标签:style blog http os 使用 ar 文件 sp 2014
7,在SparkWorker1和SparkWorker2上完成和SparkMaster同样的Hadoop 2.2.0操作,建议使用SCP命令把SparkMaster上安装和配置的Hadoop的各项内容拷贝到SparkWorker1和SparkWorker2上;
8,启动并验证Hadoop分布式集群
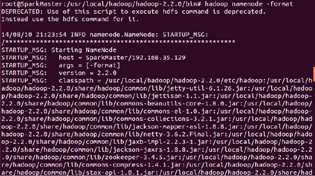
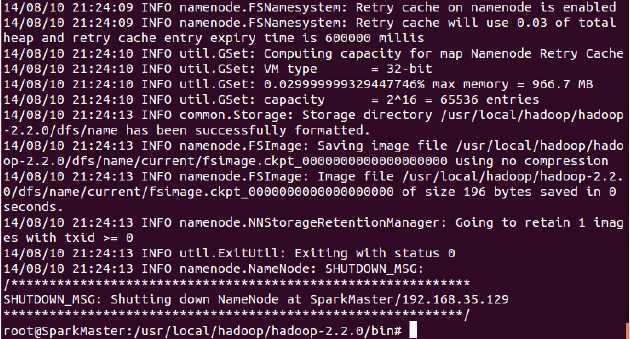
第一步:格式化hdfs文件系统:

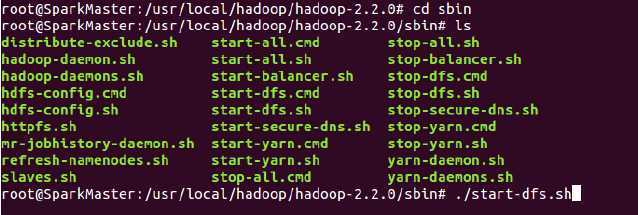
第二步:进入sbin中启动hdfs,执行如下命令:
启动过程如下:
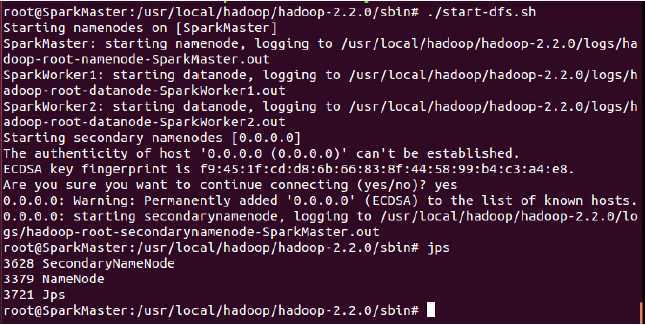
此时我们发现在SparkMaster上启动了NameNode和SecondaryNameNode;
在SparkWorker1和SparkWorker2上均启动了DataNode:


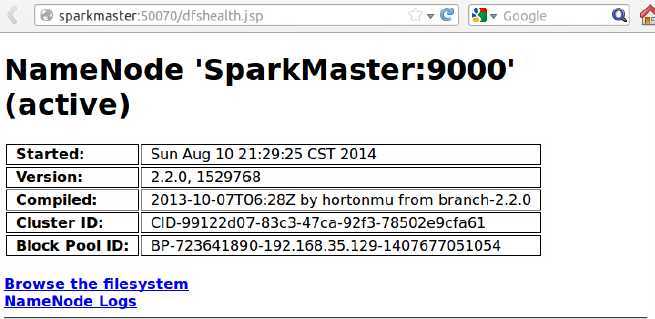
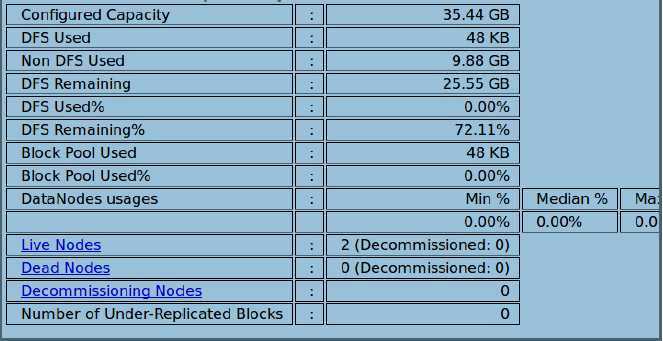
此时访问http://SparkMaster:50070 登录Web控制可以查看HDFS集群的状况:

【Spark亚太研究院系列丛书】Spark实战高手之路-第一章 构建Spark集群(第五步)(4)
标签:style blog http os 使用 ar 文件 sp 2014
原文地址:http://www.cnblogs.com/spark-china/p/4028641.html