标签:pts 模块 exp 环境 rop 索引 slave 1.0 stop
Hadoop:
数据存储模块
数据计算模块
doug cutting //hadoop之父
//分布式文件系统GFS,可用于处理海量网页的存储
//分布式计算框架MAP REDUCE,可用于处理海量网页的索引计算问题
hadoop:
GFS ====> NDFS(Nutch distributed filesystem)===> HDFS
Mapreduce ====> Mapreduce
hadoop安装:
=========================================
本地模式:使用的存储系统,是Linux系统
1、将安装包通过winscp发送到centos家目录
2、解压安装包到/soft下
tar -xzvf hadoop-2.7.3.tar.gz -C /soft
3、进入到/soft下,建立符号链接
cd /soft
ln -s hadoop-2.7.3/ hadoop
4、配置环境变量 //sudo nano /etc/profile
# hadoop环境变量
export HADOOP_HOME=/soft/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
5、使环境变量生效
source /etc/profile
6、验证hadoop
hadoop version
7、测试hadoop
hdfs dfs -ls //列出
hdfs dfs -mkdir //创建文件夹
hdfs dfs -cat //查看文件内容
hdfs dfs -touchz //创建文件
hdfs dfs -rm //删除文件
伪分布式:使用Hadoop文件系统,只用一个主机
1、配置文件,使hadoop三种模式共存
1)进入hadoop配置文件夹
cd /soft/hadoop/etc/
2)重命名hadoop文件夹为local(本地模式)
mv hadoop local
3)拷贝local文件夹为pseudo和full
cp -r local pseudo
cp -r local full
4)创建hadoop符号链接指向pseudo
ln -s pseudo hadoop
2、修改配置文件
1)进入hadoop配置文件夹
cd /soft/hadoop/etc/hadoop
2)配置文件core-site.xml
---------------------------------------------
<?xml version="1.0"?>
<!-- value标签需要写本机ip -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.17.100/</value>
</property>
</configuration>
3)配置文件hdfs-site.xml
---------------------------------------------
<?xml version="1.0"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
4)配置文件mapred-site.xml
---------------------------------------------
<?xml version="1.0"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5)配置文件yarn-site.xml
---------------------------------------------
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.17.100</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
6)修改hadoop-env.sh,修改第25行
---------------------------------------------
export JAVA_HOME=/soft/jdk
7)格式化文件系统
---------------------------------------------
hdfs namenode -format
8)启动hadoop
-----------------------------------------------
start-all.sh //其中要输入多次密码
9)通过jps查看进程 //java process
-------------------------------------------------
4018 DataNode
4195 SecondaryNameNode
4659 NodeManager
4376 ResourceManager
3885 NameNode
4815 Jps
体验hadoop:
====================================================
进入hadoop的web界面:
192.168.23.100:50070
列出hdfs的文件系统
hdfs dfs -ls /
在hdfs中创建文件
hdfs dfs -touchz /1.txt
上传文件到hdfs
hdfs dfs -put jdk.tar.gz /
从hdfs下载文件
hdfs dfs -get /1.txt
体验Mapreduce
1)创建文件hadoop.txt并添加数据
2)将hadoop.txt上传到hdfs
hdfs dfs -put hadoop.txt /
3)使用hadoop自带的demo进行单词统计
hadoop jar /soft/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /1.txt /out
4)通过web界面查看hadoop运行状态
