标签:alter 获取 profile field 组件 均衡 sdn 表示 1.0
因公司业务需求,需要一个查询引擎满足快速查询TB级别的数据,所以我们找到了presto和impala,presto在前面讲过今天只说impala,impala是cloudera公司主导开发的新型查询系统,impala没有在使用缓慢的Hive+MapReduce批处理,而是通过使用商用并行的关系数据库类似的分布式查询引擎(由Query Planner,Query Coordinator和Query Exec Engine三部分组成),可以直接从HDFS 或者HBase中用SELECT,JOIN和统计函数查询数据,从而大大降低了延迟。并且impala在CDH中轻松部署、配置和维护。而且最重要的是impala查询速度快。这里使用impala的版本是v2.7.0-cdh5.10.0,cdh版本是Cloudera Enterprise Data Hub Edition 5.10.0 (#85 built by jenkins on 20170120-1038 git: aa0b5cd5eceaefe2f971c13ab657020d96bb842a)。
我们是使用CDH安装部署impala,在安装前,有的读者需要了解CDH的安装。这是官网链接:https://www.cloudera.com/documentation/enterprise/5-10-x.html 。都是英文,如果你们想找个中文,这是CDH安装文档链接(可以直接部署):https://download.csdn.net/download/u012720237/10266663。安装了CDH,在部署impala是很容易的。选择集群中的添加服务--》选择impala--》按照提示一步一步安装。
Impala Daemon
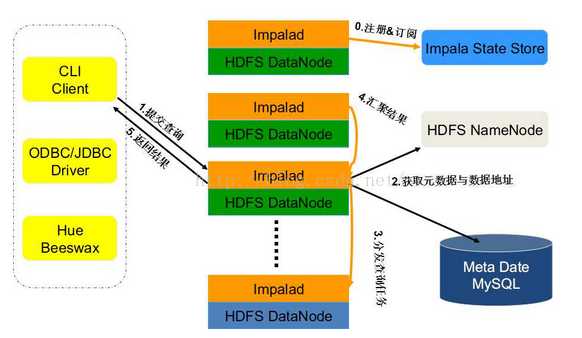
impala的核心组件是各个节点上面的impalad这个守护进程(Impala Daemon),它负责读写数据文件,接收从impala-shell,hue,JDBC,ODBC等接口发送的查询语句,并行化查询语句和分发工作任务到impala集群的各个节点上,同时负责把本地计算好的查询结果发送给协调器节点(coordinator node)。
你可以向运行在任意节点的impala deamon提交查询,这个节点将会作为这个查询的协调器(coordinator node),其他节点将会传输部分结果集给这个协调器节点。由这个协调器节点构建最终的结果集,所以一般而言在生产建议在不同的节点提交查询。使得集群负载均衡。
impala deamon不间断的和statestore进行通信交流,从而确认哪个节点是健康的能接受新的工作任务。它同时接收catalog daemon传来的广播消息来更新元数据信息,当集群中的任意节点create,alter,drop任意对象,或者执行insert,load data的时候出发广播消息。
Impala Statestore
这个组件检查集群中各个节点上impala daemon的健康状态,同时不间断地将结果反馈给impala daemon。这个服务的物理进程名称是statestored,在整个集群中我们仅需要一个这样的进程即可,这个进程可以增强集群的健壮性,他的启停不会影响其他节点的运行的任务,只会影响其他节点是否回向这个可能离线节点发送请求。
Impala Catalog
impala catalog服务奖SQL语句做出的元数据变化通知给集群各个节点,catalog服务的物理进程名称叫做catalogd,一个集群仅需要这个一个进程。由于他的请求会和statestore daemon交互,所以最好让statestored 和catalogd放在同一个节点上。
impalad分为java前端和c++处理后端,接受客户端链接的Impalad即作为这次查询的Coordinator,Coordinator通过JNI调用Java前端对用户的查询SQL进行分析生成执行计划树,不同的操作对应不同的PlanNode,如:SelectNode,ScanNode,SortNode,AggregationNode,HashJoinNode等。
执行计划树的每个原子操作由一个PlanFragment表示,通常一条查询语句由多个Plan Fragment组成, Plan Fragment 0表示执行树的根,汇聚结果返回给用户,执行树的叶子结点一般是Scan操作,分布式并行执行。
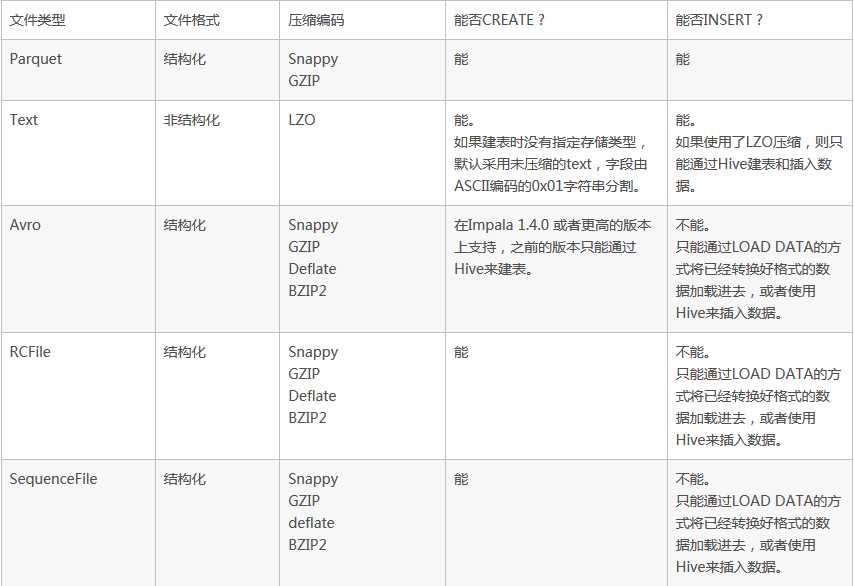
impala可以对Hadoop中大多数格式的文件进行查询。它能通过create table和insert的方式将一部分格式的数据记载到table中。但值得注意的是,有些格式的数据是无法写入的。对于无法写入的数据格式,我们只能通过Hive建表,通过对Hive进行数据的写入,然后使用impala对这些保存好的数据执行查询操作。
Impala支持的编码:
Snappy --推荐的编码,因为他在压缩率和解压速度之间有很好的平衡性,Snappy压缩速度很快,但是不如GZIP那样能节约更多的存储空间。impala不支持Snappy压缩的text file。
GZIP --压缩比很高能节约很多存储空间,impala不支持GZIP压缩的text file。
Deflate --impala不支持GZIP压缩的text file.
