标签:统一 inf 修复 而且 排名 运行 时间 class 目录
解决服务器的CPU和内存压力;解决IO的压力;
打破了传统关系型数据库以业务逻辑为依据的存储模式,而针对不同数据结构类型改为以性能为最优先的存储方式。
缓存数据库:减少io的读操作;列式数据库;文档数据库;水平切分、垂直切分、读写分离;通过破坏一定的业务逻辑来换取性能
NoSQL(NoSQL = Not Only SQL ),意即“不仅仅是SQL”,泛指非关系型的数据库。
NoSQL 不依赖业务逻辑方式存储,而以简单的key-value模式存储。因此大大的增加了数据库的扩展能力。
不遵循SQL标准。不支持ACID。远超于SQL的性能。NoSQL适用场景
NoSQL适用场景:
对数据高并发的读写;海量数据的读写;对数据高可扩展性的
NoSQL不适用场景:
需要事务支持;基于sql的结构化查询存储,处理复杂的关系,需要即席查询。
Memcached和Redis的区别:
Memcached
数据都在内存中,一般不持久化
支持简单的key-value模式
一般是作为缓存数据库辅助持久化的数据库
Redis
几乎覆盖了Memcached的绝大部分功能
数据都在内存中,支持持久化,主要用作备份恢复
除了支持简单的key-value模式,还支持多种数据结构的存储,比如 list、set、hash、zset等。
一般是作为缓存数据库辅助持久化的数据库
mongoDB
高性能、开源、模式自由(schema free)的文档型数据库
数据都在内存中, 如果内存不足,把不常用的数据保存到硬盘
虽然是key-value模式,但是对value(尤其是json)提供了丰富的查询功能
支持二进制数据及大型对象
可以根据数据的特点替代RDBMS ,成为独立的数据库。或者配合RDBMS,存储特定的数据。
行式存储数据库
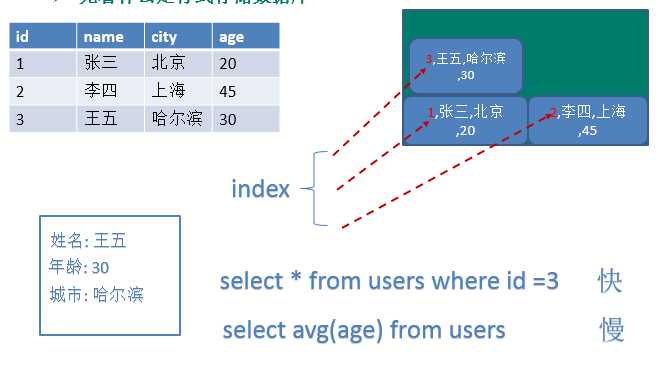
列式存储数据库

HBase
HBase是Hadoop项目中的数据库。它用于需要对大量的数据进行随机、实时的读写操作的场景中。HBase的目标就是处理数据量非常庞大的表,可以用普通的计算机处理超过10亿行数据,还可处理有数百万列元素的数据表。
Cassandra
Apache Cassandra是一款免费的开源NoSQL数据库,其设计目的在于管理由大量商用服务器构建起来的庞大集群上的海量数据集(数据量通常达到PB级别)。在众多显著特性当中,Cassandra最为卓越的长处是对写入及读取操作进行规模调整,而且其不强调主集群的设计思路能够以相对直观的方式简化各集群的创建与扩展流程。
Noe4j
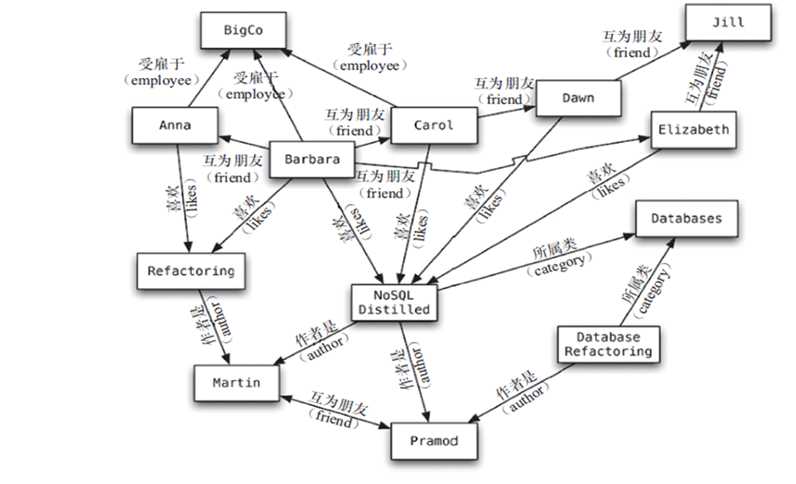
主要应用:社会关系,公共交通网络,地图及网络拓谱
Redis是一个开源的key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,Redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是Redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。

3.2.5 for Linux
1、下载获得redis-3.2.5.tar.gz后将它放入我们的Linux目录/opt
Alt+p弹出框, àsftp> pwd cd /opt/ 然后把压缩包拖到里边
2、解压命令:tar -zxvf redis-3.2.5.tar.gz
