标签:不同 add 解决 div sync 原理 href switch 主备
上一篇我们已经介绍了Redis的主从复制,传送门:《Redis高可用之主从复制实践(四)》,想必大家对redis已经有一个概念了,那么问题来了,如果redis主从复制的master服务器挂掉了,那么整体redis就崩溃了,因为master无法进行写数据,导致slave中无法更新数据。
那么为了解决这个问题我们就需要有一种方案让redis宕机后可以自动进行故障转移,还好redis给我们提供一种高可用解决方案 Redis-Sentinel。Redis-sentinel本身也是一个独立运行的进程,它能监控多个master-slave集群,发现master宕机后能进行自动切换。Sentinel可以监视任意多个主服务器
以及主服务器属下的从服务器,并在被监视的主服务器下线时,自动执行故障转移操作。
既然有这么好的解决方案,那么我们就来看看如何在我们的服务器上进行配置
1、环境配置
第一:准备3台服务器,此处我的sentinel就直接放在原先的服务器上
| 主机说明 | 主机IP | 端口 | sentinel端口 |
| master |
192.168.250.132
|
7000 |
26379 |
| slave | 192.168.250.133 | 7001 | 26380 |
| slave |
192.168.250.134 |
7002
|
26381 |
此处要说明一个问题,我这边的sentinel采用的是集群部署的方式,而不是单点,想必大家也知道单点会存在很多的问题,比如:
1):当sentinel进程宕掉后(sentinel本身也有单点问题,single-point-of-failure)整个集群系统将无法按照预期的方式运行;
2):如果只有一个sentinel进程,如果这个进程运行出错,或者是网络堵塞,那么将无法实现redis集群的主备切换(单点问题)。
如果有多个sentinel,redis的客户端可以随意地连接任意一个sentinel来获得关于redis集群中的信息;即使有一些sentinel进程宕掉了,依然可以进行redis集群的主备切换;
2、创建sentinel配置文件
进入 132 服务器的redis文件夹下,我们创建一个文件名为 sentinel-26379.conf 配置文件,文件内容如下:
port 26379
daemonize yes
logfile "26379.log"
dir "./"
sentinel monitor mymaster 192.168.250.132 7000 2
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 15000
sentinel auth-pass mymaster 123
bind 192.168.250.132 127.0.0.1
那么133与134服务器下的redis文件夹中我们也创建相同的sentinel 配置文件,但主要修改一下端口26380/26381以及bin绑定的数据。
看到这里大家因为会对上面的配置有些疑惑,那我分别介绍一下参数的含义:
像 port、daemonize、logfile、dir、bind 这些我就不介绍了,之前也介绍过了,这边重点介绍一下sentinel的配置
sentinel monitor <master-name> <ip> <redis-port> <quorum>
告诉sentinel去监听地址为ip:port的一个master,这里的master-name可以自定义,quorum是一个数字,指明当有多少个sentinel认为一个master失效时,master才算真正失效
sentinel auth-pass <master-name> <password>
设置连接master和slave时的密码,注意的是sentinel不能分别为master和slave设置不同的密码,因此master和slave的密码应该设置相同。
sentinel down-after-milliseconds <master-name> <milliseconds>
这个配置项指定了需要多少失效时间,一个master才会被这个sentinel主观地认为是不可用的。 单位是毫秒,默认为30秒
sentinel parallel-syncs <master-name> <numslaves>
这个配置项指定了在发生failover主备切换时最多可以有多少个slave同时对新的master进行 同步,这个数字越小,完成failover所需的时间就越长,但是如果这个数字越大,就意味着越 多的slave因为replication而不可用。可以通过将这个值设为 1 来保证每次只有一个slave 处于不能处理命令请求的状态。
sentinel failover-timeout <master-name> <milliseconds>
failover-timeout 可以用在以下这些方面:
1. 同一个sentinel对同一个master两次failover之间的间隔时间。
2. 当一个slave从一个错误的master那里同步数据开始计算时间。直到slave被纠正为向正确的master那里同步数据时。
3.当想要取消一个正在进行的failover所需要的时间。
4.当进行failover时,配置所有slaves指向新的master所需的最大时间。不过,即使过了这个超时,slaves依然会被正确配置为指向master,但是就不按parallel-syncs所配置的规则来了。
配图如下:

