标签:不能 https parallel end 不一致 number media gzip cto
1. hive的数据倾斜 介绍:只要在分布式一定有shuffle,避免不了出现数据倾斜,在混淆数据的过程中出现数据分布不均匀。比如:在MR编程中reducetask阶中的数据的大小不一致,即很多的数据集中到了一个reducetask中,hive的数据倾斜就是mapreduce的数据倾斜 maptask reducetask最后就是reducetask阶段的数据倾斜。
不会产生数据倾斜的场景:
- 不执行MapReduce程序,在hive中hive.fetch.task.conversion一共有三个可选值:
- none:表示所有的语句都执行MR,这个参数不可用
- minimal :表示select *、where 字段为分区字段、limit时不执行MR
- more :select 、filter /where 、limit不执行MR
- 聚合函数和group by一起使用的时候,在聚合函数和group by一起使用的时候,默认的MR底层在map端执行combiner,所以不会数据倾斜
会产生数据倾斜的场景:
- 聚合函数不和group by连用
- count(distinct)
- join 主要是reduce join会产生数据倾斜
以log日志为例,其中有一个字段为userid,但是userid的null值太多,在使用userid进行join时,所有的userid=null的数据都会到一个reduce中,这个reducetask数据量很大,就会产生数据倾斜。
解决方法1:
#null值不参与连接
select field1,field2,field3…
from log a left join user b on a.userid is not null and a.userid=b.
userid
union select field1,field2,field3 from log where userid is null; 解决方法2:
#将null值进行散列
select
*
from log a left join user b on
case when a.userid is null then concat("null",rand())
else a.userid end=b.userid;user userid string 表一
log userid int 表二
select * from log a left join user b on a.userid=b.userid;
默认情况下,将string转化为int类型,如果string类型的userid中是无法转化为int类型,那么返回了大量的null,然后大量的null, 又会分配到同一个reducetask中,造成数据倾斜。只要确定能将string转化为int类型,就可以避免数据倾斜。
大小表连接:大表和小表进行关联的时候,使用map端的join,在map join 时是没有数据倾斜的。其中有两个参数:
- hive.auto.convert.join #开启map join,默认是开启的
- hive.smalltable.filesize #在进行mapjoin时对小表大小的限制,默认是25000000byte,大概25M
大小表连接,但是小表数据量较大:
这个小表不是很大,但是超过了25000000byte;此时默认执行reducejoin,此时如果执行了reduce join就容易产生数据倾斜,如果这时小表的大小不是很大不超过100M,那么可以强制执行map join:
#强制执行map join
select
/*+mapjoin(表名)*/ #将小表强制放入内存
* from t1 join t2 on t1.field1=t2.field;大表*大表:对其中的一个表进行过滤,将这个表转化成相对小的表,然后强制执行map端join
这里以两个表为例:
user ----30G(所有用户)
Log ----5G (当日记录的日志)
#先对log日志表进行userid 过滤:
create table temp_log as
select distinct userid from log;
#将上面的结果和user表进行关联:(获取userid表中有效的关联数据)
create table temp_user as
select filed1, filed2,field3
/*+mapjoin(a)*/
from temp a join user b on a.userid =b.userid;
#最后,在将上面的表与log进行关联:
select filed1, filed2,field3
/*+mapjoin(a)*/
from temp_user a join Log b on a. userid =b. userid; - 好的设计模型,在设计表的时候注意数据倾斜
- 解决数据倾斜问题
- 减少job数量
- 设置合理的reduce task个数
- 了解数据的分布情况,手动解决数据倾斜
- 在数据量比较大的时候,尽量少用全局聚合类的操作
- 对小文件进行合并,减少maptask个数,提高性能
① 如何正确的选择排序:
- cluster by:对同一字段分桶并排序,不能和 sort by 连用
- distribute by + sort by:分桶,保证同一字段值只存在一个结果文件当中,结合 sort by 保证 每个 reduceTask 结果有序
- sort by:单机排序,单个 reduce 结果有序
- order by:全局排序,缺陷是只能使用一个 reduce task
② 怎样做笛卡尔积:当 Hive 设定为严格模式(hive.mapred.mode=strict)时,不允许在 HQL 语句中出现笛卡尔积
解决笛卡尔积问题:http://blog.51cto.com/14048416/2338651
文章中的:6)使用随机前缀和扩容RDD进行join,有细致讲解。
③ 怎样写好 in/exists:
#使用left semi join.去代替in/exists:
select a.id, a.name from a where a.id in (select b.id from b);
#变化为:
selecet a.id,a.name from a left semi join b on a.id=b.id;
博文:http://blog.51cto.com/14048416/2342407 其中的关于left semi join 的总结。
④ 合理处理maptask个数:
Maptask个数太大:每个Maptask都要启动一个jvm进程,启动时间过长,效率低,Maptask个数太小:负载不均衡,大量作业时,容易阻塞集群。因此通常有两种手段来解决问题:
- 减少Maptask个数,通过合并小文件实现,主要针对数据源
- 通过设置重用jvm进程的方式,减少MapReduce程序在启动和关闭jvm进程的时间:(set mapred.job.reuse.jvm.num.tasks=5) 表示map task 重用同一个jvm.
