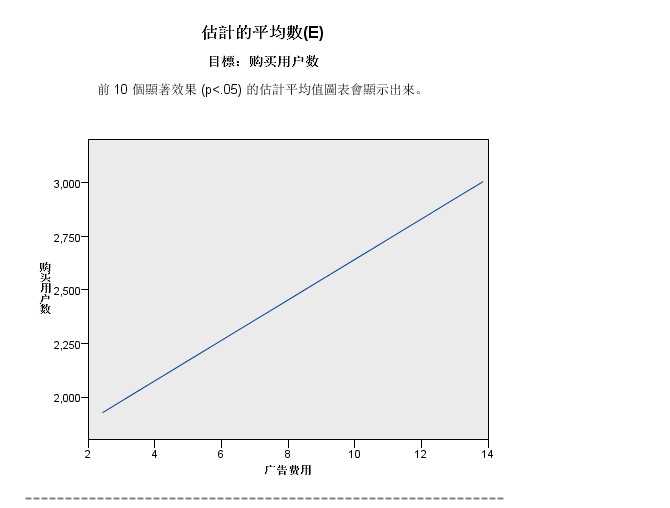
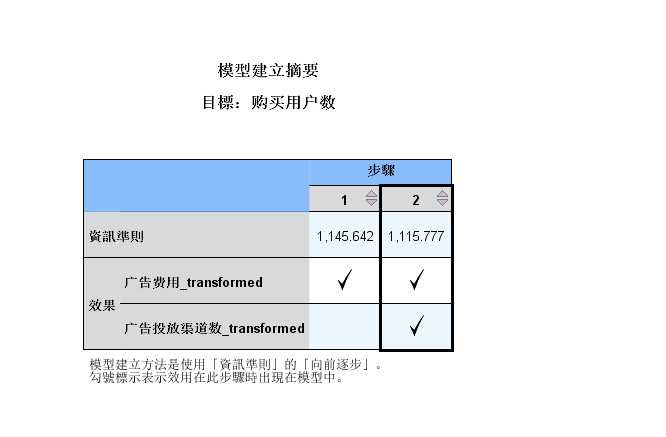
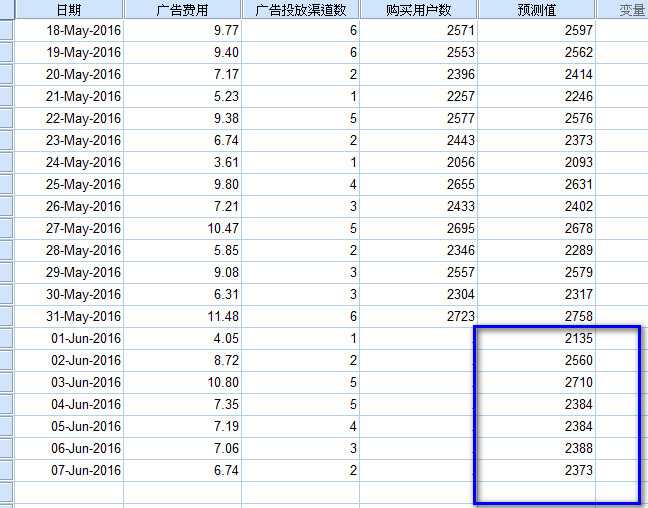
