标签:setting enabled 情况下 not 分布 oid decide ctr 代码
本文记录ElasticSearch创建索引执行源码流程。从执行流程角度看一下创建索引会涉及到哪些服务(比如AllocationService、MasterService),由于本人对分布式系统理解不是很深,所以很多一些细节原理也是不懂。
curl -X PUT "localhost:9200/twitter"
ElasticSearch服务器端收到Client的创建索引请求后,是从org.elasticsearch.action.admin.indices.create.TransportCreateIndexAction开始执行索引创建流程的。
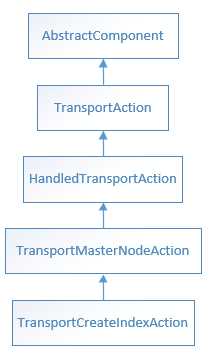
创建索引是需要ElasticSearch Master节点参与的,因此TransportCreateIndexAction继承了TransportMasterNodeAction,而创建索引的具体操作由实例属性MetaDataCreateIndexService完成。
/**
* Create index action.
*/
public class TransportCreateIndexAction extends TransportMasterNodeAction<CreateIndexRequest, CreateIndexResponse> {
//
private final MetaDataCreateIndexService createIndexService;在MetaDataCreateIndexService.createIndex(...)调用onlyCreateIndex方法执行创建索引操作。
public void createIndex(...)
{
onlyCreateIndex(request, ActionListener.wrap(response -> {
if (response.isAcknowledged()) {
activeShardsObserver.waitForActiveShards
}Creates an index in the cluster state and waits for the specified number of shard copies to become active as specified in CreateIndexClusterStateUpdateRequest#waitForActiveShards()before sending the response on the listener.
创建索引需要检查 Active shards,默认情况下:只要Primary Shard是Active的,就可以创建索引。如果Active shards未达到指定的数目,则会创建索引请求会阻塞,直到集群中Active shards恢复到指定数目或者超时返回。可参考:ActiveShardsObserver#waitForActiveShards(...)方法。
索引的创建封装在org.elasticsearch.cluster.metadata.MetaDataCreateIndexService.IndexCreationTask#IndexCreationTask对象中,最终由具有优先级任务队列的线程池PrioritizedEsThreadPoolExecutor执行。
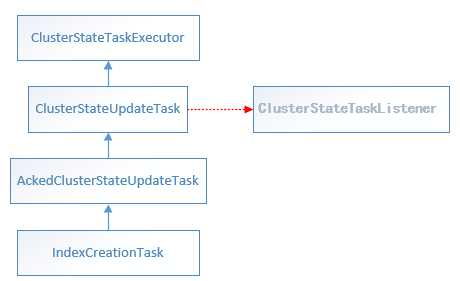
创建索引这样的操作需要通知到集群中各个节点,修改集群的状态,因此IndexCreationTask继承了AckedClusterStateUpdateTask。
在MetaDataCreateIndexService#onlyCreateIndex(...)提交IndexCreationTask。
clusterService.submitStateUpdateTask("create-index [" + request.index() + "], cause [" + request.cause() + "]",
new IndexCreationTask(logger, allocationService, request, listener, indicesService, aliasValidator, xContentRegistry, settings,
this::validate));跟踪submitStateUpdateTasks(...)调用栈,在org.elasticsearch.cluster.service.MasterService#submitStateUpdateTasks(...)方法中lambda map函数将IndexCreationTask对象转换可供线程池执行的Runnable任务:Batcher.UpdateTask。
public <T> void submitStateUpdateTasks(...,Map<T, ClusterStateTaskListener> tasks,...)
{
try {
List<Batcher.UpdateTask> safeTasks = tasks.entrySet().stream()
.map(e -> taskBatcher.new UpdateTask(config.priority(), source, e.getKey(), safe(e.getValue()), executor))
.collect(Collectors.toList());
//taskBatcher org.elasticsearch.cluster.service.TaskBatcher
taskBatcher.submitTasks(safeTasks, config.timeout());
}
}
//PrioritizedEsThreadPoolExecutor execute(...)提交创建索引任务
public abstract class TaskBatcher {
private final PrioritizedEsThreadPoolExecutor threadExecutor;
public void submitTasks(...){
if (timeout != null) {
threadExecutor.execute(firstTask, timeout, () -> onTimeoutInternal(tasks, timeout));
} else {
threadExecutor.execute(firstTask);
}
}
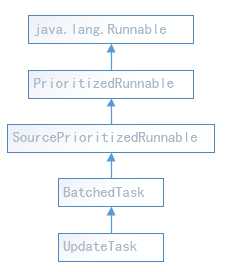
}org.elasticsearch.cluster.service.MasterService.Batcher.UpdateTask的继承关系如下:可以看出它是一个Runnable任务,创建索引操作最终由PrioritizedEsThreadPoolExecutor线程池提交任务执行。
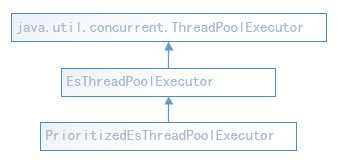
PrioritizedEsThreadPoolExecutor扩充自ThreadPoolExecutor,参考这个类的源代码,可以了解ElasticSearch是如何自定义一个带有任务优先级队列的线程池的,也可以学习一些如何扩展线程池的功能。
跟踪threadExecutor.execute(...)代码,
public void execute(Runnable command, final TimeValue timeout, final Runnable timeoutCallback) {
//给Runnable任务再添加一些额外的功能,比如优先级
command = wrapRunnable(command);
//
doExecute(command);
}
//EsThreadPoolExecutor
protected void doExecute(final Runnable command) {
try {
super.execute(command);//提交任务
}catch (EsRejectedExecutionException ex) {
if (command instanceof AbstractRunnable) {
// If we are an abstract runnable we can handle the rejection
// directly and don‘t need to rethrow it.
