标签:想法 图片 cli 路径 10.10 描述 衡量标准 arraylist site
本人微信公众号,欢迎扫码关注!


1)客户端向namenode请求上传文件,namenode检查目标文件是否已存在,父目录是否存在。
2)namenode返回是否可以上传。
3)客户端请求第一个 block上传到哪几个datanode服务器上。
4)namenode返回3个datanode节点,分别为dn1、dn2、dn3。
5)客户端请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成
6)dn1、dn2、dn3逐级应答客户端
7)客户端开始往dn1上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,dn1收到一个packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答
8)当一个block传输完成之后,客户端再次请求namenode上传第二个block的服务器。(重复执行3-7步)
在本地网络中,两个节点被称为“彼此近邻”是什么意思?在海量数据处理中,其主要限制因素是节点之间数据的传输速率——带宽很稀缺。这里的想法是将两个节点间的带宽作为距离的衡量标准。
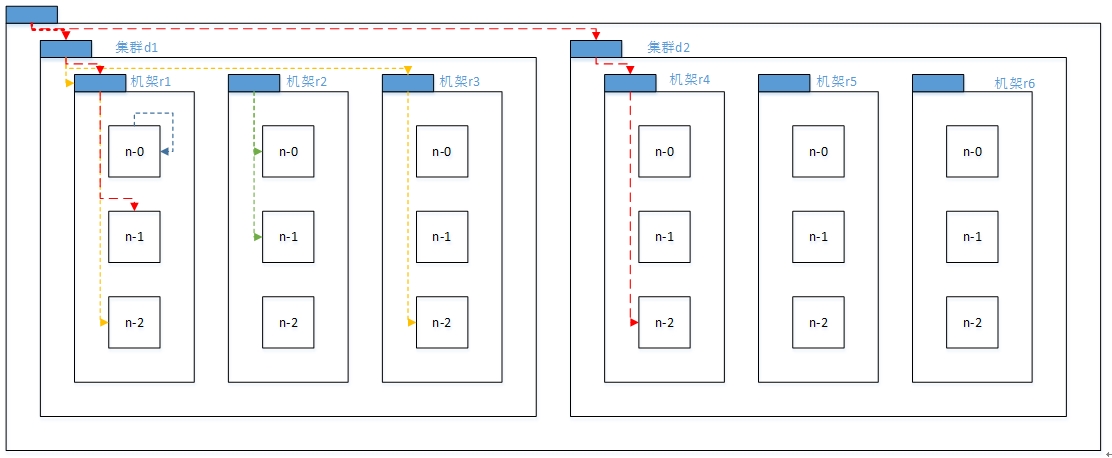
节点距离:两个节点到达最近的共同祖先的距离总和。
例如,假设有数据中心d1机架r1中的节点n1。该节点可以表示为/d1/r1/n1。利用这种标记,这里给出四种距离描述。
Distance(/d1/r1/n1, /d1/r1/n1)=0(同一节点上的进程)
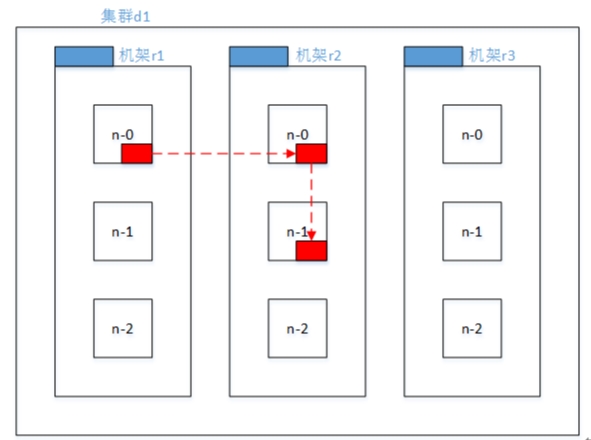
Distance(/d1/r1/n1, /d1/r1/n2)=2(同一机架上的不同节点)
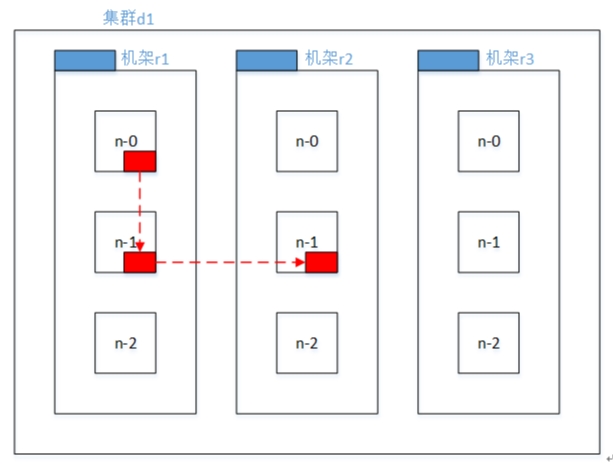
Distance(/d1/r1/n1, /d1/r3/n2)=4(同一数据中心不同机架上的节点)
Distance(/d1/r1/n1, /d2/r4/n2)=6(不同数据中心的节点)http://hadoop.apache.org/docs/r2.7.3/hadoop-project-dist/hadoop-common/RackAwareness.html
(0)环境准备
(a)数据节点的量
[rack1]:hadoop102、hadoop103
[rack2]:hadoop104、hadoop105
(b)增加一个数据节点
(1)克隆一个节点
(2)启动新节点
(3)修改克隆的ip和主机名
(4)在hadoop102上ssh到新节点
(5)修改xsync.sh和xcall.sh文件
(6)修改hadoop102 slaves文件,再分发
(1)创建类实现DNSToSwitchMapping接口