3、解压完成后进入目录:cd redis-3.2.5
4、在redis-3.2.5目录下执行make命令
运行make命令时出现故障意出现的错误解析:gcc:命令未找到
yum install gcc
yum install gcc-c++
5、在redis-3.2.5目录下再次执行make命令
Jemalloc/jemalloc.h:没有那个文件
解决方案:运行make distclean之后再 make
6、在redis-3.2.5目录下再次执行make命令
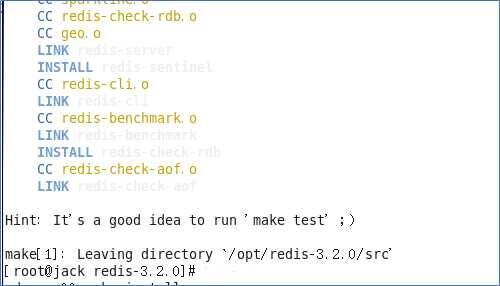
Redis Test(可以不用执行)
执行完make后,跳过Redis test 继续执行make install
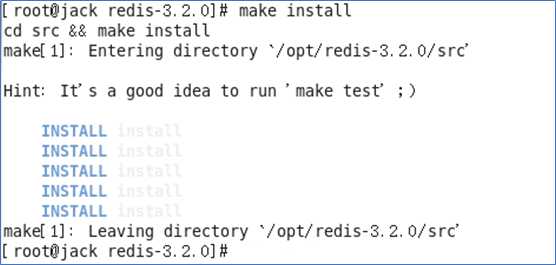
查看默认安装目录:usr/local/bin à cd /usr/local/bin
进入bin目录ll可以查看下面的命令:
启动:
1、备份redis.conf:拷贝一份redis.conf到其他目录
[root@kris bin]# ps -ef | grep redis
root 7901 3479 3 10:29 pts/0 00:00:00 grep redis 查看到redis进程已关
[root@kris bin]# cd /opt/redis-3.2.5 àll查看这个目录下命令
mkdir /root/myredis
cp redis.conf /root/myredis à复制备份redis.conf文件
2、修改redis.conf文件将里面的daemonize no 改成 yes,让服务在后台启动
cd myredis/
vi redis.conf
3、启动命令:执行 redis-server /myredis/redis.conf
redis-server redis.conf
redis-cli
4、用客户端访问: redis-cli




多实例关闭,指定端口关闭:Redis-cli -p 6379 shutdown
Redis数据类型

keys *
查询当前库的所有键
keys *
查询当前库的所有键
判断某个键是否存在
type <key>
查看键的类型
del <key>
删除某个键
expire <key> <seconds>
为键值设置过期时间,单位秒。
ttl <key>
查看还有多少秒过期,-1表示永不过期,-2表示已过期
dbsize
查看当前数据库的key的数量
flushdb
清空当前库
get <key>
查询对应键值
set <key> <value> 只能添加1对键值对
添加键值对
append <key> <value>
将给定的<value> 追加到原值的末尾
strlen <key>
获得值的长度
setnx <key> <value>
只有在 key 不存在时设置 key 的值
incr <key>
将 key 中储存的数字值增1
只能对数字值操作,如果为空,新增值为1
decr <key>
将 key 中储存的数字值减1
只能对数字值操作,如果为空,新增值为-1
incrby / decrby <key> <步长>
将 key 中储存的数字值增减。自定义步长。
mset <key1> <value1> <key2> <value2> .....
同时设置一个或多个 key-value对
mget <key1> <key2> <key3> .....
