标签:虚拟机 功能 上传 监视 创建 span 取数 erp 环境
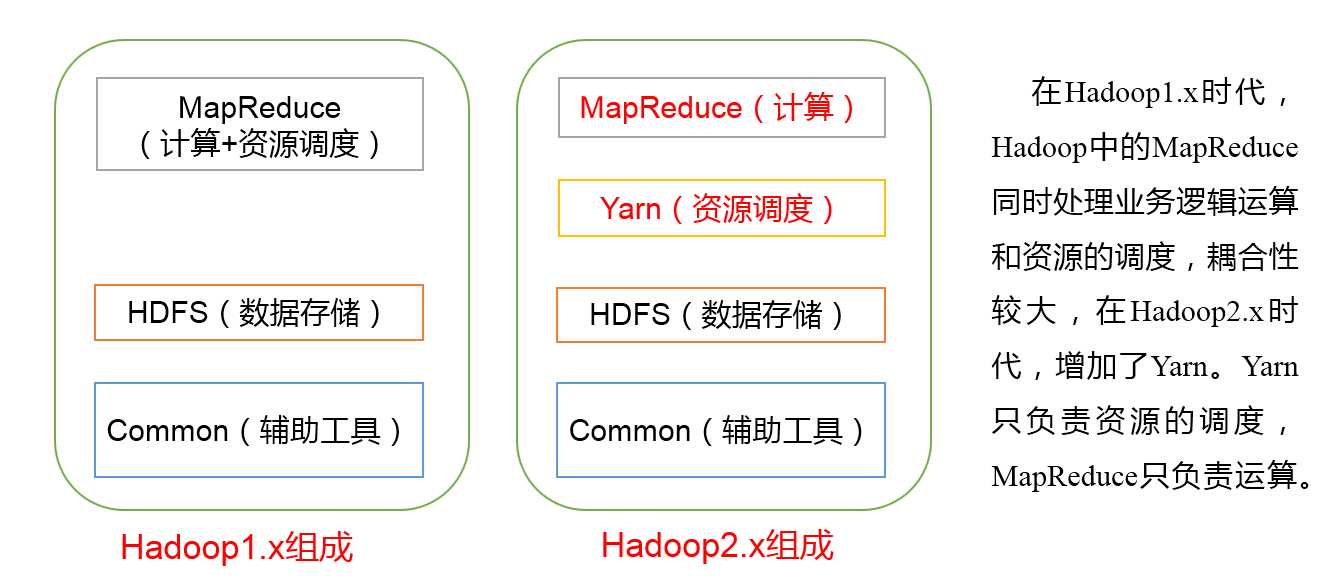
HDFS(Hadoop Distributed File System)架构概述
NameNode目录--主刀医生(nn); DataNode(dn)数据; Secondary NameCode(2nn)助手;

YARN框架 常驻 + 临时
ResourceManager(RM) 组长;
NodeManager 组员;
Client客户;Job Submission来任务了 ---->> ApplicationMaster,任务结束它就卸任了;
ApplicationMaster(AM)临时项目任务负责人,由RM任命监视等;
容器Container:底层没有虚拟,只虚拟了应用层,但仍可以隔离cup和内存;(与虚拟机的区别);可以在一个机器里开3个容器(都要是一样的如3个window,因为系统底层没变;)
占cpu内存用来运行任务如APP Mster;
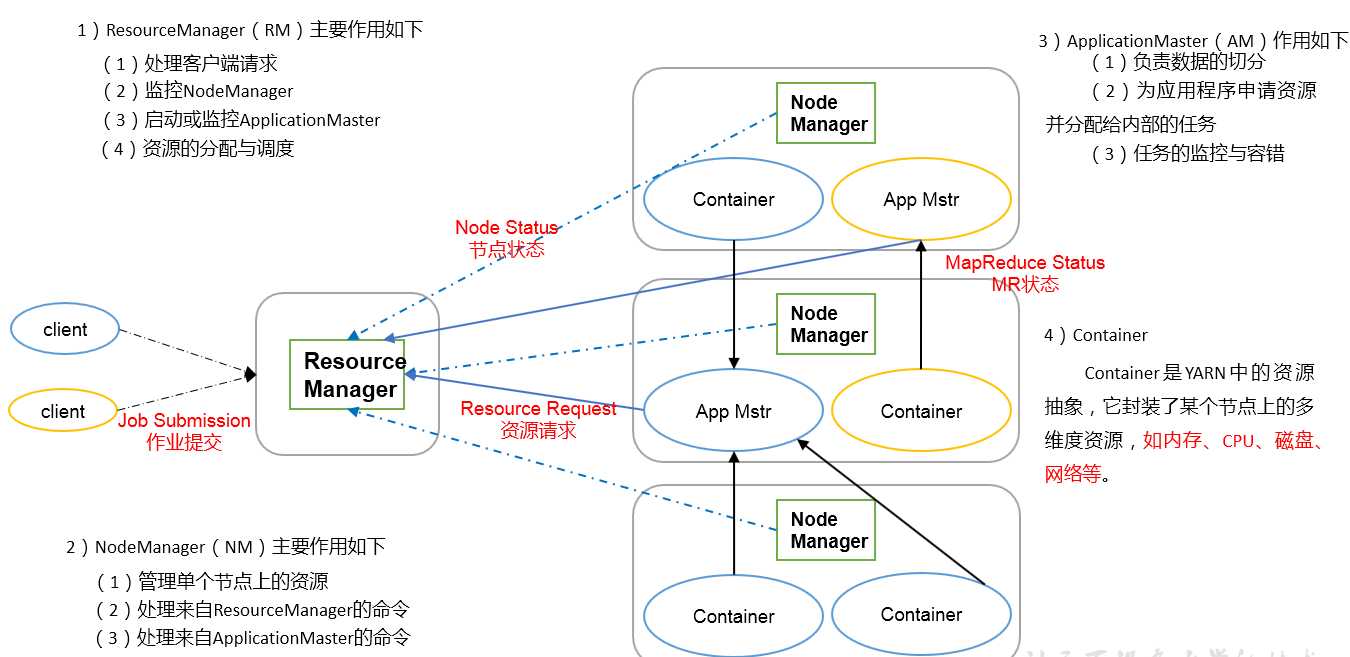
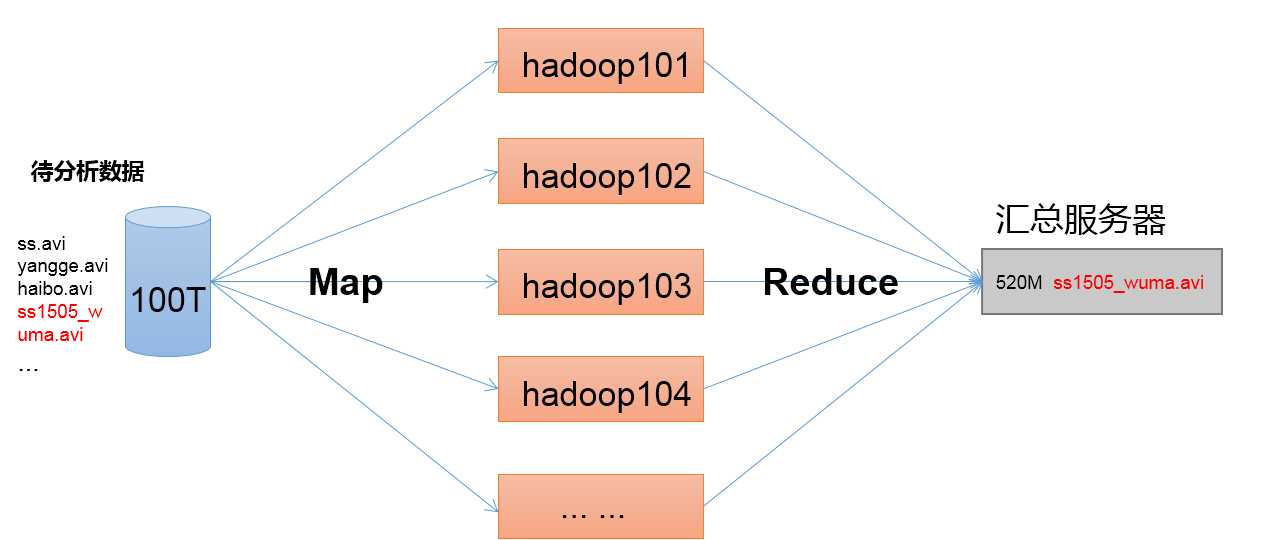
MapReduce架构概述 计算引擎
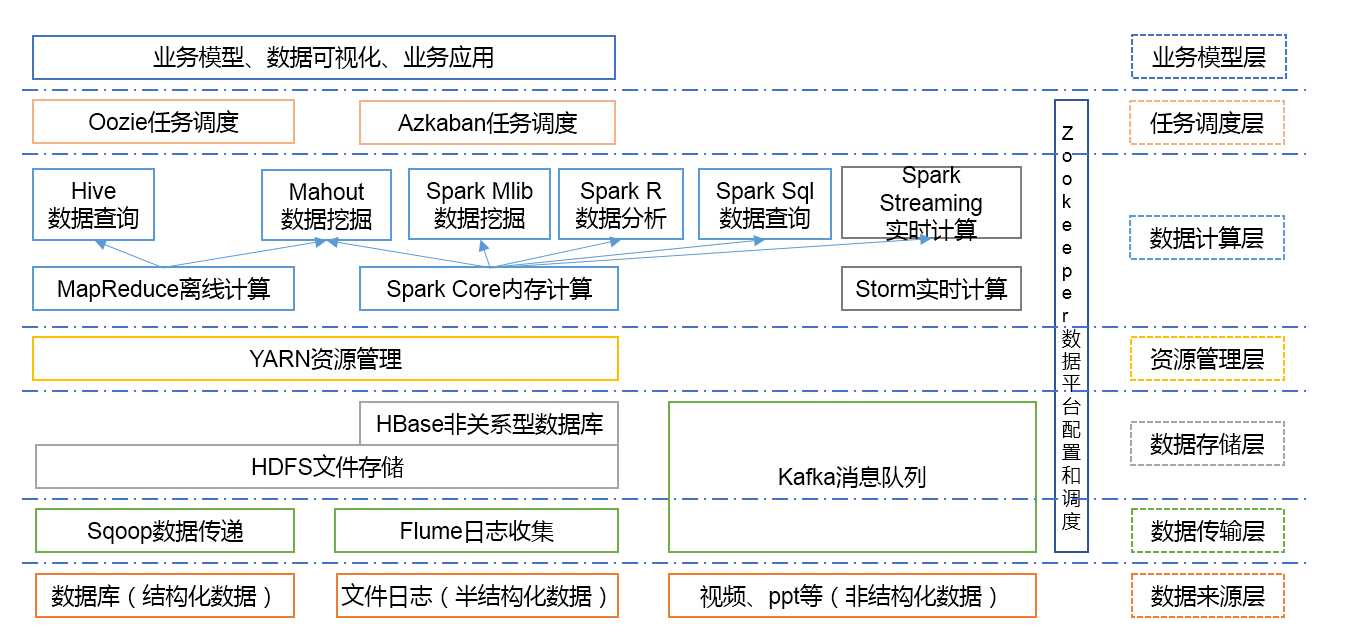
大数据生态体系
查看Hadoop目录结构
[atguigu@hadoop101 hadoop-2.7.2]$ ll
总用量 52
drwxr-xr-x. 2 atguigu atguigu 4096 5月 22 2017 bin
drwxr-xr-x. 3 atguigu atguigu 4096 5月 22 2017 etc
drwxr-xr-x. 2 atguigu atguigu 4096 5月 22 2017 include
drwxr-xr-x. 3 atguigu atguigu 4096 5月 22 2017 lib
