标签:理解 重要 blog ted 基本 被占用 来讲 hash nbsp
来自 https://www.cnblogs.com/chengxiao/p/6059914.html
为了更好的理解 https://blog.csdn.net/ted_cs/article/details/82881831 (O(1), O(n), O(logn), O(nlogn) 的区别)
数组:采用一段连续的存储单元来存储数据。对于指定下标的查找,时间复杂度为O(1);通过给定值进行查找,需要遍历数组,逐一比对给定关键字和数组元素,时间复杂度为O(n),当然,对于有序数组,则可采用二分查找,插值查找,斐波那契查找等方式,可将查找复杂度提高为O(logn);对于一般的插入删除操作,涉及到数组元素的移动,其平均复杂度也为O(n)
线性链表:对于链表的新增,删除等操作(在找到指定操作位置后),仅需处理结点间的引用即可,时间复杂度为O(1),而查找操作需要遍历链表逐一进行比对,复杂度为O(n)
二叉树:对一棵相对平衡的有序二叉树,对其进行插入,查找,删除等操作,平均复杂度均为O(logn)。
哈希表:相比上述几种数据结构,在哈希表中进行添加,删除,查找等操作,性能十分之高,不考虑哈希冲突的情况下,仅需一次定位即可完成,时间复杂度为O(1),接下来我们就来看看哈希表是如何实现达到惊艳的常数阶O(1)的。
我们知道,数据结构的物理存储结构只有两种:顺序存储结构和链式存储结构(像栈,队列,树,图等是从逻辑结构去抽象的,映射到内存中,也这两种物理组织形式),而在上面我们提到过,在数组中根据下标查找某个元素,一次定位就可以达到,哈希表利用了这种特性,哈希表的主干就是数组。
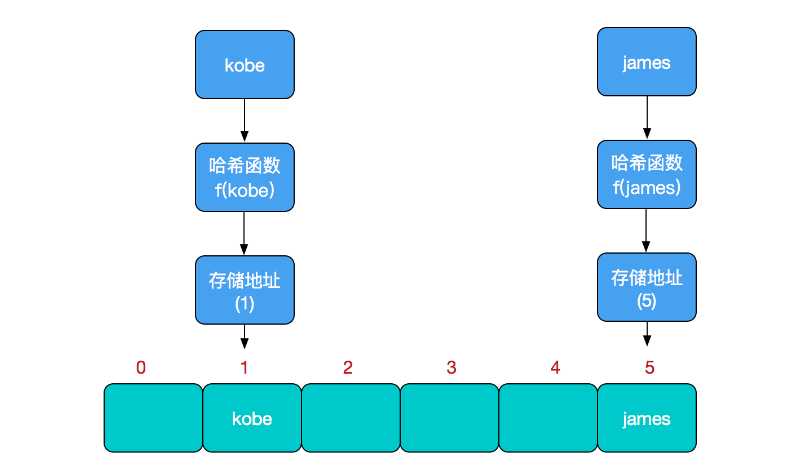
比如我们要新增或查找某个元素,我们通过把当前元素的关键字 通过某个函数映射到数组中的某个位置,通过数组下标一次定位就可完成操作。
存储位置 = f(关键字)
其中,这个函数f一般称为哈希函数,这个函数的设计好坏会直接影响到哈希表的优劣。举个例子,比如我们要在哈希表中执行插入操作:
哈希冲突
然而万事无完美,如果两个不同的元素,通过哈希函数得出的实际存储地址相同怎么办?也就是说,当我们对某个元素进行哈希运算,得到一个存储地址,然后要进行插入的时候,发现已经被其他元素占用了,其实这就是所谓的哈希冲突,也叫哈希碰撞。前面我们提到过,哈希函数的设计至关重要,好的哈希函数会尽可能地保证 计算简单和散列地址分布均匀,但是,我们需要清楚的是,数组是一块连续的固定长度的内存空间,再好的哈希函数也不能保证得到的存储地址绝对不发生冲突。那么哈希冲突如何解决呢?哈希冲突的解决方案有多种:开放定址法(发生冲突,继续寻找下一块未被占用的存储地址),再散列函数法,链地址法,而HashMap即是采用了链地址法,也就是数组+链表的方式。
HashMap的主干是一个Entry数组。Entry是HashMap的基本组成单元,每一个Entry包含一个key-value键值对。
HashMap的整体结构如下
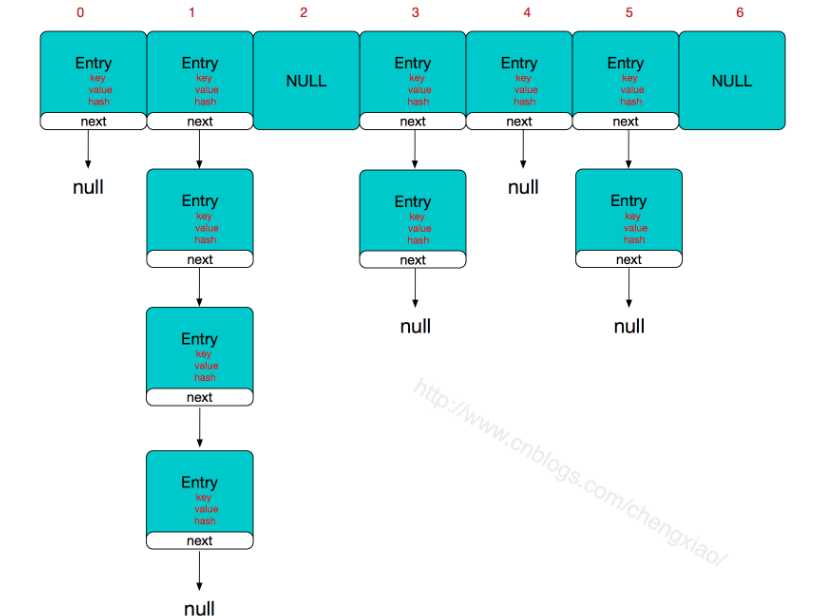
 简单来说,HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的,如果定位到的数组位置不含链表(当前entry的next指向null),那么对于查找,添加等操作很快,仅需一次寻址即可;如果定位到的数组包含链表,对于添加操作,其时间复杂度为O(n),首先遍历链表,存在即覆盖,否则新增;对于查找操作来讲,仍需遍历链表,然后通过key对象的equals方法逐一比对查找。所以,性能考虑,HashMap中的链表出现越少,性能才会越好。
简单来说,HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的,如果定位到的数组位置不含链表(当前entry的next指向null),那么对于查找,添加等操作很快,仅需一次寻址即可;如果定位到的数组包含链表,对于添加操作,其时间复杂度为O(n),首先遍历链表,存在即覆盖,否则新增;对于查找操作来讲,仍需遍历链表,然后通过key对象的equals方法逐一比对查找。所以,性能考虑,HashMap中的链表出现越少,性能才会越好。
标签:理解 重要 blog ted 基本 被占用 来讲 hash nbsp
原文地址:https://www.cnblogs.com/zhangqb/p/10297882.html