标签:bubuko 角色 重要性 get 用户数 建模 增加 多少 图形
实验10-SPSS-自动线性建模
原文地址:https://www.cnblogs.com/xuxaut-558/p/10285707.html
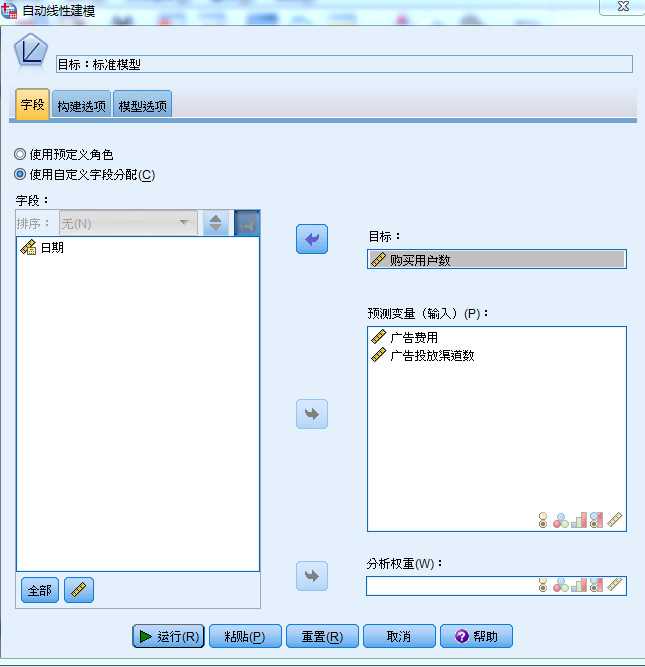