⑤ 合理设置reduce task个数:
reducer 个数的设定极大影响执行效率,这使得 Hive 怎样决定 reducer 个数成为一个关键问题,默认的在hive中只启动一个reducetask。其中有以下几个参数作为调优点:
- hive.exec.reducers.bytes.per.reducer #reduceTask的吞吐量
- hive.exec.reducers.max #启动的reducetask的最大值 经验之谈:0.95*(集群中 datanode 个数)
- mapreduce.job.reduces= #设置reducetask的个数
⑥ 小文件合并:
小文件过多,会给hdfs带来压力,并且会影响处理效率,可以通过合并 Map 和 Reduce 的 结果文件来消除这样的影响,以下几个参数可以作为调优点:
- set hive.merge.mapfiles = true 在只有maptask时,任务结束时进行文件合并
- set hive.merge.mapredfiles = false # true 时在 MapReduce 的任务结束时合并小文件
- set hive.merge.size.per.task = 25610001000 #合并的小文件的大小
- set mapred.max.split.size=256000000; #每个map最大分割数
- set mapred.min.split.size.per.node=1; #一个节点上的最小split值
- set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;,#执行map前进行小文件合并(默认开启)
⑦ 合理的设置分区:
Partition 就是分区。分区通过在创建表时启用 partitioned by 实现,为了减少查询时候的数据扫描范围 提升查询性能,当数据两个比较大的时候,对经常按照某一个字段进行过滤查询的时候,就需要按照过滤字段创建分区表。
⑧ 合理的利用存储格式:
创建表时,尽量使用 orc、parquet 这些列式存储格式,因为列式存储的表,每一列的数据在物理上是存储在一起的,Hive 查询时会只遍历需要列数据,大大减少处理的数据量。
⑨ 并行化处理
一个hive sql语句可能转化为多个mapreduce Job,每一个job就是一个stage,这些job顺序执行,在这个client的运行日志也可以看到。但是有的时候这些任务之间并不是相互依赖的,如果集群资源允许,可以让多个并不相互依赖的stage并发执行。以下有两个参数可以调优:
- set hive.exec.parallel=true; #开启并行
- set hive.exec.parallel.thread.number=8; //同一个 sql 允许并行任务的最大线程数
⑩ 设置压缩存储
Hive最终是因为转为MapReduce程序来执行,而MapReduce的性能瓶颈在与网络和IO,要解决性能瓶颈,最主要的就是减少数据量,对数据进行压缩是一个很好的办法。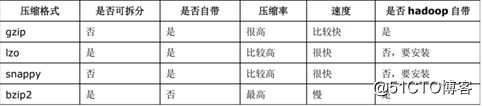
Job输出文件按照block以gzip的方式进行压缩:
set mapreduce.output.fileoutputformat.compress=true // 默认值是 false
set mapreduce.output.fileoutputformat.compress.type=BLOCK // 默认值是 Record
set mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.GzipCodec // 默认值是 org.apache.hadoop.io.compress.DefaultCodec
map输出结果以gzip进行压缩:
set mapred.map.output.compress=true
set mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.GzipCodec // 默认值是 org.apache.hadoop.io.compress.DefaultCodec
对hive输出结果和中间都进行压缩:
set hive.exec.compress.output=true // 默认值是 false,不压缩
set hive.exec.compress.intermediate=true // 默认值是 false,为 true 时 MR 设置的压缩才启用标签:不能 https parallel end 不一致 number media gzip cto
原文地址:http://blog.51cto.com/14048416/2342646