标签:改变 using 技术分享 mod keep 图片 搜索功能 全文检索 RoCE
全文检索简介
全文检索就是针对所有内容进行动态匹配搜索的概念,针对特定的关键词建立索引并精确匹配达到性能优化的目的
最常见的全文检索就是我们在数据库进行的模糊查询,但是模糊查询是针对整体的内容的一个动态匹配过程,在数据量较大的情况下匹配效率极低,常规项目中数据量一般都比较多并且内容繁杂,所以正常的项目搜索功能中很少使用模糊查询进行操作
首先安装全文检索管理模块haystack、全文搜索引擎模块whoosh和中文分词jieba
pip install haystack whoosh jieba
haystack作为一个全文检索管理模块应用,通过Django项目的配置文件中INSTALLED_APPS选项添加到项目中
INSTALLEDS_APPS=[ .. ‘haystack‘, #这个模块添加到所有子应用模块的前面 ]
修改Django项目配置文件,添加搜索引擎配置选项选项[项目settings.py配置文件]
HAYSTACK_CONNECTIONS = { ‘default‘: { #使用whoosh引擎 ‘ENGINE‘: ‘haystack.backends.whoosh_cn_backend.WhooshEngine‘, #索引文件路径 ‘PATH‘: os.path.join(BASE_DIR, ‘whoosh_index‘), } } #当添加、修改、删除数据时,自动生成索引 HAYSTACK_SIGNAL_PROCESSOR = ‘haystack.signals.RealtimeSignalProcessor‘
全文检索搜索过程是由haystack模块进行操作的,所以搜索路由操作交给haystack进行处理,修改路由配置如下:
.. urlptterns=[ .. url(r‘^search/$‘,include(‘haystack.urls)), ]
在应用目录下创建search_indexes.py模块文件,管理搜索的数据模型
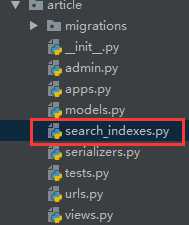
例如我这个 在article应用里新建 search_indexes.py
代码如下:
# 在应用模块下创建search_indexes.py模块文件,管理搜索的数据模型 from haystack import indexes from .models import ArticleInfo # 文章类的搜索类 class ArticleIndex(indexes.SearchIndex, indexes.Indexable): # 内容搜索 text = indexes.CharField(document=True, use_template=True) def get_model(self): return ArticleInfo # 返回要搜索的数据模型 def index_queryset(self, using=None): return self.get_model().objects.all()
注:搜素信息在哪张表上,就指定哪张表
在模板目录下创建templates/search/indexes/应用名/模型名称_text.txt文件,编辑可搜索内容
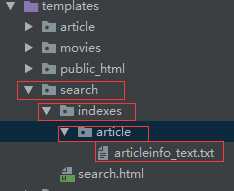
{{object.title}}
{{object.author}}
{{object.content}}
注:这里代表对这三指定字段进行搜索
在应用目录下创建templates/search/search.html展示结果页面
{% if query %}
<h3>搜索结果如下:</h3>
{% for result in page.object_list %}
<a href="/{{ result.object.id }}/">{{ result.object.title }}</a><br/>
{% empty %}
<p>啥也没找到</p>
{% endfor %}
{% if page.has_previous or page.has_next %}
<div>
{% if page.has_previous %}
<a href="?q={{ query }}&page={{ page.previous_page_number }}">
? 上一页</a>
{% else %}
? 上一页
{% endif %}
|
{% if page.has_next %}
<a href="?q={{ query }}&page={{ page.next_page_number }}">
下一页 ?</a>
{% else %}
下一页 ?
{% endif %}
</div>
{% endif %}
{% endif %}
注:我们的搜素结果将在这个页面进行渲染,注意上面的字段是否和你的数据库一致
在你的虚拟环境中找
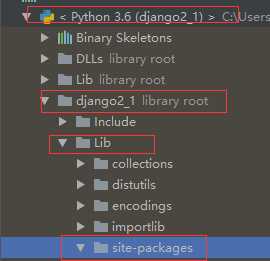
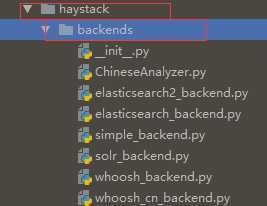
在上面的目录中创建ChineseAnalyzer.py文件,代码如下:
import jieba
from whoosh.analysis import Tokenizer, Token
class ChineseTokenizer(Tokenizer):
def __call__(self, value, positions=False, chars=False,
keeporiginal=False, removestops=True,
start_pos=0, start_char=0, mode=‘‘, **kwargs):
t = Token(positions, chars, removestops=removestops, mode=mode,
**kwargs)
seglist = jieba.cut(value, cut_all=True)
for w in seglist:
t.original = t.text = w
t.boost = 1.0
if positions:
t.pos = start_pos + value.find(w)
if chars:
t.startchar = start_char + value.find(w)
t.endchar = start_char + value.find(w) + len(w)
yield t
def ChineseAnalyzer():
return ChineseTokenizer()
然后,复制whoosh_backend.py文件,改为如下名称
whoosh_cn_backend.py
打开复制出来的新文件,引入中文分析类,内部采用结巴分词
查找 analyzer=StemmingAnalyzer() 改为 analyzer=ChineseAnalyzer()
1.9 初始化索引数据
python manage.py rebuild_index
按提示输入y后回车,生成索引

然后,
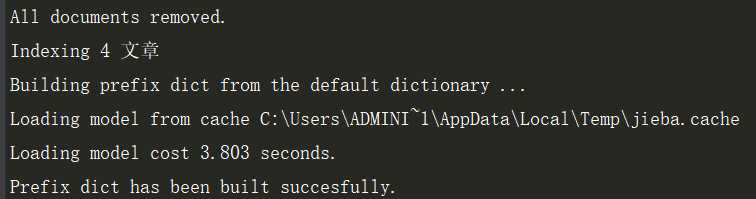
看见这个代表你以上的配置全部ok,恭喜你,索引生成后目录结构如下图

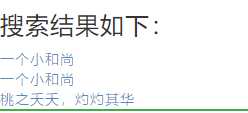
来,我们来测试一波,看看效果如何,先搜索。

看结果:
标签:改变 using 技术分享 mod keep 图片 搜索功能 全文检索 RoCE
原文地址:https://www.cnblogs.com/zbllly/p/10291496.html