这样子大家也能明白,那么接下来我们就要开始启动我们的sentinel啦,当然前提大家要先把redis主从复制开启。
sentinel 运行命令如下:
./src/redis-sentinel sentinel-26379.conf
./src/redis-sentinel sentinel-26380.conf
./src/redis-sentinel sentinel-26381.conf
运行完后我们再来看看sentinel-263779.conf的配置,发现配置文件被重写了,从内容可以看出有哪些slave和sentinel
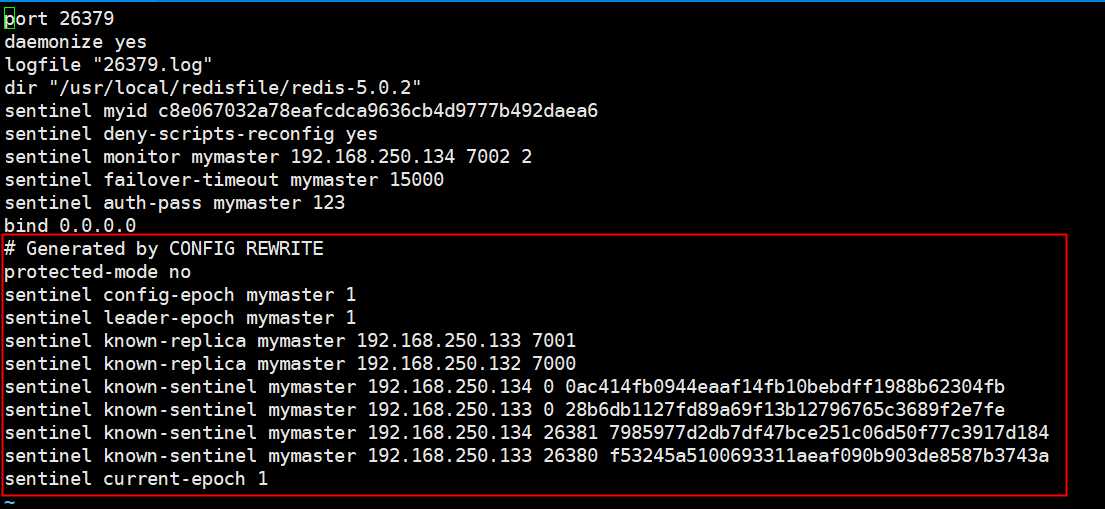
内容已经配置完毕,现在我们进行一下故障转移吧,
3、故障转移
我们关闭master主节点,当然我演示的项目中master服务器是134,因为我之前有测试过,因此大家在操作的时候可以按照自己机器上的为主。
第一步:我们关闭134的redis,等待一会,我们再查看一下sentinel的日志。我们通过日志来分析一下自动故障转移的流程
=======================134master发现不能用
40325:X 09 Jan 2019 16:46:09.920 # +sdown master mymaster 192.168.250.134 7002
=======================投票后有两个sentinel发现master不能用
40325:X 09 Jan 2019 16:46:10.005 # +odown master mymaster 192.168.250.134 7002 #quorum 2/2
=======================当前配置版本被更新
40325:X 09 Jan 2019 16:46:10.005 # +new-epoch 2
=======================达到故障转移failover条件,正等待其他sentinel的选举
40325:X 09 Jan 2019 16:46:10.005 # +try-failover master mymaster 192.168.250.134 7002
=======================进行投票选举slave服务器
40325:X 09 Jan 2019 16:46:10.006 # +vote-for-leader 7985977d2db7df47bce251c06d50f77c3917d184 2
40325:X 09 Jan 2019 16:46:10.007 # f53245a5100693311aeaf090b903de8587b3743a voted for 7985977d2db7df47bce251c06d50f77c3917d184 2
40325:X 09 Jan 2019 16:46:10.008 # c8e067032a78eafcdca9636cb4d9777b492daea6 voted for 7985977d2db7df47bce251c06d50f77c3917d184 2
40325:X 09 Jan 2019 16:46:10.077 # +elected-leader master mymaster 192.168.250.134 7002
40325:X 09 Jan 2019 16:46:10.077 # +failover-state-select-slave master mymaster 192.168.250.134 7002
=======================选择一个slave当选新的master
40325:X 09 Jan 2019 16:46:10.178 # +selected-slave slave 192.168.250.132:7000 192.168.250.132 7000 @ mymaster 192.168.250.134 7002
=======================把选举出来的slave进行身份master切换
40325:X 09 Jan 2019 16:46:10.178 * +failover-state-send-slaveof-noone slave 192.168.250.132:7000 192.168.250.132 7000 @ mymaster 192.168.250.134 7002
40325:X 09 Jan 2019 16:46:10.241 * +failover-state-wait-promotion slave 192.168.250.132:7000 192.168.250.132 7000 @ mymaster 192.168.250.134 7002
40325:X 09 Jan 2019 16:46:10.393 # +promoted-slave slave 192.168.250.132:7000 192.168.250.132 7000 @ mymaster 192.168.250.134 7002
=======================把故障转移failover改变reconf-slaves
40325:X 09 Jan 2019 16:46:10.393 # +failover-state-reconf-slaves master mymaster 192.168.250.134 7002
=======================sentinel发送slaveof命令把133重新同步132master