drwxr-xr-x. 2 atguigu atguigu 4096 5月 22 2017 libexec
-rw-r--r--. 1 atguigu atguigu 15429 5月 22 2017 LICENSE.txt
-rw-r--r--. 1 atguigu atguigu 101 5月 22 2017 NOTICE.txt
-rw-r--r--. 1 atguigu atguigu 1366 5月 22 2017 README.txt
drwxr-xr-x. 2 atguigu atguigu 4096 5月 22 2017 sbin
drwxr-xr-x. 4 atguigu atguigu 4096 5月 22 2017 share
重要目录
(1)bin目录:存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本
(2)etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
(3)lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
(4)sbin目录:存放启动或停止Hadoop相关服务的脚本
(5)share目录:存放Hadoop的依赖jar包、文档、和官方案例
Hadoop运行模式包括:本地模式、伪分布式模式以及完全分布式模式。
本地式
可运行的程序只有MapReduce(程序);而yarn(内存和cup),HDFS(硬盘)是给MapReduce提供运行的环境;
本地式用的不是hdfs,而是本地的硬盘;而调度的资源也不是来自yarn而是本地的操作系统;
.xml文件就是输入;grep是执行jar包的哪个主类,一个jar包可以有多个主类和主方法;输入文件夹--输出文件夹(起始没有这个文件夹,否则会报错)--‘ 模板正则等 ‘
wordcount是一个主类
