标签:都对 1.0 求导 更新 nes atp matrix ret 预测
都说万事开头难,可一旦开头,就是全新的状态,就有可能收获自己未曾预料到的成果。记录是为了更好的监督、理解和推进,学习过程中用到的数据集和代码都将上传到github
回归是对一个或多个自变量和因变量之间的关系进行建模,求解的一种统计方法,更多关于回归的内容将在后续总结。本博主要总结如何利用激活函数中Sigmoid函数和梯度下降算法实现Logistic回归分类器对数据进行分类
激活函数是对神经网络中某一部分神经元的非线性运算,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到众多的非线性模型中,激活函数一般要求可微,且不会改变输入数据的维度。sigmoid函数是传统神经网络常用的一种激活函数,优点在于输出映射在(0,1)内,单调连续,适合用作输出层,求导容易;缺点是具有软饱和性,一旦输入数据落入包河区,一阶导数变得接近0,就可能产生梯度消失问题。
函数原型:f(x) = 1 / (1 + exp(-x))
下图为x在[-10, 10]和[-60,60]区间的sigmoid函数图
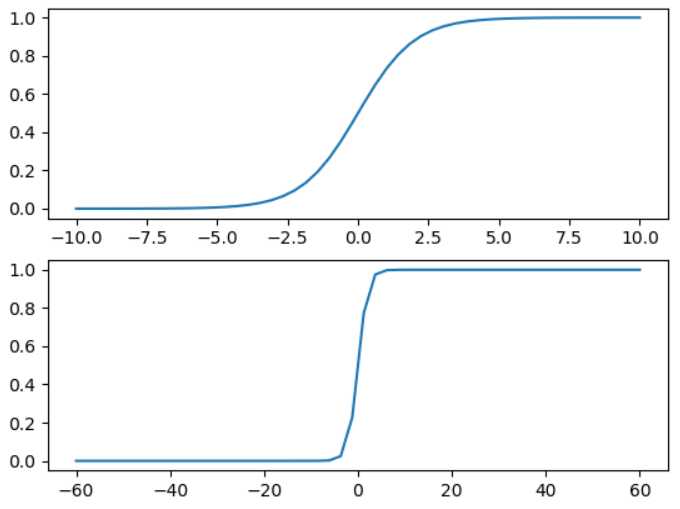
sigmoid函数的输入记为Z = w0x0 + w1x1 + ... + wnxn,采用向量的写法Z=wTx,其中x是分类器的输入数据,向量w就是我们要找到的最佳参数,从而使得分类器尽可能的精确,为了找到最优向量w,下面将使用梯度上升算法实现,在查阅资料时发现了《深入浅出--梯度下降法及其实现》博文,该文章分别对单变量和多变量的梯度下降算法实现进行了详细的推导和说明,在这里非常感谢博主的分享。链接:https://www.jianshu.com/p/c7e642877b0e
(1)需求
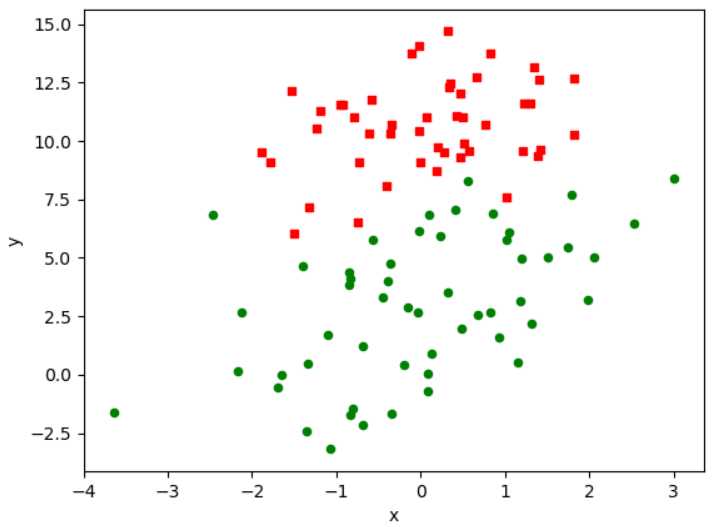
使用梯度上升算法对dataset/testSet.txt文件中的数据集进行算法训练找到最佳参数,数据文件已上传geihub:https://github.com/lizoo6zhi/
数据集如下图:
(2)算法实现
