标签:底层实现 博客 一个 element key length height des table
hashMap源码分析:hashMap源码分析
版本说明:jdk1.7
LinkedHashMap继承于HashMap,是一个有序的Map接口的实现。有序指的是元素可以按照一定的顺序排列,比如元素的插入顺序,或元素被访问的顺序。
LinkedHashMap的工作原理
说明:该图来源于其它博客,本人较懒,信手拈来,感谢!
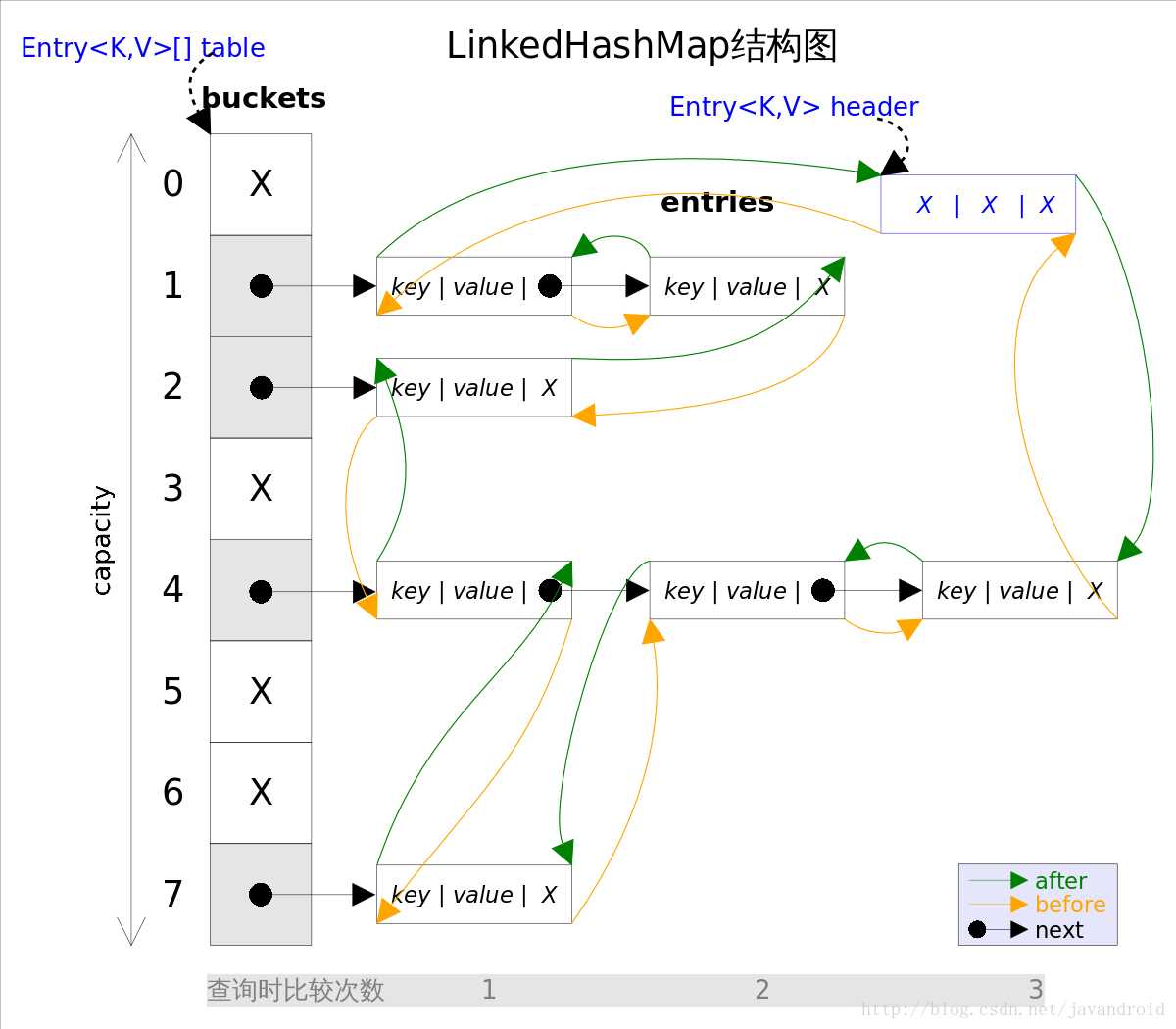
LinkedHashMap在存储数据时,和HashMap一样,也是先通过比较key的hashCode来定位数组中的位置,定位后,如果不存在冲突,则将元素插入到链表的尾部。只是,此时的链表是双向链表。
HashMap中Entry
static class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; Entry<K,V> next; int hash;
LinkedHashMap中的Entry
private static class Entry<K,V> extends HashMap.Entry<K,V> { //before和after指针(用于双向列表的迭代遍历) Entry<K,V> before, after;
除了继承自HashMap的属性外,LinkedHashMap还有自己特有的几个属性。
/** * The head of the doubly linked list. * 双向链表的头结点。整个LinkedHashMap中只有一个header, 它将哈希表中所有的Entry贯穿起来。header中不保存K-V对,只保存前后节点指针。 */ private transient Entry<K,V> header; /** * * 双向链表中元素排序规则的标志位。 * true:按访问顺序排序 * false:按插入顺序排序(默认) */ private final boolean accessOrder;
比HashMap多了一个重载的构造器,可以手动指定元素的排列顺序。
public LinkedHashMap(int initialCapacity, float loadFactor,boolean accessOrder) { super(initialCapacity, loadFactor); this.accessOrder = accessOrder; }
/** * Called by superclass constructors and pseudoconstructors (clone, * readObject) before any entries are inserted into the map. Initializes * the chain. * ??被父类的构造器和伪构造(clone,readObject)调用,当有元素插入之前掉用??(??不会翻译??) * 作用:初始化一个空的双向循环链表(头结点中不保存数据) */ @Override void init() { //初始化头节点。(不保存数据。所以,k=v=null,hash=-1表示不存在,next指针为null) header = new Entry<>(-1, null, null, null); //此时,将向前和向后的指针都指向头节点。 header.before = header.after = header; } /** * Transfers all entries to new table array. This method is called * by superclass resize. It is overridden for performance, as it is * faster to iterate using our linked list. * * 覆写了父类的transfer方法,被父类的resize方法调用。 * 扩容后,将k-v键值对重新映射到新的newTable中 * 覆写该方法的目的是为了提高复制的效率(这里充分利用双向循环链表的特点进行迭代,不用对底层的数组进行for循环。 */ @Override void transfer(HashMap.Entry[] newTable, boolean rehash) { int newCapacity = newTable.length; for (Entry<K,V> e = header.after; e != header; e = e.after) { if (rehash) e.hash = (e.key == null) ? 0 : hash(e.key); int index = indexFor(e.hash, newCapacity); e.next = newTable[index]; newTable[index] = e; } } /** * Returns <tt>true</tt> if this map maps one or more keys to the * specified value. * * @param value value whose presence in this map is to be tested * @return <tt>true</tt> if this map maps one or more keys to the * specified value * * 覆写HashMap中的containsValue方法, * 覆写该方法的目的同样是为了提高查询的效率, * 利用双向循环链表的特点进行查询,少了对数组的外层for循环 */ public boolean containsValue(Object value) { // Overridden to take advantage of faster iterator if (value==null) { for (Entry e = header.after; e != header; e = e.after) if (e.value==null) return true; } else { for (Entry e = header.after; e != header; e = e.after) if (value.equals(e.value)) return true; } return false; } /** * 覆写HashMap中的get方法,通过getEntry方法获取Entry对象。 * * 注意这里的recordAccess方法, * 如果链表中元素的排序规则是按照插入的先后顺序排序的话,该方法什么也不做, * 如果链表中元素的排序规则是按照访问的先后顺序排序的话,则将e移到链表的末尾处。 */ public V get(Object key) { Entry<K,V> e = (Entry<K,V>)getEntry(key); if (e == null) return null; e.recordAccess(this); return e.value; } /** * 清空双向列表 ,并将其还原为只有头结点的空链表 */ public void clear() { super.clear(); //前向指针和后向指针都指向头节点 header.before = header.after = header; } /** * LinkedHashMap中的Entry */ private static class Entry<K,V> extends HashMap.Entry<K,V> { //前向和后向指针(用于双向列表的元素查找) Entry<K,V> before, after; Entry(int hash, K key, V value, HashMap.Entry<K,V> next) { super(hash, key, value, next); } /** * 双向循环链表中,删除当前的Entry */ private void remove() { //当前节点的上一个节点的after指针指向下一个节点 before.after = after; //下一个节点的before指针指向当前节点的上一个节点 after.before = before; } /** * 双向循环立链表中,将当前的Entry插入到existingEntry的前面 */ private void addBefore(Entry<K,V> existingEntry) { after = existingEntry; before = existingEntry.before; before.after = this; after.before = this; } /** * This method is invoked by the superclass whenever the value * of a pre-existing entry is read by Map.get or modified by Map.set. * If the enclosing Map is access-ordered, it moves the entry * to the end of the list; otherwise, it does nothing. * * 覆写HashMap中的recordAccess方法(HashMap中该方法为空), * 当调用父类的put方法,在发现插入的key已经存在时,会调用该方法, * 调用LinkedHashmap覆写的get方法时,也会调用到该方法, * * 该方法提供了LRU算法的实现,它将最近使用的Entry放到双向循环链表的尾部, * accessOrder为true时,get方法会调用recordAccess方法 * put方法在覆盖key-value对时也会调用recordAccess方法 * 它们导致Entry最近使用,因此将其移到双向链表的末尾 */ void recordAccess(HashMap<K,V> m) { LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m; //如果设置的是按访问顺序来存储元素 if (lm.accessOrder) { lm.modCount++; //删除当前Entry remove(); //并将当前Entry添加到双向链表末尾 addBefore(lm.header); } } void recordRemoval(HashMap<K,V> m) { remove(); } } /** * 双向列表用到的迭代器 */ private abstract class LinkedHashIterator<T> implements Iterator<T> { Entry<K,V> nextEntry = header.after; Entry<K,V> lastReturned = null; /** * The modCount value that the iterator believes that the backing * List should have. If this expectation is violated, the iterator * has detected concurrent modification. */ int expectedModCount = modCount; public boolean hasNext() { return nextEntry != header; } public void remove() { if (lastReturned == null) throw new IllegalStateException(); if (modCount != expectedModCount) throw new ConcurrentModificationException(); LinkedHashMap.this.remove(lastReturned.key); lastReturned = null; expectedModCount = modCount; } Entry<K,V> nextEntry() { if (modCount != expectedModCount) throw