比小于0.6,或者调用函数小于10行指令,则内联被调用函数。
1.2边缘覆盖. 为了生成一个汇编函数的多个序列,从已经内联扩张的控制流程图中随机采样所有的边,直到原始图中的所有边都被覆盖。对于每条采样边,将它们的汇编代码串联起来,形成一个新的序列。这样,可以确保控制流程图被完全覆盖。及时控制流程图中的基本快被分割或者合并,模型也可以产生类似的序列。
1.3随机路线. CACompare[13]使用随机输入序列来分析汇编函数的I/O行为,随机输入模拟有效执行流上的随机路线。受此方法的启发,本文通过在已经扩展的CFG上用填充多个随机路线的方式针对一个汇编函数进行扩展汇编序列。Dominator是一个在控制流分析和编译器优化中广泛使用的盖帘。如果一个基本必须通过另一个基本块才能到达另一个基本块,那么该基本块就占主导地位。多个随机游走将使覆盖主导其他块的基本块(主导块)的概率更高。这些主导块可以指示循环机构,也可以覆盖重要分支条件。使用随机路线可以被认为是一种自然方法来优化处理那些主导块。
第二部分主要是训练的过程,评估的流程,以及实验所用的相关配置。
训练过程算法如下:

算法1针对存储库中的每一个函数,通过边采样和随机路线的方式生成了序列。对于每个序列,它遍历每个指令并应用Asm2Vec更新向量(第10行到第19行)。如算法1,训练过程不需要等效汇编函数之间的ground-truth映射。

对于给定一个查询ft,用一个向量表示它,初始化为接近0的很小值。然后用神经网络遍历关于此函数的每一个序列和每一条指令。在每一个预测步骤中,针对token t生成的两个向量t,和t1(用来做预测的),只传播错误给查询ft向量,整个训练结束后,就有了函数ft的向量和属于存储库中函数的向量和所有tokens字典D中由token t生成的两个向量t, t1组成的向量相同,搜索匹配的衡量,通过计算向量之间的余弦相似度。
可扩展性对于二进制克隆搜索很重要,因为存储库中可能有数百万个程序集函数,在大规模的汇编代码上训练Asm2Vec是可行的。一个类似的文本模型已经被证明可以扩展到数十亿个文本样本来训练[21]。在本文研究中,使用成对相似性来搜索最近邻居。在低维固定长度向量之间进行两两搜索是快速的。
标签:机构 词汇 步骤 represent http 序列 分析 present token
原文地址:https://www.cnblogs.com/Kluas/p/10238204.html