标签:height image 优缺点 drop 需要 迭代 改变 导数 16px
主要内容:
一、dropout正则化的思想
二、dropout算法流程
三、dropout的优缺点
一、dropout正则化的思想
在神经网络中,dropout是一种“玄学”的正则化方法,以减少过拟合的现象。它的主要思想就是:在训练神经网络的每一轮迭代中,随机地关闭一些神经元,以此降低神经网络的复杂程度:
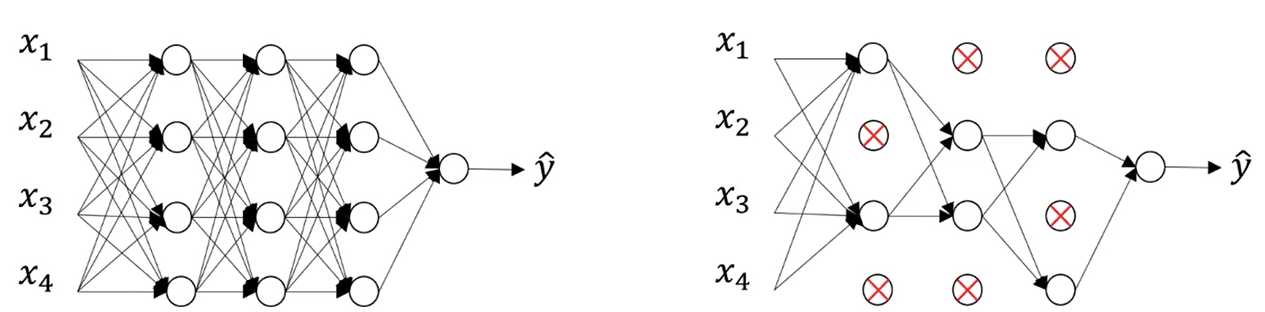
二、dropout算法流程
1)对于第k层的结点,选择一个范围在(0,1]的数keep_prob,表明每一个结点的存在几率为keep_prob
2)在每一轮迭代中,为第k层的所有结点随机分配一个范围在[0,1]的数D。如果某个结点的D小于等于keep_prob,那么这个结点在此轮迭代中能保存;否则,这个结点将在这轮迭代中被暂时删去,所谓删去,其实就是将该节点在这轮前向传播的输出值设为0。
3)对于保存下来的点,还需要做一步操作:新输出值 = 原输出值/keep_prob。
问:为何输出值要除以keep_prob呢?
答:因为这样能保证第k层输出的期望不发生改变,或者说是保持第k层输出值的scale。
4)以上是前向传播的过程,在反向传播中,同样需要对保留下来的结点的导数dA除以keep_prob。
5)每一层的keep_prob可以不一样,其中输入层X一般不进行dropout,结点数大的隐藏层其keep_prob可以小一点以降低其复杂度。
三、dropout的优缺点
优点:使用dropout正则化的神经网络,不会过分依赖于某个或某些特征,使得权重分散。因为在每一轮迭代中隐藏层的任何一个结点都有可能被删除,那么原本属于它的权重就会被分配到其他结点上,多次迭代平均下来,就能降低对某个特征或者是某个结点的依赖了。
缺点:损失函数在每一轮迭代中不一定是逐渐减小,因为此时的损失函数没有明确的定义。(这个不理解)
标签:height image 优缺点 drop 需要 迭代 改变 导数 16px
原文地址:https://www.cnblogs.com/DOLFAMINGO/p/10252698.html