标签:sof 字符串 .com utf-8 命令执行 https 默认 imp 解析
0x00 beautiful soup
首先安装beautiful soup,直接在cmd中使用pip install beautifulsoup4命令执行安装,若使用pycharmIDE 的话,参考之前安装requests库的方法。
beautiful soup库是解析、遍历、维护标签树的功能库。
beautiful soup库解析器:

beautiful soup类的基本元素:

以一个网页为例:https://python123.io/ws/demo.html
先用requests库获取该url页面的内容并将内容赋值给demo
import requests url = "https://python123.io/ws/demo.html" r = requests.get(url) demo = r.text print(demo)
接着开始使用beautiful soup
from bs4 import BeautifulSoup soup = BeautifulSoup(demo, "html.parser")
这时,soup变量就是解析后的demo页面
接着就可以查看该页面的详细信息了
我们可以查询a标签的名字、a的父标签的名字、a的父标签的父标签的名字
print(soup.a.name) print(soup.a.parent.name) print(soup.a.parent.parent.name)

也可以查询标签的属性:
attr = soup.a.attrs print(attr)

返回的值是一个字典,我们可以通过键来查询对应的值
print(attr["class"])

接下来是string方法,作用是获取一对标签之间的字符串内容
str = soup.a.string print(str)

0x01 基于bs4库的遍历方法
遍历的方法可分为下行遍历、上行遍历、平行遍历
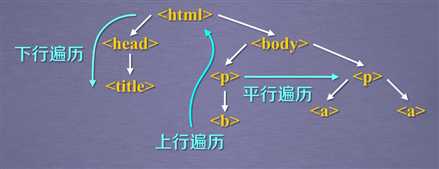
下行遍历包含三个属性

依然以上一个网页为例
head = soup.head.contents print(head)
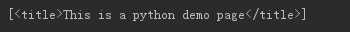
返回了一个列表,当列表中有多个标签时,可以用head[0]的形式来选择
遍历子节点的代码框架:
for child in soup.body.children: print(child)
遍历子孙节点的代码框架:
for child in soup.body.descendants: print(child)
上行遍历有两个属性:

上行遍历代码框架:
soup = BeautifulSoup(demo, "html.parser") for parent in soup.a.parents: if parent is None: print(parent) else: print(parent.name)
平行遍历四个属性:

【注意】平行遍历得到的不一定是Tag,也可能是Navigablestring属性的值,例如:
soup = BeautifulSoup(demo, "html.parser") print(soup.a.next_sibling)

标签树的平行遍历代码:
for sibling in soup.a.next_siblings: #遍历后续节点 print(sibling)
for sibling in soup.a.previous_siblings: #遍历前续节点 print(sibling)
0x02 prettify()方法
prettify()方法为html文档中标签和内容添加换行符,使内容可读性更强。
soup = BeautifulSoup(demo, "html.parser") print(soup.prettify())
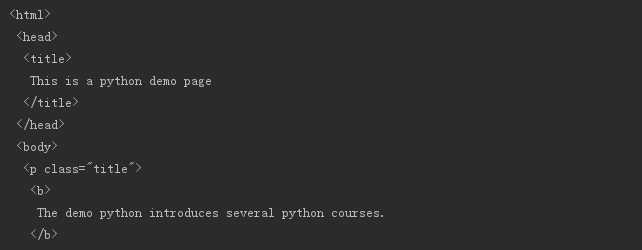
没有使用prettify()方法的结果:

0x03 bs4库的编码
强烈推荐使用python3以上版本,bs4库将所有内容都转换为utf-8编码,python3.x的默认编码也是utf-8,采用python2.x系列会导致无穷无尽的编码转换。
标签:sof 字符串 .com utf-8 命令执行 https 默认 imp 解析
原文地址:https://www.cnblogs.com/Ragd0ll/p/10238811.html