同时获取一个或多个 value
msetnx <key1> <value1> <key2> <value2> .....
同时设置一个或多个 key-value 对,当且仅当所有给定 key 都不存在。
getrange <key> <起始位置> <结束位置>
获得值的范围,类似java中的substring
setrange <key> <起始位置> <value>
用 <value> 覆写<key> 所储存的字符串值,从<起始位置>开始。
setex <key> <过期时间> <value>
设置键值的同时,设置过期时间,单位秒。
getset <key> <value>
以新换旧,设置了新值同时获得旧值。
lpush/rpush <key> <value1> <value2> <value3> ....
从左边/右边插入一个或多个值。
lpop/rpop <key>
从左边/右边吐出一个值。
值在键在,值亡键亡。吐出来就从原来的删除了
rpoplpush <key1> <key2>
从<key1>列表右边吐出一个值,插到<key2>列表左边。
lrange <key> <start> <stop>
按照索引下标获得元素(从左到右)
lindex <key> <index>
按照索引下标获得元素(从左到右)
llen <key>
获得列表长度
linsert <key> before <value> <newvalue>
在<value>的前面插入<newvalue>
lrem <key> <n> <value>
从左边删除n个value(从左到右)
sadd <key> <value1> <value2> .....
将一个或多个 member 元素加入到集合 key 当中,已经存在于集合的 member 元素将被忽略。
smembers <key>
取出该集合的所有值。
sismember <key> <value>
判断集合<key>是否为含有该<value>值,有返回1,没有返回0
scard <key>
返回该集合的元素个数。
srem <key> <value1> <value2> ....
删除集合中的某个元素。
spop <key> [count]
随机从该集合中吐出一个值。吐出就删除掉了
srandmember <key> <n>
随机从该集合中取出n个值。
不会从集合中删除
sinter <key1> <key2>
返回两个集合的交集元素。
sunion <key1> <key2>
返回两个集合的并集元素。
sdiff <key1> <key2>
返回两个集合的差集元素。
hset <key> <field> <value>
给<key>集合中的 <field>键赋值<value>
hget <key1> <field>
从<key1>集合<field> 取出 value
hmset <key1> <field1> <value1> <field2> <value2>...
批量设置hash的值
hexists key <field>
查看哈希表 key 中,给定域 field 是否存在。
hkeys <key>
列出该hash集合的所有field
hvals <key>
列出该hash集合的所有value
hincrby <key> <field> <increment>
为哈希表 key 中的域 field 的值加上增量 increment
hsetnx <key> <field> <value>
将哈希表 key 中的域 field 的值设置为 value ,当且仅当域 field 不存在 .
Redis有序集合zset与普通集合set非常相似,是一个没有重复元素的字符串集合。不同之处是有序集合的所有成员都关联了一个评分(score) ,这个评分(score)被用来按照从最低分到最高分的方式排序集合中的成员。集合的成员是唯一的,但是评分可以是重复了 。
因为元素是有序的, 所以你也可以很快的根据评分(score)或者次序(position)来获取一个范围的元素。访问有序集合的中间元素也是非常快的,因此你能够使用有序集合作为一个没有重复成员的智能列表。
zadd <key> <score1> <value1> <score2> <value2>...
将一个或多个 member 元素及其 score 值加入到有序集 key 当中。
zrange <key> <start> <stop> [WITHSCORES]
返回有序集 key 中,下标在<start> <stop>之间的元素
带WITHSCORES,可以让分数一起和值返回到结果集。
zrangebyscore key min max [withscores] [limit offset count]
返回有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或 max )的成员。有序集成员按 score 值递增(从小到大)次序排列。
zrevrangebyscore key max min [withscores] [limit offset count]
同上,改为从大到小排列。
zincrby <key> <increment> <value>
为元素的score加上增量
zrem <key> <value>
删除该集合下,指定值的元素
zcount <key> <min> <max>
统计该集合,分数区间内的元素个数
zrank <key> <value>
返回该值在集合中的排名,从0开始。
Jedis所需的jar包
public class TestJedis {
Jedis jedis = new Jedis("192.168.1.100", 6379);
public void main(String[] args) {
}
//测试连接是否成功
@Test
void test1() {
System.out.println("Connection success:" + jedis.ping());
}
}
标签:统一 inf 修复 而且 排名 运行 时间 class 目录
原文地址:https://www.cnblogs.com/shengyang17/p/10264947.html