伪分布式:一台电脑搭出一个集群;HDFS分3个组建NameNode、DataNode、Secondary NameNode; yarn是分4个组建,实际只搭2个ResourceManage和NodeManager,
既是NameNode也是DataNode;既是ResourceManager也是NodeManager,这些进程都跑在一台机器上;
hadoop-env.sh、mapred-env.sh、yarn-env.sh三个配置java_home
core-site.xml 指定HDFS中NameNode的地址;定Hadoop运行时产生文件的存储目录
hdfs-site.xml 指定HDFS副本的数量 为1,就1台机器; 这些副本肯定分布在不同的服务器上;
mapred-site.xml 指定MR运行在YARN上
yarn-site.xml Reducer获取数据的方式;指定YARN的ResourceManager的地址(服务器)
hdfs namenode -format格式化HDFS
hadoop-daemon.sh start namenode 启动NameNode
hadoop-daemon.sh start datanode 启动DataNode
启动前必须保证NameNode和DataNode已经启动
启动ResourceManager;
启动NodeManager
hadoop fs -put wcinput/ / 往集群的跟目录中上传一个wcinput文件
158 hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /wcinput /output
[kris@hadoop100 hadoop-2.7.2]$ dirname /opt/module/hadoop-2.7.2/
/opt/module
[kris@hadoop100 hadoop-2.7.2]$ dirname hadoop-2.7.2
.
