标签:base 收集 com 运行 logs park 分布式协调 process mapred
数据的处理流程: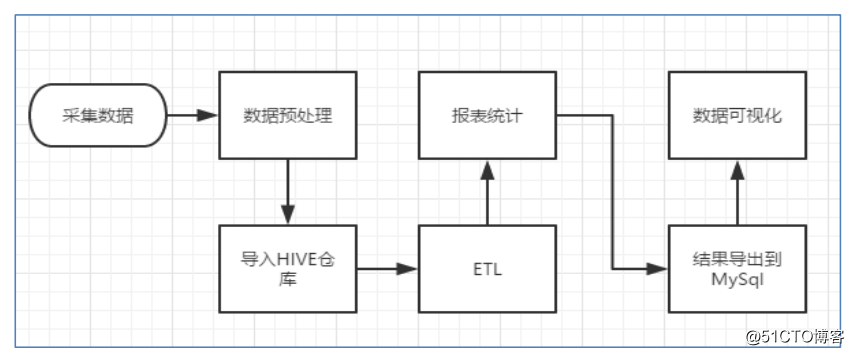
A、数据采集:定制开发采集程序,或使用开源框架 Flume 或者 LogStash
B、数据预处理:定制开发 MapReduce 程序运行于 Hadoop 集群,或者专门数据收集工具也能进行数据预处理
C、数据仓库技术:基于 Hadoop 之上的 Hive
D、数据导出:基于 Hadoop 的 Sqoop 数据导入导出工具
E、数据可视化:定制开发 web 程序或使用 Kettle 等产品
F、数据统计分析:Hadoop 中的 MapReduce 或者基于 Hadoop 的 Hive,或者 Spark,Flink
G、整个过程的流程调度:Hadoop 生态圈中的 Oozie/Azkaban 工具或其他类似开源产品
标签:base 收集 com 运行 logs park 分布式协调 process mapred
原文地址:http://blog.51cto.com/14048416/2341495