标签:-- moni url 更新 lan let gen hdf 补充
kudu 1.7

官方:https://kudu.apache.org/
kudu有很多概念,有分布式文件系统(HDFS),有一致性算法(Zookeeper),有Table(Hive Table),有Tablet(Hive Table Partition),有列式存储(Parquet),有顺序和随机读取(HBase),所以看起来kudu是一个轻量级的 HDFS + Zookeeper + Hive + Parquet + HBase,除此之外,kudu还有自己的特点,快速写入+读取,使得kudu+impala非常适合OLAP场景,尤其是Time-series场景。
A new addition to the open source Apache Hadoop ecosystem, Apache Kudu completes Hadoop‘s storage layer to enable fast analytics on fast data.
kudu是hadoop生态的有力补充,使得hadoop存储层也可以支持快速变化数据上的快速分析;
kudu提供了快速写入更新的能力和高效列式扫描的能力,使得直接在存储层上实现实时分析成为可能,简化了传统技术栈;
kudu被设计为尤其适合在快速变化的数据上进行快速分析的场景,利用下一代硬件以及内存处理的优势,kudu降低了impala和spark的查询延迟;
Kudu is a columnar storage manager developed for the Apache Hadoop platform. Kudu shares the common technical properties of Hadoop ecosystem applications: it runs on commodity hardware, is horizontally scalable, and supports highly available operation.
kudu是一个hadoop平台的列式存储层,它继承了hadoop生态的技术特点:通用硬件、水平扩展、高可用;
Kudu’s design sets it apart. Some of Kudu’s benefits include:
kudu有以上诸多特点:快速OLAP、整合其他hadoop生态组件(比如spark)、整合Impala、快速顺序和随机读取、可配置的数据一致性、高可用、结构化数据模型;
By combining all of these properties, Kudu targets support for families of applications that are difficult or impossible to implement on current generation Hadoop storage technologies. A few examples of applications for which Kudu is a great solution are:
当kudu有了以上特点之后,使得传统hadoop存储技术很难解决的一些场景成为可能,比如:数据快速变化的报表系统、Timer-series应用、实时决策系统;
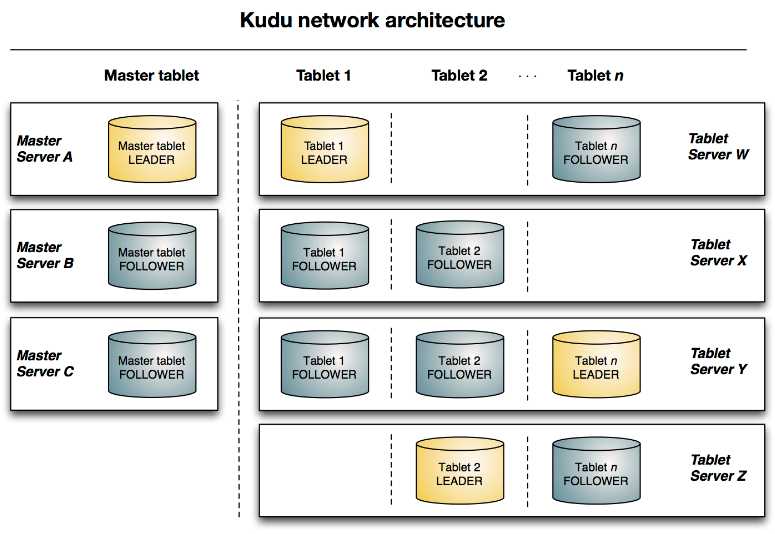
A table is where your data is stored in Kudu. A table has a schema and a totally ordered primary key. A table is split into segments called tablets.
Table(类似于hive或hbase的table),有schema和primary key,可以划分为多个Tablet;
A tablet is a contiguous segment of a table, similar to a partition in other data storage engines or relational databases. A given tablet is replicated on multiple tablet servers, and at any given point in time, one of these replicas is considered the leader tablet. Any replica can service reads, and writes require consensus among the set of tablet servers serving the tablet.