new ConcurrentModificationException(); if (nextEntry == header) throw new NoSuchElementException(); Entry<K,V> e = lastReturned = nextEntry; nextEntry = e.after; return e; } } /** * key迭代器 */ private class KeyIterator extends LinkedHashIterator<K> { public K next() { return nextEntry().getKey(); } } /** * value迭代器 */ private class ValueIterator extends LinkedHashIterator<V> { public V next() { return nextEntry().value; } } /** * Entry迭代器 */ private class EntryIterator extends LinkedHashIterator<Map.Entry<K,V>> { public Map.Entry<K,V> next() { return nextEntry(); } } // These Overrides alter the behavior of superclass view iterator() methods Iterator<K> newKeyIterator() { return new KeyIterator(); } Iterator<V> newValueIterator() { return new ValueIterator(); } Iterator<Map.Entry<K,V>> newEntryIterator() { return new EntryIterator(); } /** * This override alters behavior of superclass put method. It causes newly * allocated entry to get inserted at the end of the linked list and * removes the eldest entry if appropriate. * * 覆写HashMap中的addEntry方法,LinkedHashmap并没有覆写HashMap中的put方法, * 而是覆写了put方法所调用的addEntry方法和recordAccess方法, * put方法在插入的key已存在时,会调用recordAccess方法,否则调用addEntry插入新的Entry */ void addEntry(int hash, K key, V value, int bucketIndex) { super.addEntry(hash, key, value, bucketIndex); // Remove eldest entry if instructed // 双向链表的第一个有效节点(header后的那个节点)为近期最少使用的节点 Entry<K,V> eldest = header.after; // 删除掉该近期最少使用的节点 if (removeEldestEntry(eldest)) { removeEntryForKey(eldest.key); } } /** * This override differs from addEntry in that it doesn‘t resize the * table or remove the eldest entry. */ void createEntry(int hash, K key, V value, int bucketIndex) { //创建新的Entry,并将其插入到数组对应槽的单链表的头结点处,这点与HashMap中相同 HashMap.Entry<K,V> old = table[bucketIndex]; Entry<K,V> e = new Entry<>(hash, key, value, old); table[bucketIndex] = e; //每次插入Entry时,都将其移到双向链表的尾部, //这便会按照Entry插入LinkedHashMap的先后顺序来迭代元素, //同时,新put进来的Entry是最近访问的Entry,把其放在链表末尾 ,符合LRU算法的实现 e.addBefore(header); size++; } /* * * 该方法是用来被覆写的,一般如果用LinkedHashmap实现LRU算法,就要覆写该方法, * 比如可以将该方法覆写为如果设定的内存已满,则返回true,这样当再次向LinkedHashMap中put * Entry时,在调用的addEntry方法中便会将近期最少使用的节点删除掉(header后的那个节点)。 */ protected boolean removeEldestEntry(Map.Entry<K,V> eldest) { return false; }
总结:
1.LinkedHashMap继承于HashMap。底层实现是使用数组+双向链表。
2.默认是按照元素添加的顺序来存储元素的。
如果accessOrder=true(按照元素被访问的方式来存储元素),则会使用LRU(Less Recent Used:最少最近被使用)算法,每次插入的元素都会插入到双向链表的尾部。因为插入元素就相当于访问了该元素。
3.LinkedHashMap同样是非线程安全的,只在单线程环境下使用。如果要多线程使用请使用Collections.synchronizedMap(new LinkedHashMap(…));
4.LinkedHashMap跟HashMap一样,允许key和value都为null。
标签:底层实现 博客 一个 element key length height des table
原文地址:https://www.cnblogs.com/rouqinglangzi/p/10291798.html