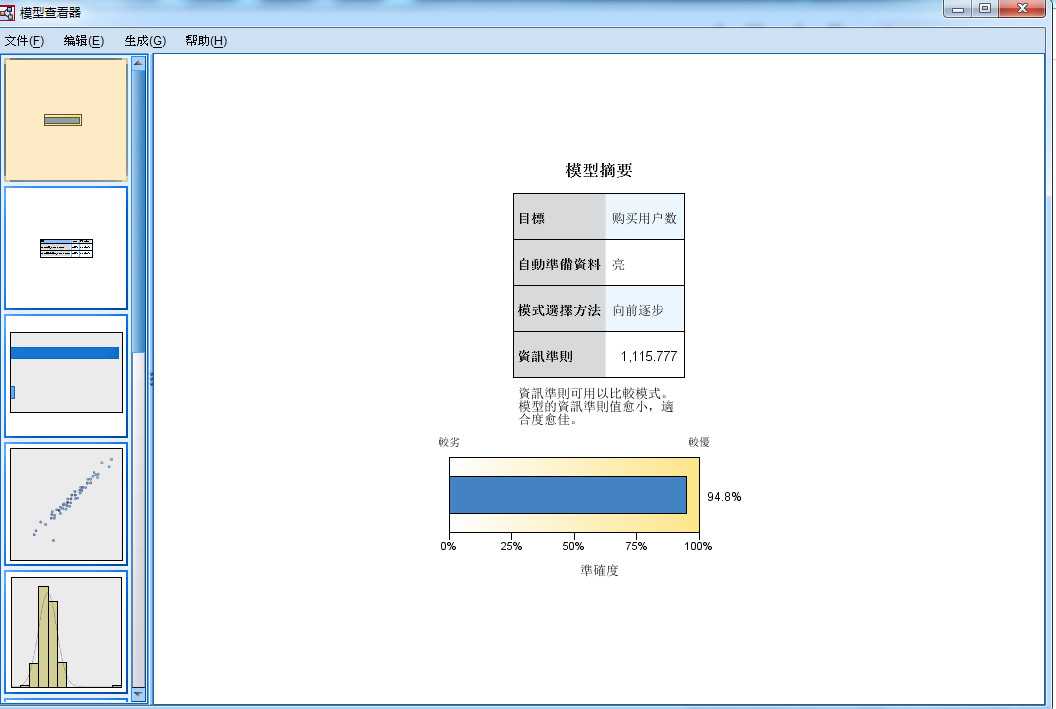
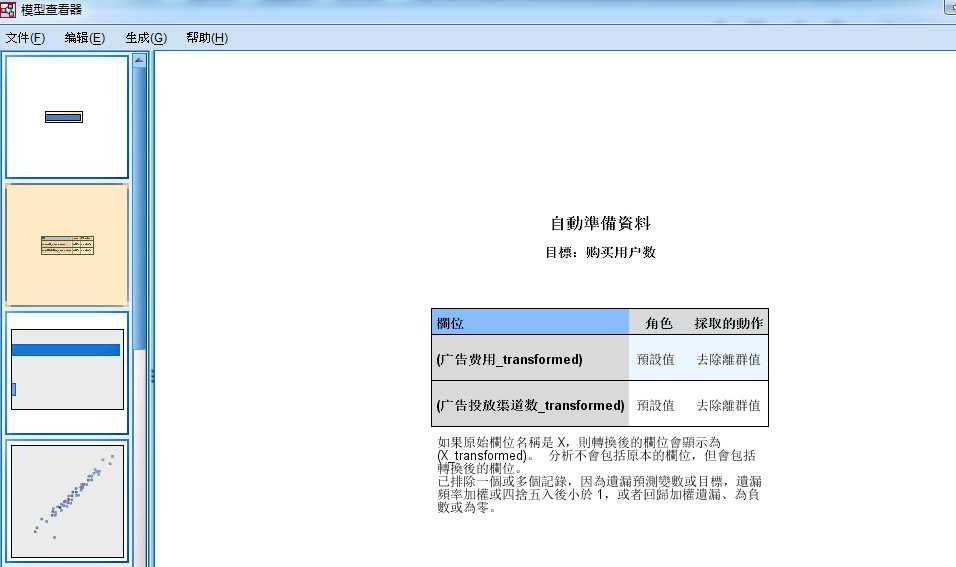
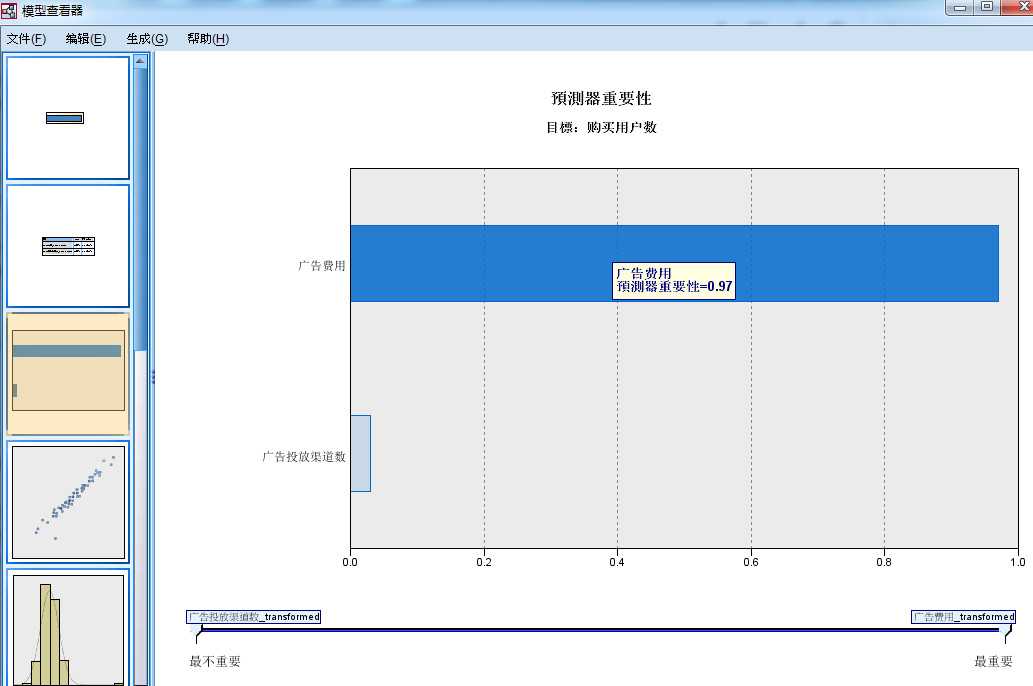
