标签:css hup csv文件 controls facet support tooltip sky 问题
| 格式类型 | 数据描述 | Reader | Writer |
|---|---|---|---|
| text | CSV | read_ csv | to_csv |
| text | JSON | read_json | to_json |
| text | HTML | read_html | to_html |
| text | clipboard | read_clipboard | to_clipboard |
| binary | Excel | read_excel | to_excel |
| binary | HDF5 | read_hdf | to_hdf |
| binary | Feather | read_feather | to_feather |
| binary | Msgpack | read_msgpack | to_msgpack |
| binary | Stata | read_stata | to_stata |
| binary | SAS | read_sas | |
| binary | Python Pickle | read_pickle | to_pickle |
| SQL | SQL | read_sql | to_sql |
| SQLGoogle | Big Query | read_gbq | to_gbq |
文件读取
- 1.read_csv
- 2.read_excel
文件保存
- 1.to_csv
- 2.to_excel
- 3.to_sql
from io import StringIO
import pandas as pd
读取 csv 文件算是一种最常见的操作了。假如已经有人将一些用户的信息记录在了一个csv文件中,我们如何通过 Pandas 读取呢?
读取之前先来看下这个文件里的内容吧。
data = pd.read_csv(‘../friends.csv‘,encoding=‘utf-8‘,index_col=‘NickName‘)
data.head()
可以看到,读取出来生成了一个 DataFrame,索引是自动创建的一个数字,我们可以设置参数 index_col 来将某列设置为索引,可以传入索引号或者名称。
"""
除了可以从文件中读取,我们还可以从 StringIO 对象中读取。
"""
data="name,age,birth,sex\nTom,18.0,2000-02-10,\nBob,30.0,1988-10-17,male"
print(data)
df = pd.read_csv(StringIO(data))
df
data = "name|age|birth|sex~Tom|18.0|2000-02-10|~Bob|30.0|1988-10-17|male"
df = pd.read_csv(StringIO(data), sep="|", lineterminator="~")
df
df = pd.read_csv(StringIO(data), sep="|", lineterminator="~", dtype={"age": int})
df
data="Tom,18.0,2000-02-10,\nBob,30.0,1988-10-17,male"
print(data)
df = pd.read_csv(StringIO(data), names=["name", "age", "birth", "sex"])
df
data="name,age,birth,sex\nTom,18.0,2000-02-10,\nBob,30.0,1988-10-17,male"
print(data)
df = pd.read_csv(StringIO(data), usecols=["name", "age"])
df
print(pd.read_csv(StringIO(data)))
df = pd.read_csv(StringIO(data), keep_default_na=False)
df
df = pd.read_csv(StringIO(data), na_values=[18])
df
通常在得到了 DataFrame 之后,有时候我们需要将它转为一个 json 字符串,可以使用 to_json 来完成。 转换时,可以通过指定参数 orient 来输出不同格式的格式,之后以下几个参数:
- split 字典像索引 - > [索引],列 - > [列],数据 - > [值]}
- records 列表像{[列 - >值},…,{列 - >值}]
- index 字典像{索引 - > {列 - >值}}
- columns 字典像{列 - > {索引 - >值}}
- values 只是值数组
DataFrame 默认情况下使用 columns 这种形式,Series 默认情况下使用 index 这种形式。
- 设置为 columns 后会将数据作为嵌套JSON对象进行序列化,并将列标签作为主索引。
- 设置为index 后会将数据作为嵌套JSON对象进行序列化,并将索引标签作为主索引。