40325:X 09 Jan 2019 16:46:10.448 * +slave-reconf-sent slave 192.168.250.133:7001 192.168.250.133 7001 @ mymaster 192.168.250.134 7002
=======================重写rewrite master地址到sentinel配置文件中
40325:X 09 Jan 2019 16:46:10.738 * +sentinel-address-switch master mymaster 192.168.250.134 7002 ip 192.168.250.132 port 26379 for c8e067032a78eafcdca9636cb4d9777b492daea6
40325:X 09 Jan 2019 16:46:10.907 * +sentinel-address-switch master mymaster 192.168.250.134 7002 ip 192.168.250.138 port 26379 for c8e067032a78eafcdca9636cb4d9777b492daea6
=======================离开不可用的master
40325:X 09 Jan 2019 16:46:11.135 # -odown master mymaster 192.168.250.134 7002
=======================slave被重新配置为另外一个master的slave,但数据还未发生
40325:X 09 Jan 2019 16:46:11.407 * +slave-reconf-inprog slave 192.168.250.133:7001 192.168.250.133 7001 @ mymaster 192.168.250.134 7002
=======================与master进行数据同步
40325:X 09 Jan 2019 16:46:11.407 * +slave-reconf-done slave 192.168.250.133:7001 192.168.250.133 7001 @ mymaster 192.168.250.134 7002
=======================故障转移完成
40325:X 09 Jan 2019 16:46:11.508 # +failover-end master mymaster 192.168.250.134 7002
=======================master地址发生改变
40325:X 09 Jan 2019 16:46:11.508 # +switch-master mymaster 192.168.250.134 7002 192.168.250.132 7000
=======================检测slave并添加到slave列表
40325:X 09 Jan 2019 16:46:11.508 * +slave slave 192.168.250.133:7001 192.168.250.133 7001 @ mymaster 192.168.250.132 7000
40325:X 09 Jan 2019 16:46:11.508 * +slave slave 192.168.250.134:7002 192.168.250.134 7002 @ mymaster 192.168.250.132 7000
40325:X 09 Jan 2019 16:46:12.475 * +sentinel-address-switch master mymaster 192.168.250.132 7000 ip 192.168.250.132 port 26379 for c8e067032a78eafcdca9636cb4d9777b492daea
自此故障转移完成,我们查看一下132,现在132已经变成master了,并且 133和134变为了slave。
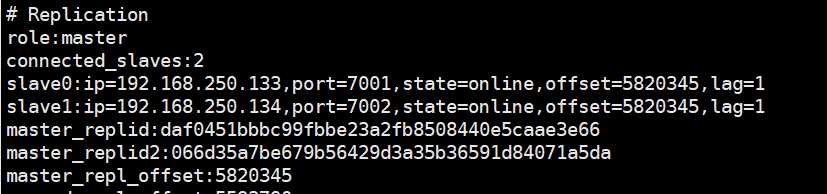
我们再来对比一下 sentinel-26379.conf的配置文件数据,发现已经修改了。自此failover完成。
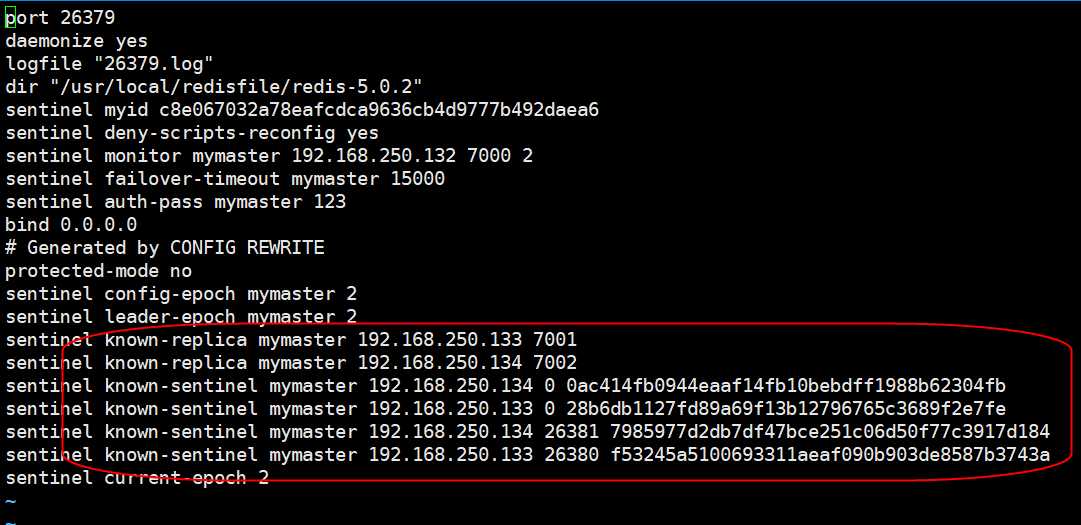
redis的高可用已经讲解了两大部分了,剩余的集群部署将是我们的最后的步骤,也是关键的。下一篇将会开启集群的配置。
如果上述有问题,欢迎大家指教。
参考文章:
《Redis及其Sentinel配置项详细说明》:https://blog.csdn.net/a1282379904/article/details/52335051
《Redis 复制、Sentinel的搭建和原理说明》:https://www.cnblogs.com/zhoujinyi/p/5570024.html
《Redis Sentinel高可用架构》:https://www.cnblogs.com/gomysql/p/5040847.html
asp.net core 交流群:787464275 欢迎加群交流
如果您认为这篇文章还不错或者有所收获,您可以点击右下角的【推荐】按钮精神支持,因为这种支持是我继续写作,分享的最大动力!
微信公众号:欢迎关注 QQ技术交流群: 欢迎加群


标签:不同 add 解决 div sync 原理 href switch 主备
原文地址:https://www.cnblogs.com/guolianyu/p/10249687.html