标签:阶段 一个 好的 dev 获得 子集 编程 泛化 val
原文链接:https://developers.google.com/machine-learning/crash-course/validation/
将一个数据集划分为训练集和测试集。
借助这种划分,可以对一个样本集进行训练,然后使用不同的样本集测试模型。工作流程如下: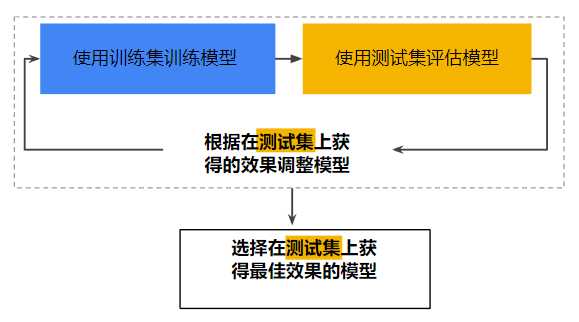
在“调整模型”阶段,可以调整学习速率、添加或移除特征,到从头开始设计全新模型。
可以看到使用测试集和训练集来推动模型开发迭代,在每次迭代时,都会对训练数据进行训练并评估测试数据,并以基于测试数据的评估结果为指导来选择和更改各种模型超参数,例如学习速率和特征。
以上方法可能存在的问题:
将单个数据集划分为三个子集,可以大幅降低过拟合的发生几率。
使用验证集评估训练集的效果。然后,在模型“通过”验证集之后,使用测试集再次检查评估结果。工作流程如下: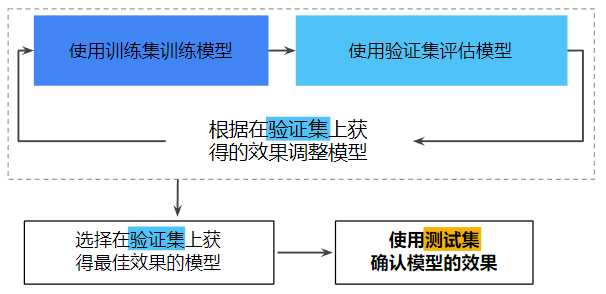
在此工作流程中:
该工作流程之所以更好,原因在于它暴露给测试集的信息更少。
不断使用测试集和验证集会使其逐渐失去效果。
也就是说,使用相同数据来决定超参数设置或其他模型改进的次数越多,对于这些结果能够真正泛化到未见过的新数据的信心就越低。
请注意,验证集的失效速度通常比测试集缓慢。
如果可能的话,建议收集更多数据来“刷新”测试集和验证集。重新开始是一种很好的重置方式。
原文链接:https://colab.research.google.com/notebooks/mlcc/validation.ipynb
过拟合 (overfitting)
创建的模型与训练数据过于匹配,以致于模型无法根据新数据做出正确的预测。
测试集 (test set)
数据集的子集,用于在模型经由验证集的初步验证之后测试模型。
与训练集和验证集相对。
训练集 (training set)
数据集的子集,用于训练模型。
与验证集和测试集相对。
验证集 (validation set)
数据集的一个子集,从训练集分离而来,用于调整超参数。
与训练集和测试集相对。
标签:阶段 一个 好的 dev 获得 子集 编程 泛化 val
原文地址:https://www.cnblogs.com/anliven/p/10280117.html