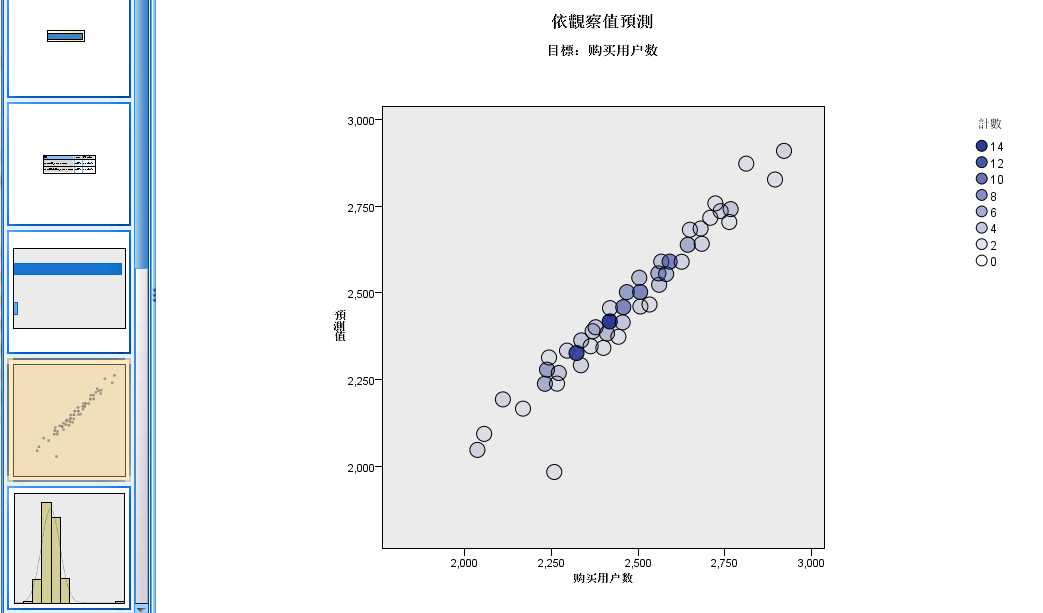
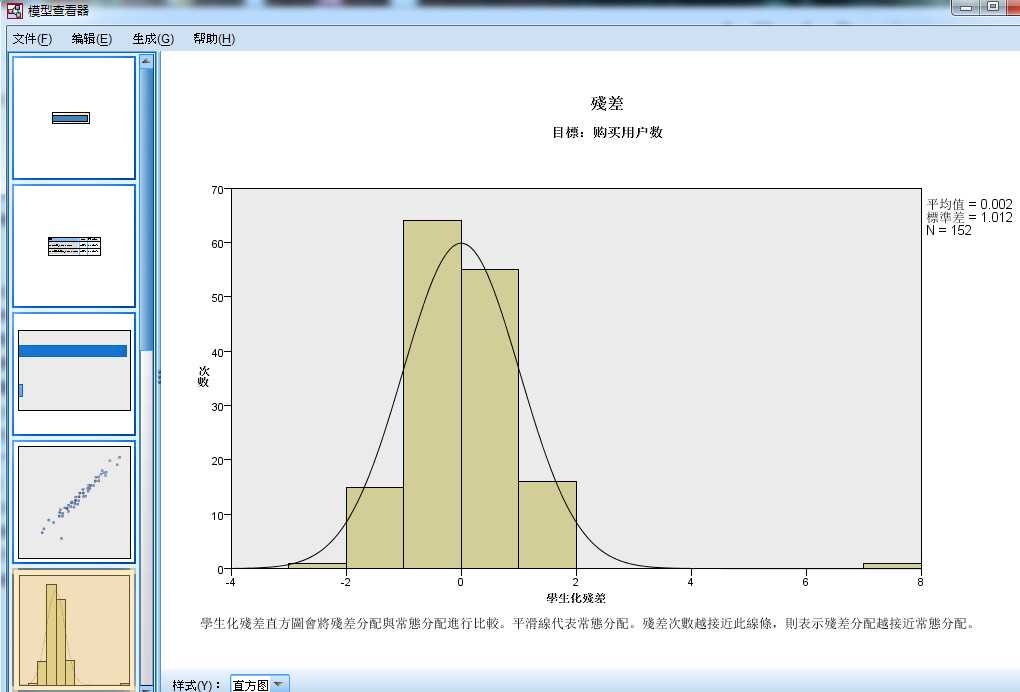
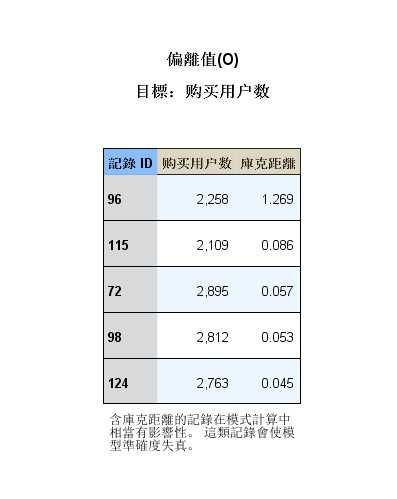 图 2-6 离群值
图 2-6 离群值