public class MyDNSToSwichMapping implements DNSToSwitchMapping {
// 传递的是客户端的ip列表,返回机架感知的路径列表
public List<String> resolve(List<String> names) {
ArrayList<String> lists = new ArrayList<String>();
if (names != null && names.size() > 0) {
for (String name : names) {
int ip = 0;
// 获取ip地址
if (name.startsWith("hadoop")) {
String no = name.substring(6);
// hadoop102
ip = Integer.parseInt(no);
} else if (name.startsWith("192")) {
// 192.168.10.102
ip = Integer.parseInt(name.substring(name.lastIndexOf(".") + 1));
}
// 定义机架
if (ip < 104) {
lists.add("/rack1/" + ip);
} else {
lists.add("/rack2/" + ip);
}
}
}
// 把ip地址打印出来
try {
FileOutputStream fos = new FileOutputStream("/home/atguigu/name.txt");
for (String name : lists) {
fos.write((name + "\r\n").getBytes());
}
fos.close();
} catch (Exception e) {
e.printStackTrace();
}
return lists;
}
public void reloadCachedMappings() {
}
public void reloadCachedMappings(List<String> names) {
}
}(2)配置core-site.xml
默认的:
<!-- Topology Configuration -->
<property>
<name>net.topology.node.switch.mapping.impl</name>
<value>org.apache.hadoop.net.ScriptBasedMapping</value>
</property>配置后的
<!-- Topology Configuration -->
<property>
<name>net.topology.node.switch.mapping.impl</name>
<value>com.atguigu.hdfs.MyDNSToSwichMapping</value>