[kris@hadoop100 hadoop-2.7.2]$ cd -P .
[kris@hadoop100 hadoop-2.7.2]$ pwd
/opt/module/hadoop-2.7.2
遍历所有的主机名
##########集群分发脚本
#!/bin/bash
#xxx /opt/module
if (($#<1))
then
echo ‘参数不足‘
exit
fi
fl=$(basename $1) #文件名 basename /opt/module/hadoop-2.7.2/-->>hadoop-2.7.2
pdir=$(cd -P $(dirname $1); pwd) 父目录 dirname /opt/module/hadoop-2.7.2/ --->> /opt/module
for host in hadoop102 hadoop103 hadoop104
do
rsync -av $pdir/$fl $host:$pdir
done
用scp发送
scp -r hadoop100:/opt/module/jdk1.8.0_144 hadoop102:/opt/module/
用rsync发送
[kris@hadoop100 module]$ rsync -av hadoop-2.7.2/ hadoop102:/opt/module/ 把当前目录下的全发过去了
[kris@hadoop102 module]$ ls
bin include jdk1.8.0_144 libexec NOTICE.txt README.txt share
etc input lib LICENSE.txt output sbin wcinput
[kris@hadoop102 module]$ ls | grep -v jdk
过滤删除只剩jdk的
[kris@hadoop102 module]$ ls | grep -v jdk | xargs rm -rf
[kris@hadoop100 module]$ ll
总用量 12
drwxr-xr-x. 12 kris kris 4096 1月 15 14:55 hadoop-2.7.2
drwxr-xr-x. 8 kris kris 4096 7月 22 2017 jdk1.8.0_144
-rw-rw-r--. 1 kris kris 223 1月 15 17:13 xsync
[kris@hadoop100 module]$ chmod +x xsync
[kris@hadoop100 module]$ ll
总用量 12
drwxr-xr-x. 12 kris kris 4096 1月 15 14:55 hadoop-2.7.2
drwxr-xr-x. 8 kris kris 4096 7月 22 2017 jdk1.8.0_144
-rwxrwxr-x. 1 kris kris 223 1月 15 17:13 xsync
[kris@hadoop100 module]$
[kris@hadoop100 module]$ ./xsync /opt/module/jdk1.8.0_144
[kris@hadoop100 module]$ ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/home/kris/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/kris/.ssh/id_rsa. Your public key has been saved in /home/kris/.ssh/id_rsa.pub. The key fingerprint is: fd:15:a4:68:6e:88:c3:a1:f4:64:1b:aa:95:12:02:4a kris@hadoop100 The key‘s randomart image is: +--[ RSA 2048]----+ |.E . | |+ . o | |o . . = o . . | | . o O = = . | | . = * S + . | | + . . . . | | . . | | | | | +-----------------+ [kris@hadoop100 module]$ ssh-copy-id hadoop100 #给自己也发一份 [kris@hadoop100 module]$ ssh-copy-id hadoop101 [kris@hadoop100 module]$ ssh-copy-id hadoop102 [kris@hadoop100 module]$ ssh-copy-id hadoop103 [kris@hadoop100 module]$ ssh-copy-id hadoop104
100给100、101、102、103、104都赋权了;100<==>100双向通道已经建立,我能到自己了;可以把这个双向通道copy给其他的;
[kris@hadoop100 .ssh]$ ll
总用量 16
-rw-------. 1 kris kris 396 1月 15 18:45 authorized_keys 把公钥放在已授权的keys里边,它跟公钥里边内容是一样的;
-rw-------. 1 kris kris 1675 1月 15 18:01 id_rsa 秘钥
-rw-r--r--. 1 kris kris 396 1月 15 18:01 id_rsa.pub 公钥
-rw-r--r--. 1 kris kris 2025 1月 15 17:37 known_hosts
