标签:print 结果 查看 cell run 算法 name 理想 bubuko
本篇主要总结1.二分类逻辑回归简单介绍 , 2.算法的实现 3.对欠拟合问题的解决方法及实现(第二部分)
1.逻辑回归
逻辑回归主要用于非线性分类问题。具体思路是首先对特征向量进行权重分配之后用 sigmoid 函数激活。如下公式(1)(2) :
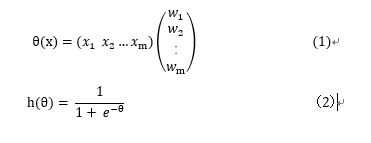
h > 0.5时,分类为1。h < 0.5时分类为0。
损失函数:如下公式(3):
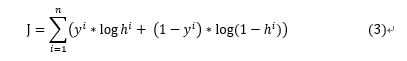
梯度下降公式如下公式(4)(推导过程略):
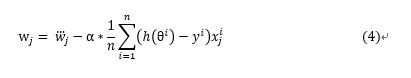
2.tensorflow 实现,代码如下:
1 # coding:utf-8 2 import tensorflow as tf 3 import matplotlib.pyplot as plt 4 import numpy as np 5 6 data=[] 7 label=[] 8 np.random.seed(0) 9 10 ##随机产生训练集 11 for i in range(500): 12 x1=np.random.uniform(-1,1) 13 x2=np.random.uniform(0,2) 14 if x1**2+ x2**2<=1: 15 data.append([np.random.normal(x1,0.1),np.random.normal(x2,0.1)]) 16 label.append(0) 17 else: 18 data.append([np.random.normal(x1,0.1),np.random.normal(x2,0.1)]) 19 label.append(1) 20 21 data=np.hstack(data).reshape(-1,2) 22 label=np.hstack(label).reshape(-1,1) 23 plt.scatter(data[ :,0], data[ :, 1], c=np.squeeze(label), cmap="RdBu", vmin=-.2, vmax=1.2, edgecolor="white") 24 plt.show() 25 #定义训练集测试集 26 num_trian = int(0.7*len(data)) 27 train_data = data[:num_trian,:] 28 train_label = label[:num_trian,:] 29 test_data = data[num_trian:,:] 30 test_label = label[num_trian:,:] 31 32 #定义参数 33 learningrate = 0.05 34 num_epotchs = 50000 35 w = tf.Variable(tf.random_normal([2,1], mean = 0.0, stddev = 1.0), name="w", trainable=True) 36 b = tf.Variable(tf.random_normal([1], mean = 0.0, stddev = 1.0), name = ‘b‘, trainable = True) 37 38 #构造输入输出门 39 x=tf.placeholder(tf.float32,shape=(None,2)) 40 y=tf.placeholder(tf.float32,shape=(None,1)) 41 sample_size=len(data) 42 #逻辑回归模型 43 y_logistic = tf.sigmoid(tf.add(tf.matmul(x,w),b)) 44 cost = tf.reduce_mean(-y*(tf.log(y_logistic))-(1-y)*(tf.log(1-y_logistic))) 45 train_op = tf.train.GradientDescentOptimizer(learningrate).minimize(cost) 46 47 error = [] 48 initial = tf.global_variables_initializer() 49 with tf.Session() as sess: 50 #初始化全局变量 51 sess.run(initial) 52 #开始训练 53 for epotch in range(num_epotchs): 54 err,_ = sess.run([cost,train_op],feed_dict = {x : train_data, y :train_label}) 55 if epotch % 500 == 0: 56 print(‘after %d steps ,error is %.3f‘%(epotch,err)) 57 error.append(err) 58 59 xx,yy= np.mgrid[-1.2:1.2:.01,-0.2:2.2:.01] 60 #合并两个数组 61 grid=np.c_[xx.ravel(),yy.ravel()] 62 probs=sess.run(y_logistic,feed_dict={x:grid}) 63 plt.plot(error, label = "cost") 64 plt.legend() 65 plt.show() 66 probs=probs.reshape(xx.shape) 67 #可视化检验数据集 68 plt.scatter(test_data[ :,0], test_data[ :, 1], c=np.squeeze(test_label), cmap="RdBu", vmin=-.2, vmax=1.2, edgecolor="white") 69 #用h = 0.5等高线画出分类边界,查看分类效果 70 plt.contour(xx,yy,probs,levels=[.5],cmap="Greys",vmin=0,vmax=.1) 71 plt.show()
实现之后,结果如下图(1)。可以看到,分类结果不是很理想,没有很好地做到非线性拟合。这里面涉及到特征维度不足的问题。在第二部分中讲解解决方法。
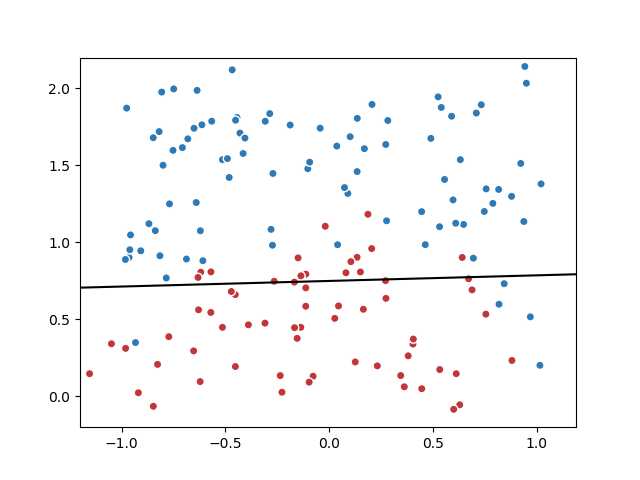
| 图1 |
转载请注明出处
标签:print 结果 查看 cell run 算法 name 理想 bubuko
原文地址:https://www.cnblogs.com/zaodaxx/p/10268867.html