</property>(3)分发core-site.xml
xsync /opt/module/hadoop-2.7.2/etc/hadoop/core-site.xml(4)编译程序,打成jar,分发到所有节点的hadoop的classpath下
cd /opt/module/hadoop-2.7.2/share/hadoop/common/lib
xsync MyDNSSwitchToMapping.jar(5)重新启动集群
(6)在名称节点hadoop103主机上查看名称
(7)查看结果
(1)在hadoop105节点上传文件到hdfs文件系统,查看复本存放位置
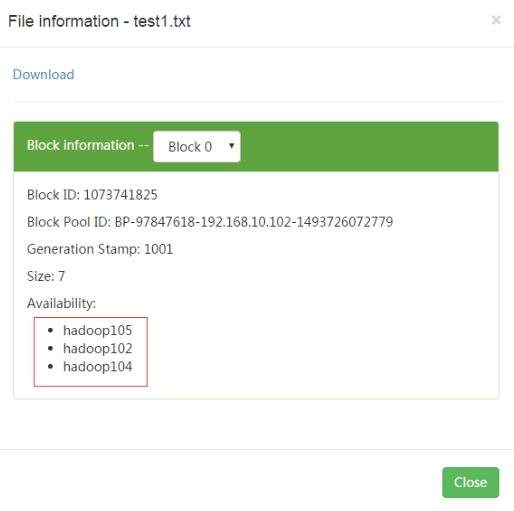
(2)在hadoop102节点上传文件到hdfs文件系统,查看复本存放位置
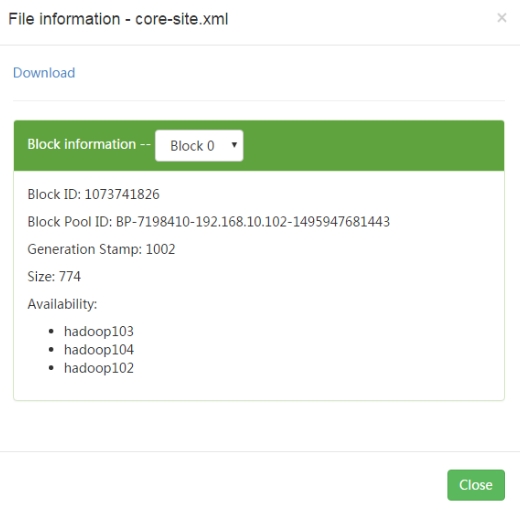
(3)结论
第一个副本在client所处的节点上。如果客户端在集群外,随机选一个。
第二个副本和第一个副本位于相同机架,随机节点。
第三个副本位于不同机架,随机节点。
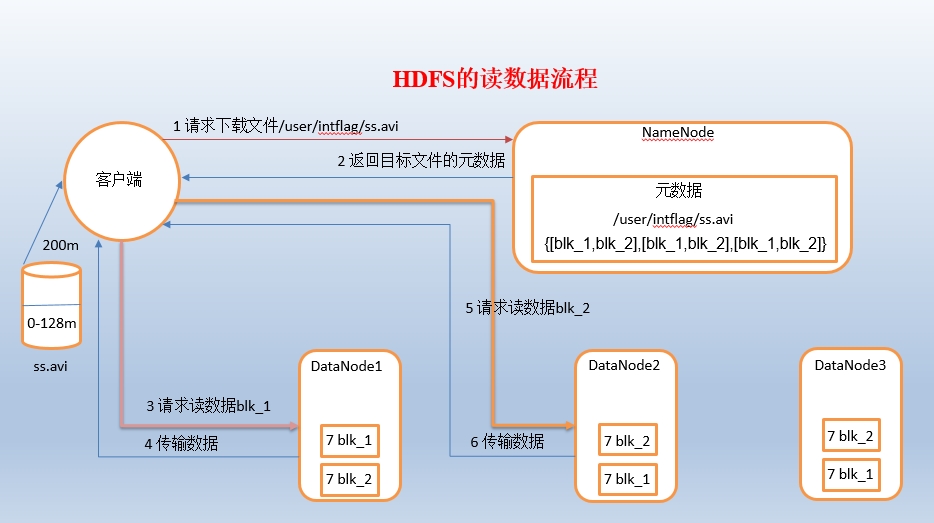
1)客户端向namenode请求下载文件,namenode通过查询元数据,找到文件块所在的datanode地址。
2)挑选一台datanode(就近原则,然后随机)服务器,请求读取数据。
3)datanode开始传输数据给客户端(从磁盘里面读取数据放入流,以packet为单位来做校验)。
4)客户端以packet为单位接收,先在本地缓存,然后写入目标文件。
@Test
public void writeFile() throws Exception{
// 1 创建配置信息对象
Configuration configuration = new Configuration();
fs = FileSystem.get(configuration);
// 2 创建文件输出流
Path path = new Path("hdfs://hadoop102:8020/user/atguigu/hello.txt");
FSDataOutputStream fos = fs.create(path);
// 3 写数据
fos.write("hello".getBytes());
// fos.flush();
fos.hflush();
//
// fos.write("welcome to atguigu".getBytes());
// fos.hsync();
fos.close();
}标签:想法 图片 cli 路径 10.10 描述 衡量标准 arraylist site
原文地址:https://www.cnblogs.com/intflag/p/10251702.html