try {
((AbstractRunnable) command).onRejection(ex);
} finally {
((AbstractRunnable) command).onAfter();
}
}当然了,由于PrioritizedEsThreadPoolExecutor扩展自ThreadPoolExecutor,最终的执行是在:ThreadPoolExecutor的内部类Worker#runWorker(Worker w)中执行。可参考探究ElasticSearch中的线程池实现中的第3点分析。
上面分析的是线程执行流程,而具体的业务逻辑代码(创建索引更新集群的状态信息)在Runnable#run()中,也就是org.elasticsearch.cluster.service.TaskBatcher.BatchedTask#run()方法中。
//BatchedTask
public void run() {runIfNotProcessed(this);}
void runIfNotProcessed(BatchedTask updateTask) {
//任务的判断、检查是否重复、是否已经执行过了……
//忽略其他无关代码....
run(updateTask.batchingKey, toExecute, tasksSummary);
}
/**
* Action to be implemented by the specific batching implementation
* All tasks have the given batching key.
*/
protected abstract void run(Object batchingKey, List<? extends BatchedTask> tasks, String tasksSummary);抽象run(...)具体实现在:org.elasticsearch.cluster.service.MasterService.Batcher#run
@Override
protected void run(Object batchingKey, List<? extends BatchedTask> tasks, String tasksSummary) {
ClusterStateTaskExecutor<Object> taskExecutor = (ClusterStateTaskExecutor<Object>) batchingKey;
List<UpdateTask> updateTasks = (List<UpdateTask>) tasks;
//TaskInputs Represents a set of tasks to be processed together with their executor
runTasks(new TaskInputs(taskExecutor, updateTasks, tasksSummary));
}
//最终节点状态更新信息实现逻辑
protected void runTasks(TaskInputs taskInputs) {
final ClusterState previousClusterState = state();
//改变集群的状态(各个分片的处理逻辑)
TaskOutputs taskOutputs = calculateTaskOutputs(taskInputs, previousClusterState, startTimeNS);
//将变化了的状态同步给其他节点
if (taskOutputs.clusterStateUnchanged()) {
//未检测到集群状态信息变化
}else{
ClusterState newClusterState = taskOutputs.newClusterState;
try {
ClusterChangedEvent clusterChangedEvent = new ClusterChangedEvent(summary, newClusterState, previousClusterState);
//Returns the DiscoveryNodes.Delta between the previous cluster state and the new cluster state.
final DiscoveryNodes.Delta nodesDelta = clusterChangedEvent.nodesDelta();
}
if (nodesDelta.hasChanges() && logger.isInfoEnabled()) {
String nodeSummary = nodesDelta.shortSummary();
if (nodeSummary.length() > 0) {
logger.info("{}, reason: {}", summary, nodeSummary);
}
}
//Called when the result of the ClusterStateTaskExecutor#execute(ClusterState, List) have
//been processed properly by all listeners.
taskOutputs.processedDifferentClusterState(previousClusterState, newClusterState);
//Callback invoked after new cluster state is published
taskOutputs.clusterStatePublished(clusterChangedEvent);
}
在这行代码:TaskOutputs taskOutputs = calculateTaskOutputs(taskInputs, previousClusterState, startTimeNS);输入创建索引任务,输出集群状态变化结果。
public TaskOutputs calculateTaskOutputs(TaskInputs taskInputs, ClusterState previousClusterState) {
ClusterTasksResult<Object> clusterTasksResult = executeTasks(taskInputs, startTimeNS, previousClusterState);
//...
}
protected ClusterTasksResult<Object> executeTasks(TaskInputs taskInputs,...){
List<Object> inputs = taskInputs.updateTasks.stream().map(tUpdateTask -> tUpdateTask.task).collect(Collectors.toList());
//ShardStartedClusterStateTaskExecutor#execute
clusterTasksResult = taskInputs.executor.execute(previousClusterState, inputs);
}
public ClusterTasksResult<StartedShardEntry> execute(ClusterState currentState, List<StartedShardEntry> tasks)
{
List<ShardRouting> shardRoutingsToBeApplied = new ArrayList<>(tasks.size());
for (StartedShardEntry task : tasks) {
ShardRouting matched = currentState.getRoutingTable().getByAllocationId(task.shardId, task.allocationId);
//....省略其他代码
shardRoutingsToBeApplied.add(matched);
}
maybeUpdatedState = allocationService.applyStartedShards(currentState, shardRoutingsToBeApplied);
builder.successes(tasksToBeApplied);
}最终是在org.elasticsearch.cluster.action.shard.ShardStateAction.ShardStartedClusterStateTaskExecutor#execute方法里面更新各个分片的状态,具体实现逻辑我也不是很懂。里面涉及到:ShardRouting路由表、AllocationService。
AllocationService manages the node allocation of a cluster. For this reason the AllocationService keeps AllocationDeciders to choose nodes for shard allocation. This class also manages new nodes joining the cluster and rerouting of shards.
关于ElasticSearch Index操作的流程,参考ElasticSearch 索引 剖析
ElasticSearch源码阅读相关文章:
原文:https://www.cnblogs.com/hapjin/p/10219219.html
标签:setting enabled 情况下 not 分布 oid decide ctr 代码
原文地址:https://www.cnblogs.com/hapjin/p/10219219.html