def load_dataset(): """ 获得数据集 """ dataset = [] labels = [] with open(‘dataset/testSet.txt‘,‘r‘) as pf: for line in pf: row_list = line.strip().split() dataset.append([1.0,float(row_list[0]),float(row_list[1])]) #三个特征x0,x1,x2 labels.append(float(row_list[2])) return dataset,labels def sigmoid(t): s = 1.0 / (1+np.exp(-t)) return s def grad_ascent(dataset,labels): """ 回归梯度上升优化算法 """ dataset_matrix = np.mat(dataset) label_matrix = np.mat(labels).transpose() row,col = np.shape(dataset_matrix) weight = np.ones((col,1)) alpha = 0.01 #学习率 max_cycles = 500 for i in range(max_cycles): h = sigmoid(dataset_matrix * weight) error = label_matrix -h #真实值与预测值之间的误差 temp = dataset_matrix.transpose() * error #交叉熵的偏导数 weight = weight + alpha * temp #更新权重 return weight
(3)绘制决策边界
def plot_bestfit(weights): import matplotlib.pyplot as plt dataset,labels = load_dataset() dataset_matrix = np.mat(dataset) rows,cols = np.shape(dataset_matrix) x0 = [] y0 = [] x1 = [] y1 = [] for row in range(rows): if labels[row] == 0: x0.append(dataset_matrix[row,1]) y0.append(dataset_matrix[row,2]) else: x1.append(dataset_matrix[row,1]) y1.append(dataset_matrix[row,2]) fig = plt.figure() ax = fig.add_subplot(111) ax.scatter(x0,y0,s=20,c=‘red‘,marker=‘s‘) ax.scatter(x1,y1,s=20,c=‘green‘) x = np.arange(-3.0,3.0,0.1) y = (-weights[0]-weights[1]*x)/weights[2] ax.plot(x,y) plt.xlabel(‘x‘) plt.ylabel(‘y‘) plt.show()
(4)效果
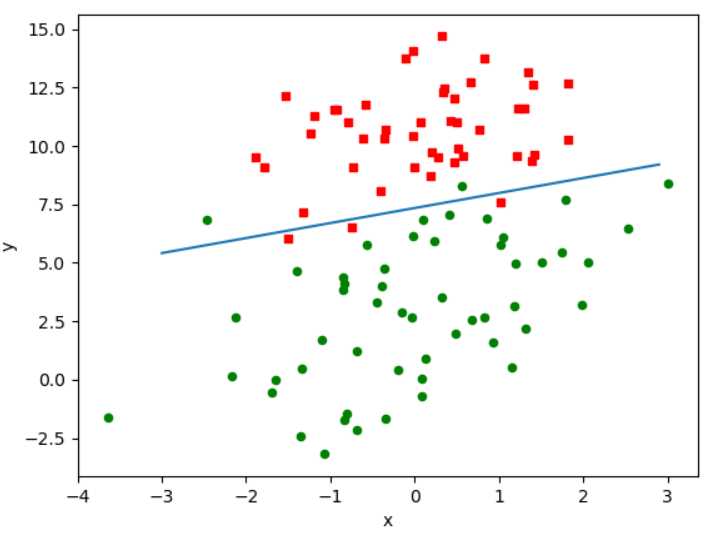
从上图看,分类结果相当不错,只错了个别几个点,但是,尽管数据集很小,但却进行了大量的计算,每次迭代都对整个数据集进行计算,如果有数十亿样本或成千上万的特征,那么该方法的计算复杂度就太高了,一种改进方法是依次仅用一个样本点更新回归系数,也举是随机梯度上升算法,由于可以在新样本到来时对分类器进行增量式更新,因为随机梯度上升算法是一个在线学习算法。
(1)先看修改后的算法实现
def stoc_grad_ascent0(dataset,labels): """ 随机梯度上升算法 """ dataset_matrix = np.array(dataset) row,col = np.shape(dataset_matrix) weights = np.ones(col) alpha = 0.001 for i in range(row): h = sigmoid(sum(dataset_matrix[i]*weights)) error = labels[i] - h weights = weights + alpha*error*dataset_matrix[i] return weights
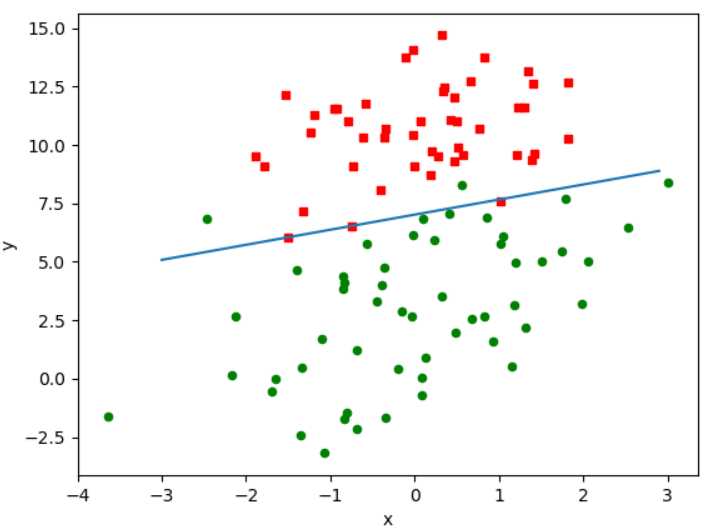
从代码可以看出,每次取数据集中的一个样本对weights进行更新,这样大大减少了计算量,那究竟效果如何呢?
(2)效果图
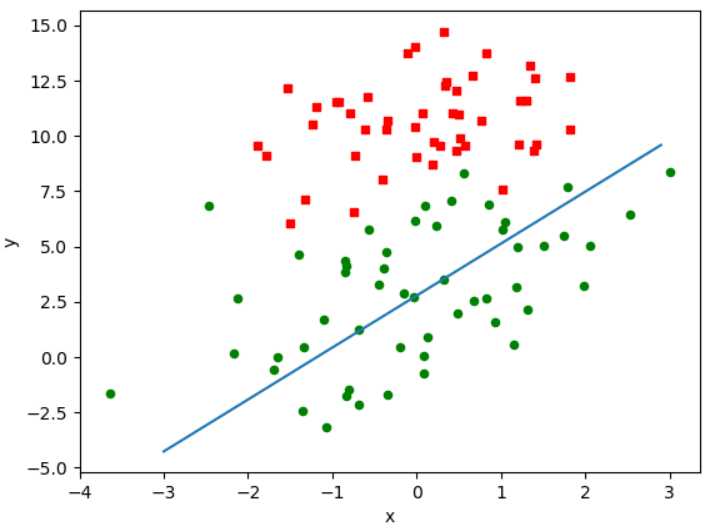
效果有点差,但需要注意,第一次算法中我们迭代了500次,下面我们也迭代500次试试
这样就好多了,一个判断优化算法优劣的可靠方法是看它是否收敛,也就是说参数是否达到稳定值,是否还会不断地变化,接下来我们看看参数随迭代次数的变化的稳定程度
