标签:datasets 预处理 pat RKE 一个 lse 信息 初学者 worker
pytorch初学者,想加载自己的数据,了解了一下数据类型、维度等信息,方便以后加载其他数据。
1 torchvision.transforms实现数据预处理
transforms.Totensor()操作必须要有,将数据转为张量格式。
2 torch.utils.data.Dataset实现数据读取
要使用自己的数据集,需要构建Dataset子类,定义子类为MyDataset,在MyDataset的init函数中定义path_dict变量,来获取不同类型的数据的路径。
定义子类MyDataset时,必须要重载两个函数 getitem 和 len,
__getitem__:实现数据集的下标索引,返回对应的数据及标签;
__len__:返回数据集的大小。
设加载的数据集大小为L;
定义MyDataset实例:my_datasets = MyDataset(data_dir, transform = data_transform) 。
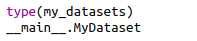
my_datasets 由L个tuple组成,len(my_datasets) = L;
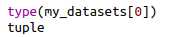
每个tuple长度为2:0:tensor 样本(Channel,Height,Width)
1:int 标签

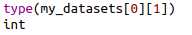

3 torch.utils.data.DataLoader实现数据集加载
torch.utils.data.DataLoader()合成数据并提供迭代访问,由两部分组成:
—dataset(Dataset):输入要加载的数据,就是上面的my_datasets;
—batch_size,shuffle,sampler,batch_sampler,num_workers,collate_fn, drop_last,timeout,worker_init_fn等参数。
其中:batch_size:批尺寸,默认为1;
shuffle:是否在每个epoch开始随机打乱数据,默认为False;
设data_loader长度为 l ;
加载数据:data_loader = DataLoader(my_datasets, batch_size = BATCH_SIZE, shuffle = True)
data_loader 由 l 个 tuple组成,l = len(data_loader) = len(my_datasets) / batch_size;
迭代访问:


e 长度为2:0:int step 表示第几个batch
1:list(长度为2)表示一个batch包含的所有样本和标签
0:tensor 样本(Batch_size,Channel,Height,Width)
1:tensor 标签 Batch_size
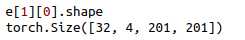
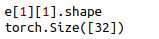
标签:datasets 预处理 pat RKE 一个 lse 信息 初学者 worker
原文地址:https://www.cnblogs.com/kkwy/p/10270697.html