BZIP2 --impala不支持BZIP2压缩的text file.
LZO --只用于text file,Impala可以查询LZO压缩的text格式数据表,但是不支持insert数据,只能通过Hive来完成数据的insert。
优点:
1,支持SQL查询,快速查询大数据。
2,可以对已有数据进行查询,减少数据的加载,转换。
3,多种存储格式可以选择。
4,可以和hive配合使用。
缺点:
1,不支持用户定义函数UDF。
2,不支持text域的全文搜索。
3,不支持Transforms。
4,不支持查询期的容错。
5,对内存要求高。
|
选项 |
描述 |
|---|---|
|
-B or --delimited |
导致使用分隔符分割的普通文本格式打印查询结果。当为其他 Hadoop 组件生成数据时有用。对于避免整齐打印所有输出的性能开销有用,特别是使用查询返回大量的结果集进行基准测试的时候。使 用 --output_delimiter 选项指定分隔符。使用 -B 选项常用于保存所有查询结果到文件里而不是打印到屏幕上。在 Impala 1.0.1 中添加 |
|
--print_header |
是否打印列名。整齐打印时是默认启用。同时使用 -B 选项时,在首行打印列名 |
|
-o filename or --output_file filename |
保存所有查询结果到指定的文件。通常用于保存在命令行使用 -q 选项执行单个查询时的查询结果。对交互式会话同样生效;此时你只会看到获取了多 少行数据,但看不到实际的数据集。当结合使用 -q 和 -o 选项时,会自动将错误信息输出到 /dev/null(To suppress these incidental messages when combining the -q and -o options, redirect stderr to /dev/null)。在 Impala 1.0.1 中添加 |
|
--output_delimiter=character |
当使用 -B 选项以普通文件格式打印查询结果时,用于指定字段之间的分隔符(Specifies the character to use as a delimiter between fields when query results are printed in plain format by the -B option)。默认是制表符 tab (‘\t‘)。假如输出结果中包含了分隔符,该列会被引起且/或转义( If an output value contains the delimiter character, that field is quoted and/or escaped)。在 Impala 1.0.1 中添加 |
|
-p or --show_profiles |
对 shell 中执行的每一个查询,显示其查询执行计划 (与 EXPLAIN 语句输出相同) 和发生低级故障(low-level breakdown)的执行步骤的更详细的信息 |
|
-h or --help |
显示帮助信息 |
|
-i hostname or --impalad=hostname |
指定连接运行 impalad 守护进程的主机。默认端口是 21000。你可以连接到集群中运行 impalad 的任意主机。假如你连接到 impalad 实例通过 --fe_port 标志使用了其他端口,则应当同时提供端口号,格式为 hostname:port |
|
-q query or --query=query |
从命令行中传递一个查询或其他 shell 命令。执行完这一语句后 shell 会立即退出。限制为单条语句,可以是 SELECT, CREATE TABLE, SHOW TABLES, 或其他 impala-shell 认可的语句。因为无法传递 USE 语句再加上其他查询,对于 default 数据库之外的表,应在表名前加上数据库标识符(或者使用 -f 选项传递一个包含 USE 语句和其他查询的文件) |
|
-f query_file or --query_file=query_file |
传递一个文件中的 SQL 查询。文件内容必须以分号分隔 |
|
-k or --kerberos |
当连接到 impalad 时使用 Kerberos 认证。如果要连接的 impalad 实例不支持 Kerberos,将显示一个错误 |
|
-s kerberos_service_name or --kerberos_service_name=name |
Instructs impala-shell to authenticate to a particular impalad service principal. 如何没有设置 kerberos_service_name ,默认使用 impala。如何启用了本选项,而试图建立不支持Kerberos 的连接时,返回一个错误(If this option is used in conjunction with a connection in which Kerberos is not supported, errors are returned) |
|
-V or --verbose |
启用详细输出 |
|
--quiet |
关闭详细输出 |
|
-v or --version |
显示版本信息 |
|
-c |
查询执行失败时继续执行 |
|
-r or --refresh_after_connect |
建立连接后刷新 Impala 元数据,与建立连接后执行 REFRESH 语句效果相同 |
|
-d default_db or --database=default_db |
指定启动后使用的数据库,与建立连接后使用 USE 语句选择数据库作用相同,如果没有指定,那么使用 default 数据库 |
| -l | 启用 LDAP 认证 |
| -u | 当使用 -l 选项启用 LDAP 认证时,提供用户名(使用短用户名,而不是完整的 LDAP 专有名称(distinguished name)) ,shell 会提示输入密码 |
标签:alter 获取 profile field 组件 均衡 sdn 表示 1.0
原文地址:https://www.cnblogs.com/boanxin/p/10294357.html