[kris@hadoop102 .ssh]$ ll 总用量 4 -rw-------. 1 kris kris 396 1月 15 18:04 authorized_keys [kris@hadoop100 module]$ ./xsync /home/kris/.ssh #给其他账户发送.ssh sending incremental file list .ssh/ .ssh/id_rsa .ssh/id_rsa.pub .ssh/known_hosts sent 4334 bytes received 73 bytes 8814.00 bytes/sec total size is 4096 speedup is 0.93 sudo cp xsync /bin #copy到bin目录,就可全局使用; [kris@hadoop100 module]$ xsync /opt/module/hadoop-2.7.2/
6 NN RM 2NN
DN|NM DN|NM DN|NM
101 102 103
NameNode ResourceManager SecondaryNameNode
104 105 106
DataNode DateNode DateNode
NodeManager NodeManager NodeManager
slave 104| 105 | 106
HDFS: NameNode| DataNode | SecondaryNameNode
YARN: ResourceManager | NodeManager
清理数据(每一台):
[kris@hadoop100 ~]$ cd $HADOOP_HOME
[kris@hadoop100 hadoop-2.7.2]$ rm -rf data logs
101 102 103
NameNode ResourceManager SecondaryNameNode
DataNode DataNode DataNode
NodeManager NodeManager NodeManager
pwd $JAVA_HOME
$HADOOP_HOME/etc/hadoop
(对mapred-site.xml.template重新命名为) mapred-site.xml
配置hadoop-env.sh,yarn-env.sh,mapred-env.sh文件,配置Java_HOME
配置Core-site.xml--->>指定HDFS中NameNode的地址 hdfs://hadoop101:9000 ; 指定Hadoop运行时产生文件的存储目录 /opt/module/hadoop-2.7.2/data/tmp
配置hdfs-site.xml-->>数据的副本数量 ; 指定Hadoop辅助名称节点主机配置 hadoop103:50090
配置yarn-site.xml-->>Reducer获取数据的方式 指定YARN的ResourceManager的地址:hadoop102; 日志聚集功能使能; 日志保留时间设置7天
配置mapred-site.xml-->>历史服务器端地址:adoop103:10020 ;历史服务器web端地址:hadoop103:19888
配置Slaves hadoop101 hadoop102 hadoop103
格式化创建namenode hdfs namenode -format
在101上启动HDFS: start-dfs.sh (101namenode)
在Hadoop102上启动 start-yarn.sh
关闭:
[kris@hadoop101 hadoop-2.7.2]$ stop-dfs.sh
Stopping namenodes on [hadoop101]
hadoop101: stopping namenode
hadoop101: stopping datanode
hadoop102: stopping datanode
hadoop103: stopping datanode
Stopping secondary namenodes [hadoop103]
hadoop103: stopping secondarynamenode
[kris@hadoop102 hadoop-2.7.2]$ stop-yarn.sh
stopping yarn daemons
stopping resourcemanager
hadoop102: stopping nodemanager
hadoop103: stopping nodemanager
hadoop101: stopping nodemanager
no proxyserver to stop
jpsall脚本:
#!/bin/bash
for i in hadoop101 hadoop102 hadoop103
do
echo "-------$i-------"
ssh $i "source /etc/profile && jps" | grep -v jps
done
~
"jpsall" 6L, 135C 已写入
[kris@hadoop101 hadoop-2.7.2]$ sh jpsall
-------hadoop101-------
3377 DataNode
4099 Jps
3238 NameNode
3676 NodeManager
-------hadoop102-------
4160 Jps
3476 NodeManager
3177 DataNode
3359 ResourceManager
-------hadoop103-------
3976 Jps
3449 NodeManager
3209 DataNode
3279 SecondaryNameNode
标签:虚拟机 功能 上传 监视 创建 span 取数 erp 环境
原文地址:https://www.cnblogs.com/shengyang17/p/10274391.html