Tablet(类似于hive中的partition或hbase中的region),tablet是多副本的,存放在多个tablet server上,多个副本中有一个是leader tablet;所有的副本都可以读,但是写操作只有leader可以,写操作利用一致性算法(Raft);
A tablet server stores and serves tablets to clients. For a given tablet, one tablet server acts as a leader, and the others act as follower replicas of that tablet. Only leaders service write requests, while leaders or followers each service read requests. Leaders are elected using Raft Consensus Algorithm. One tablet server can serve multiple tablets, and one tablet can be served by multiple tablet servers.
tablet server(类似于hbase中的region server),存放tablet并且相应client请求;一个tablet server存放多个tablet;
The catalog table is the central location for metadata of Kudu. It stores information about tables and tablets. The catalog table may not be read or written directly. Instead, it is accessible only via metadata operations exposed in the client API.
The catalog table stores two categories of metadata: Tables & Tablets
catalog table存放kudu的metadata(类似于hive和hbase中的metadata),catalog table包含两类metadata:Tables和Tablets
The master keeps track of all the tablets, tablet servers, the Catalog Table, and other metadata related to the cluster. At a given point in time, there can only be one acting master (the leader). If the current leader disappears, a new master is elected using Raft Consensus Algorithm.
The master also coordinates metadata operations for clients. For example, when creating a new table, the client internally sends the request to the master. The master writes the metadata for the new table into the catalog table, and coordinates the process of creating tablets on the tablet servers.
All the master’s data is stored in a tablet, which can be replicated to all the other candidate masters.
Tablet servers heartbeat to the master at a set interval (the default is once per second).
master(类似于hdfs和hbase的master),负责管理所有的tablet、tablet server、catalog table以及其他元数据。同一时间集群中只有一个acting master(leader master),如果leader master挂了,一个新的master会通过Raft算法选举出来。
所有的master数据都存放在一个tablet中,这个tablet会被复制到所有的candidate master上;
tablet server会定期向master发送心跳。