http://192.168.23.100:8088
ssh: secure shell
===========================================
1、远程登录
2、在远程主机上执行命令
配置ssh免密登录
1、生成公私密钥对
ssh-keygen -t rsa -P ‘‘ -f ~/.ssh/id_rsa
-t //指定算法rsa
-P //指定一个字符串进行加密
-f //指定生成文件的位置
2、将公钥拷贝到其他节点
ssh-copy-id centos@192.168.23.100
3、测试ssh
ssh 192.168.17.100
4、停止hadoop
stop-all.sh
完全分布式:
=============================================
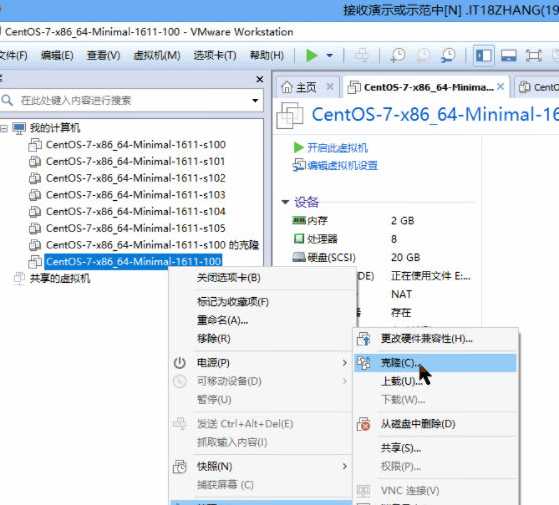
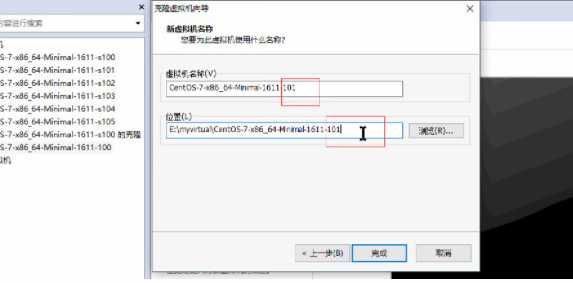
1、克隆主机 //链接克隆
2、打开s101-s104
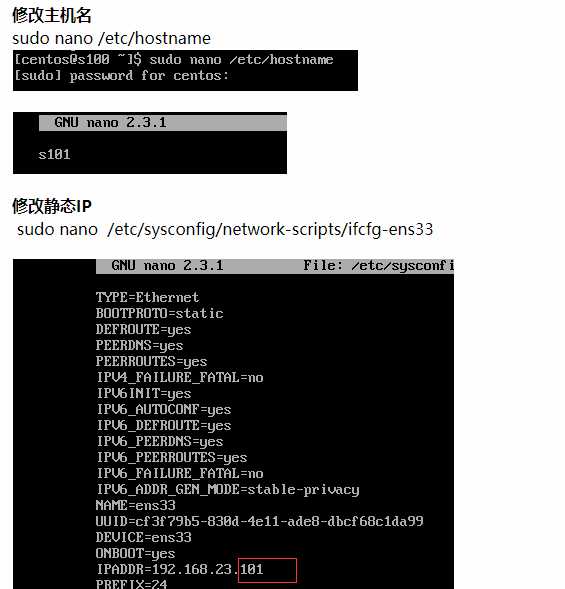
3、修改主机名 //sudo nano /etc/hostname
101 => s101
102 => s102
103 => s103
104 => s104
4、修改静态ip //sudo nano /etc/sysconfig/network-scripts/ifcfg-ens33
100 => 101
100 => 102
100 => 103
100 => 104
5、重启客户机
reboot
6、修改hosts文件,修改主机名和ip的映射 // sudo nano /etc/hosts
192.168.17.101 s101
192.168.17.102 s102
192.168.17.103 s103
192.168.17.104 s104
192.168.17.105 s105
7、配置s101到其他主机的免密登陆
s101 => s101
=> s102
=> s103
=> s104
1)在s101生成公私密钥对
ssh-keygen -t rsa -P ‘‘ -f ~/.ssh/id_rsa
2)分别将公钥拷贝到其他节点
ssh-copy-id centos@s101
ssh-copy-id centos@s102
ssh-copy-id centos@s103
ssh-copy-id centos@s104
8、修改hadoop配置文件
0)修改hadoop符号链接,指向full
ln -sfT /soft/hadoop/etc/full /soft/hadoop/etc/hadoop
1)core-site.xml
<?xml version="1.0"?>
<!-- value标签需要写本机ip -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://s101</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/centos/hadoop</value>
</property>
</configuration>
2)hdfs-site.xml
<?xml version="1.0"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
3)mapred-site.xml
<?xml version="1.0"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
4)yarn-site.xml
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>s101</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
5)hadoop-env.sh
第25行修改
export JAVA_HOME=/soft/jdk
6)修改slaves文件,将localhost改为
s102
s103
s104
7)同步配置文件
1.将其他节点的/soft/hadoop/etc删掉
ssh s102 rm -rf /soft/hadoop/etc
ssh s104 rm -rf /soft/hadoop/etc
ssh s103 rm -rf /soft/hadoop/etc
2.将本机的/soft/hadoop/etc分发到其他节点
scp -r /soft/hadoop/etc centos@s104:/soft/hadoop/
scp -r /soft/hadoop/etc centos@s103:/soft/hadoop/
scp -r /soft/hadoop/etc centos@s102:/soft/hadoop/
8)格式化hadoop文件系统
hdfs namenode -format
9)启动hadoop
start-all.sh
体验hadoop完全分布式:
============================================
1)打开web界面
192.168.23.101:50070
2)将hadoop.txt上传到hdfs
hdfs dfs -put hadoop.txt /
3)使用hadoop自带的demo进行单词统计
hadoop jar /soft/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /hadoop.txt /out
4)通过web界面查看hadoop运行状态
http://192.168.23.101:8088
05.伪分布式、分布式搭建
标签:pts 模块 exp 环境 rop 索引 slave 1.0 stop
原文地址:https://www.cnblogs.com/star521/p/10241072.html