标签:应该 one 输入 compose 有关 python版本 count with open load
https://blog.csdn.net/weixin_39837402/article/details/81054106
【Pytorch】CIFAR-10分类任务
2018年07月16日 16:23:36 theoreoeater 阅读数:505
CIFAR-10数据集共有60000张32*32彩色图片,分为10类,每类有6000张图片。其中50000张用于训练,构成5个训练batch,每一批次10000张图片,其余10000张图片用于测试。

CIFAR-10数据集下载地址:点击下载
数据读取,这里选择下载python版本的数据集,解压后得到如下文件:
其中data_batch_1~data_batch_5为训练集的5个批次,test_batch为测试集。
这些文件是python的序列化模型,这里使用python3,可以使用pickle模块读取这些数据:
-
-
-
with open(file, ‘rb‘) as fo:
-
dict = pickle.load(fo, encoding=‘bytes‘)
-
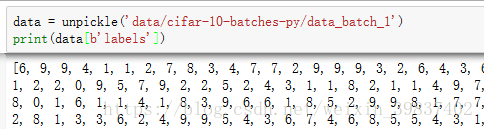
每一个batch文件包括一个字典,字典的元素是:
data:一个尺寸为10000*3072,数据格式为uint8的numpy array,每
一行数据存储了一张32*32彩色图片的数据,前1024位是图像的红色
通道数据,接着是绿色通道和蓝色通道。
label:一个包含10000个0-9数字的列表,对应data里每张图片的标签。

此外,数据集中还有一个batches.meta文件,它保存了一个python字典,
该字典对标签的10个数字0-9所代表的意义做了解释,比如0代表airplane,
1代表automobile。

这次使用Pytorch框架来进行实验,总体流程是,建立网络(这次小demo用Lenet),自定义数据集读取框架,虽然pytorch已经有关于cifar10的Dataset实例,但还是自己实现了一遍,接着用DataLoader分批读取数据集,定义损失函数和优化器,进行批次训练。
-
-
-
from torch.autograd import Variable
-
-
import torch.nn.functional as F
-
import torch.optim as optim
-
import torch.utils.data as Data
-
import torchvision.transforms as transforms
-
-
-
import matplotlib.pyplot as plt
-
-
-
-
-
-
-
-
-
-
super(Lenet,self).__init__()
-
-
-
self.conv1 = nn.Conv2d(3,6,5)
-
self.conv2 = nn.Conv2d(6,16,5)
-
self.fc1 = nn.Linear(16*5*5,120)
-
self.fc2 = nn.Linear(120,84)
-
self.fc3 = nn.Linear(84,10)
-
-
-
def num_flat_features(self,x):
-
-
-
-
-
-
num_features = num_features*s
-
-
-
-
-
-
x = F.max_pool2d(F.relu(self.conv1(x)), 2)
-
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
-
x = x.view(-1, self.num_flat_features(x))
-
-
-
-
-
-
-
-
with open(file, ‘rb‘) as fo:
-
dict = pickle.load(fo, encoding=‘bytes‘)
-
-
-
-
-
-
def get_data(train=False):
-
-
-
-
-
batch = unpickle(‘data/cifar-10-batches-py/data_batch_‘+str(i))
-
-
-
-
data = np.concatenate([data,batch[b‘data‘]])
-
-
-
labels = batch[b‘labels‘]
-
-
labels = np.concatenate([labels,batch[b‘labels‘]])
-
-
batch = unpickle(‘data/cifar-10-batches-py/test_batch‘)
-
-
labels = batch[b‘labels‘]
-
-
-
-
-
transform = transforms.Compose([
-
-
-
-
-
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))
-
-
-
-
-
def target_transform(label):
-
-
target = torch.from_numpy(label).long()
-
-
-
-
-
-
-
class Cifar10_Dataset(Data.Dataset):
-
def __init__(self,train=True,transform=None,target_transform=None):
-
-
self.transform = transform
-
self.target_transform = target_transform
-
-
-
-
self.train_data,self.train_labels = get_data(train)
-
self.train_data = self.train_data.reshape((50000, 3, 32, 32))
-
-
self.train_data = self.train_data.transpose((0, 2, 3, 1))
-
-
-
self.test_data,self.test_labels = get_data()
-
self.test_data = self.test_data.reshape((10000, 3, 32, 32))
-
self.test_data = self.test_data.transpose((0, 2, 3, 1))
-
-
def __getitem__(self, index):
-
-
-
-
img, label = self.train_data[index], self.train_labels[index]
-
-
img, label = self.test_data[index], self.test_labels[index]
-
-
img = Image.fromarray(img)
-
-
if self.transform is not None:
-
img = self.transform(img)
-
-
if self.target_transform is not None:
-
target = self.target_transform(label)
-
-
-
-
-
-
return len(self.train_data)
-
-
return len(self.test_data)
-
-
if __name__ == ‘__main__‘:
-
-
train_data = Cifar10_Dataset(True,transform,target_transform)
-
print(‘size of train_data:{}‘.format(train_data.__len__()))
-
test_data = Cifar10_Dataset(False,transform,target_transform)
-
print(‘size of test_data:{}‘.format(test_data.__len__()))
-
train_loader = Data.DataLoader(dataset=train_data, batch_size = BATCH_SIZE, shuffle=True)
-
-
-
optimizer = optim.Adam(net.parameters(), lr = 0.001, betas=(0.9, 0.99))
-
-
loss_fn = nn.CrossEntropyLoss()
-
-
-
for epoch in range(1,EPOCH+1):
-
-
for step,(x,y) in enumerate(train_loader):
-
-
-
-
loss = loss_fn(output,b_y)
-
-
-
-
-
-
-
-
-
test_loader = Data.DataLoader(dataset=test_data, batch_size = 100, shuffle=True)
-
for (x,y) in (test_loader):
-
-
-
-
pre = torch.max(output,1)[1]
-
pre_correct = pre_correct+float(torch.sum(pre==b_y))
-
-
print(‘EPOCH:{epoch},ACC:{acc}%‘.format(epoch=epoch,acc=(pre_correct/float(10000))*100))
-
-
-
torch.save(net,‘lenet_cifar_10.model‘)
-
-
-
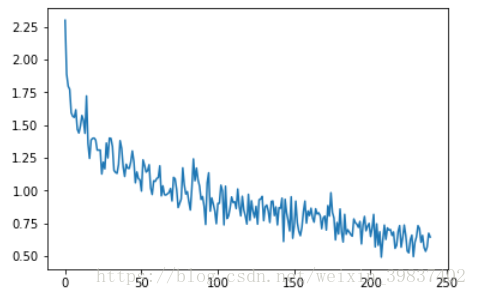
第一个pytorch demo跑通了,但是训练模型效果很不好,应该是Lenet作用于Cifar10有些过于力不从心了,刚开始接触深度学习的图像领域还不怎么懂,下次换一个更强大的网络。

【Pytorch】CIFAR-10分类任务
标签:应该 one 输入 compose 有关 python版本 count with open load
原文地址:https://www.cnblogs.com/shuimuqingyang/p/10249711.html