Kudu uses the Raft consensus algorithm as a means to guarantee fault-tolerance and consistency, both for regular tablets and for master data. Through Raft, multiple replicas of a tablet elect a leader, which is responsible for accepting and replicating writes to follower replicas. Once a write is persisted in a majority of replicas it is acknowledged to the client. A given group of N replicas (usually 3 or 5) is able to accept writes with at most (N - 1)/2 faulty replicas.
kudu通过Raft一致性算法(类似于zookeeper中的Paxos算法)来保证tablet和master数据的容错性和一致性。详见:https://raft.github.io/
Kudu replicates operations, not on-disk data. This is referred to as logical replication, as opposed to physical replication.
kudu使用的是逻辑副本的概念。
详见:https://www.cnblogs.com/quchunhui/p/7658853.html
# cat /etc/yum.repos.d/cdh.repo
[cloudera-cdh5]
# Packages for Cloudera‘s Distribution for Hadoop, Version 5, on RedHat or CentOS 7 x86_64
name=Cloudera‘s Distribution for Hadoop, Version 5
baseurl=https://archive.cloudera.com/cdh5/redhat/7/x86_64/cdh/5/
gpgkey =https://archive.cloudera.com/cdh5/redhat/7/x86_64/cdh/RPM-GPG-KEY-cloudera
gpgcheck = 1
这里没有指定版本,默认会安装最新
# yum install kudu kudu-master kudu-client0 kudu-client-devel
配置文件
/etc/kudu/conf/master.gflagfile
可以修改数据路径
启动,可以启动多个master
# service kudu-master start
# yum install kudu kudu-tserver kudu-client0 kudu-client-devel
配置文件
/etc/kudu/conf/tserver.gflagfile
修改master地址,可以配置多个
--tserver_master_addrs=$master_server:7051
启动
# service kudu-tserver start
通过impala-shell读写数据
[$impala_server:21000] >
CREATE TABLE impala.test_kudu (
id INT,
name STRING,
PRIMARY KEY (id)
)
PARTITION BY HASH (id) PARTITIONS 4
STORED AS KUDU
TBLPROPERTIES (‘kudu.master_addresses‘=‘$kudu_master:7051‘);
[$impala_server:21000] > select * from test_kudu;
Query: select * from test_kudu
Query submitted at: 2019-01-21 12:53:04 (Coordinator: http://$impala_server:25000)
Query progress can be monitored at: http://$impala_server:25000/query_plan?query_id=e345f450c0dca86a:4769860f00000000
+----+-------+
| id | name |
+----+-------+
| 1 | test |
+----+-------+
Fetched 1 row(s) in 0.13s
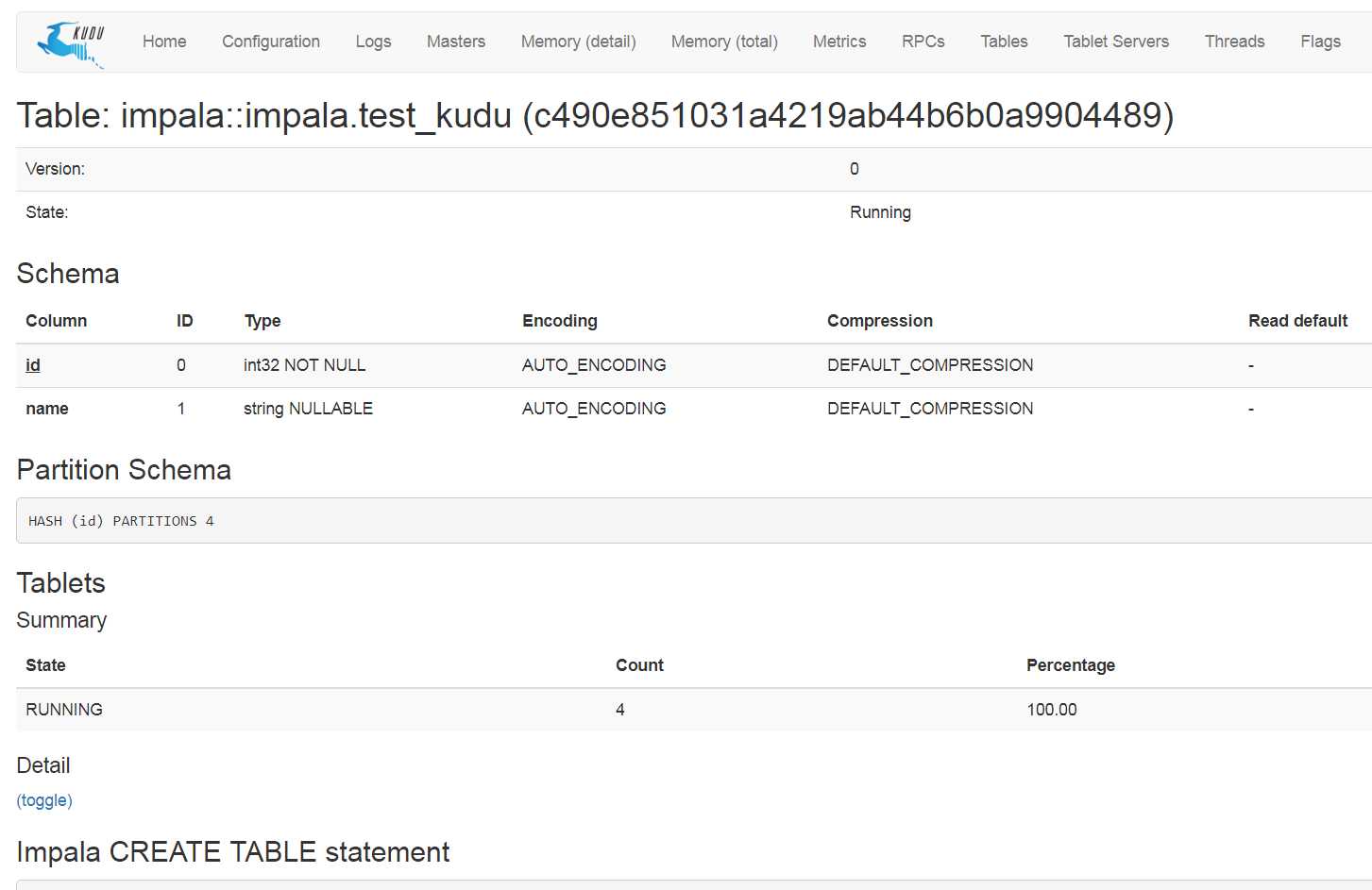
同时可以在kudu中看到新创建的表
标签:-- moni url 更新 lan let gen hdf 补充
原文地址:https://www.cnblogs.com/barneywill/p/10296475.html