- 设置为 records 后会将数据序列化为列 - >值记录的JSON数组,不包括索引标签。
- 设置为 values 后会将是一个仅用于嵌套JSON数组值,不包含列和索引标签。
- 设置为 split 后会将序列化为包含值,索引和列的单独条目的JSON对象。
df = pd.read_csv("../friends.csv", index_col="NickName").head()
print(df)
df.to_json()
print(df.to_json(orient="index"))
print(df.to_json(orient="records"))
print(df.to_json(orient="values"))
print(df.to_json(orient="split"))
df = pd.read_excel(‘data/adverse_reaction_database.xlsx‘)
df.head()
数据我就按比较常见的列表嵌套字典来演示了,这种数据结构也是在各个场景下经常用到的数据结构[{},{},{}…]
import pandas as pd
data = [
{"name":"张三","age":18,"city":"北京"},
{"name":"李四","age":19,"city":"上海"},
{"name":"王五","age":20,"city":"广州"},
{"name":"赵六","age":21,"city":"深圳"},
{"name":"孙七","age":22,"city":"武汉"}
]
df = pd.DataFrame(data,columns=["name","age","city"])
df
df.to_csv("data/csv_file.csv",encoding="utf-8",index=False)
df
注意事项:
- 1、一般情况下我们用utf-8编码进行保存,如果出现中文编码错误,则可以依次换用gbk,gb2312 , gb18030,一般总能成功的,本例中用utf-8
- 2、to_csv方法,具体参数还有很多,可以去看官方文档,这里提到一个index = False参数,表示保存csv的时候,我们不保存pandas 的Data frame的行索引1234这样的序号,默认情况不加的话是index = True,会有行号(如下图),这点在保存数据库mysql的时候体现尤其明显,不注意的话可能会出错
df.to_csv("data/csv_file.csv",encoding="utf-8")
df
writer = pd.ExcelWriter(‘data/excel.xlsx‘)
df.to_excel(writer, sheet_name=‘user‘, index=False)
writer.save()

from sqlalchemy import create_engine
table_name = "user"
engine = create_engine(
"mysql+pymysql://root:0000@127.0.0.1:3306/db_test?charset=utf8",
max_overflow=0, # 超过连接池大小外最多创建的连接
pool_size=5, # 连接池大小
pool_timeout=30, # 池中没有线程最多等待的时间,否则报错
pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置)
)
conn = engine.connect()
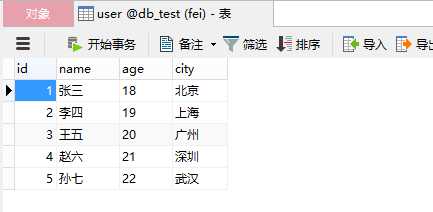
df.to_sql(table_name, conn, if_exists=‘append‘,index=False)

注意事项:
1、我们用的库是sqlalchemy,官方文档提到to_sql是被sqlalchemy支持
文档地址:
http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.to_sql.html
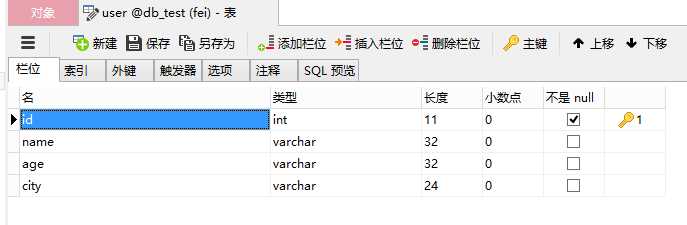
2、数据库配置用你自己的数据库配置,db_flag为数据库类型,根据不同情况更改,在保存数据之前,要先创建数据库字段,下图是我这边简单创建的字段
3、engine_config为数据库连接配置信息
4、create_engine是根据数据库配置信息创建连接对象
5、if_exists = ‘append‘,追加数据
6、index = False 保存时候,不保存df的行索引,这样刚好df的3个列和数据库的3个字段一一对应,正常保存,如果不设置为false的话,数据相当于4列,跟MySQL 3列对不上号,会报错
- 这里提个小问题,比如我们想在遍历的时候来一条数据,保存一条,而不是整体生成Dataframe后才保存,该怎么做?上面提到if_exists,可以追加,用这个即可实现,包括保存csv同样也有此参数,可以参考官方文档
标签:css hup csv文件 controls facet support tooltip sky 问题
原文地址:https://www.cnblogs.com/zhangyafei/p/10257379.html