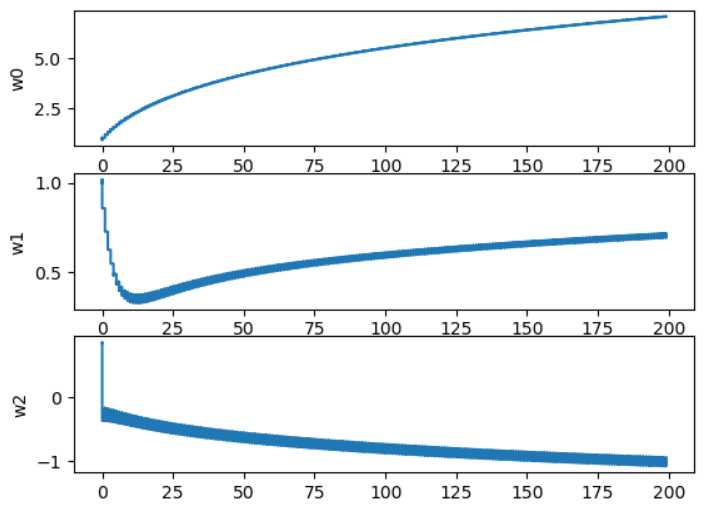
从上图可以看到w2经过150次后达到稳定值,但系数1和0却要经过更多次迭代,另外在每次迭代时会引发系数的剧烈改变(参考5中的图),对算法继续进行优化再看效果
使用样本随机选择和alpha动态减少机制取代固定alpha的方法,代码很简单
def stoc_grad_ascent1(dataset,labels,numiter=150): """ 优化随机梯度上升算法 """ dataset_matrix = np.array(dataset) row,col = np.shape(dataset_matrix) weights = np.ones(col) for j in range(numiter): dataindex = range(row) for i in range(row): alpha = 4 / (1.0+j+i)+0.01 randindex = int(random.uniform(0,len(dataindex))) h = sigmoid(sum(dataset_matrix[randindex]*weights)) error = labels[randindex] - h weights = weights + alpha*error*dataset_matrix[randindex] return weights
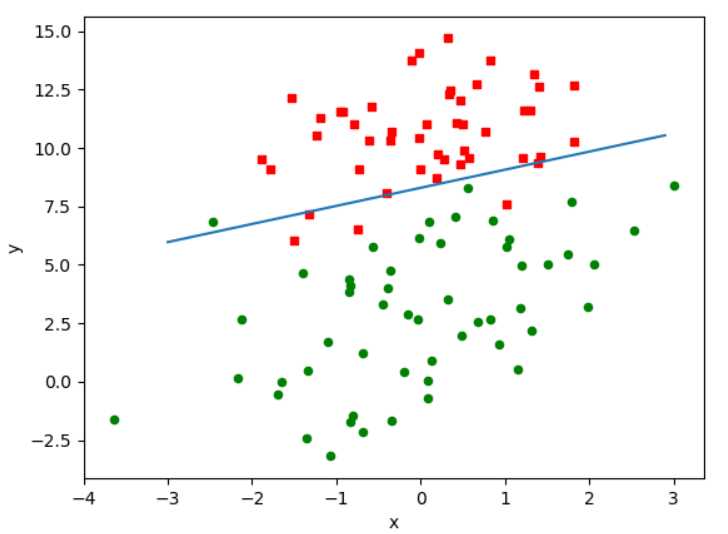
效果1:迭代150次的决策图
效果2:参数随迭代次数的变化的稳定程度
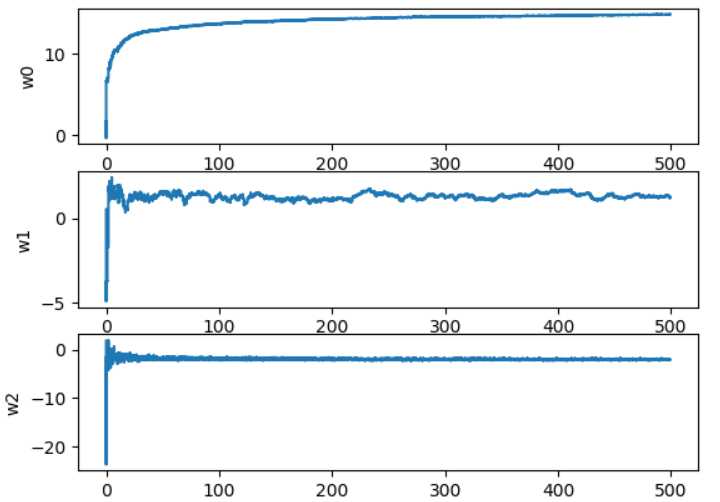
效果就很明显了,使用样本随机选择和alpha动态减少机制比采用固定alpha的方法收敛速度更快
Logistic回归的目的是寻找一个非线性函数Sigmoid的最佳拟合参数,求解过程可以由最优化算法完成,再最优化算法中,最常用的就是梯度上升算法,而梯度上升算法又可以简化为随机梯度上升算法
随机梯度上升算法和梯度上升算法的效果相当,但占用更少的计算资源,此外,随机梯度上升算法是一个在线算法,它可以再新数据到来时就完成参数更新,而不需要重新读取整个数据集来进行批处理运算
标签:都对 1.0 求导 更新 nes atp matrix ret 预测
原文地址:https://www.cnblogs.com/xiaobingqianrui/p/10245433.html