标签:模型 pre dac 应用 图片 开源软件 云栖大会 蓝色 匹配
日前,阿里巴巴正式对外发布了分布式科学计算引擎 Mars 的开源代码地址,开发者们可以在pypi上自主下载安装,或在Github上获取源代码并参与开发。此前,早在2018年9月的杭州云栖大会上,阿里巴巴就公布了这项开源计划。Mars 突破了现有大数据计算引擎的关系代数为主的计算模型,将分布式技术引入科学计算/数值计算领域,极大地扩展了科学计算的计算规模和效率。目前已应用于阿里巴巴及其云上客户的业务和生产场景。本文将为大家详细介绍Mars的设计初衷和技术架构。
概述
科学计算即数值计算,是指应用计算机处理科学研究和工程技术中所遇到的数学计算问题。比如图像处理、机器学习、深度学习等很多领域都会用到科学计算。有很多语言和库都提供了科学计算工具。这其中,Numpy以其简洁易用的语法和强大的性能成为佼佼者,并以此为基础形成了庞大的技术栈。(下图所示)
Numpy的核心概念多维数组是各种上层工具的基础。多维数组也被称为张量,相较于二维表/矩阵,张量具有更强大的表达能力。因此,现在流行的深度学习框架也都广泛的基于张量的数据结构。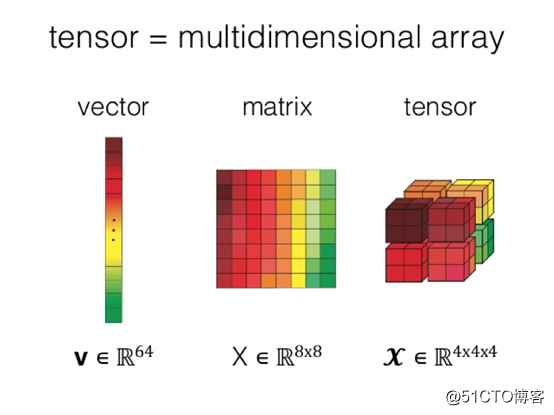
随着机器学习/深度学习的热潮,张量的概念已逐渐为人所熟知,对张量进行通用计算的规模需求也与日俱增。但现实是如Numpy这样优秀的科学计算库仍旧停留在单机时代,无法突破规模瓶颈。当下流行的分布式计算引擎也并非为科学计算而生,上层接口不匹配导致科学计算任务很难用传统的SQL/MapReduce编写,执行引擎本身没有针对科学计算优化更使得计算效率难以令人满意。
基于以上科学计算现状,由阿里巴巴统一大数据计算平台MaxCompute研发团队,历经1年多研发,打破大数据、科学计算领域边界,完成第一个版本并开源。 Mars,一个基于张量的统一分布式计算框架。使用 Mars 进行科学计算,不仅使得完成大规模科学计算任务从MapReduce实现上千行代码降低到Mars数行代码,更在性能上有大幅提升。目前,Mars 实现了 tensor 的部分,即numpy 分布式化, 实现了 70% 常见的 numpy 接口。后续,在 Mars 0.2 的版本中, 正在将 pandas 分布式化,即将提供完全兼容 pandas 的接口,以构建整个生态。
Mars作为新一代超大规模科学计算引擎,不仅普惠科学计算进入分布式时代,更让大数据进行高效的科学计算成为可能。
Mars的核心能力
符合使用习惯的接口
Mars 通过 tensor 模块提供兼容 Numpy 的接口,用户可以将已有的基于 Numpy 编写的代码,只需替换 import,就可将代码逻辑移植到 Mars,并直接获得比原来大数万倍规模,同时处理能力提高数十倍的能力。目前,Mars 实现了大约 70% 的常见 Numpy 接口。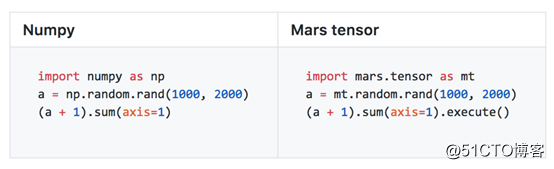
充分利用GPU加速
除此之外,Mars 还扩展了 Numpy,充分利用了GPU在科学计算领域的已有成果。创建张量时,通过指定 gpu=True 就可以让后续计算在GPU上执行。比如:
a = mt.random.rand(1000, 2000, gpu=True) # 指定在 GPU 上创建
(a + 1).sum(axis=1).execute()
稀疏矩阵
Mars 还支持二维稀疏矩阵,创建稀疏矩阵的时候,通过指定 sparse=True 即可。以eye 接口为例,它创建了一个单位对角矩阵,这个矩阵只有对角线上有值,其他位置上都是 0,所以,我们可以用稀疏的方式存储。
a = mt.eye(1000, sparse=True) # 指定创建稀疏矩阵
(a + 1).sum(axis=1).execute()
系统设计
接下来介绍 Mars 的系统设计,让大家了解 Mars 是如何让科学计算任务自动并行化并拥有强大的性能。
分而治之—tile
Mars 通常对科学计算任务采用分而治之的方式。给定一个张量,Mars 会自动将其在各个维度上切分成小的 Chunk 来分别处理。对于 Mars 实现的所有的算子,都支持自动切分任务并行。这个自动切分的过程在Mars里被称为 tile。
比如,给定一个 1000 2000 的张量,如果每个维度上的 chunk 大小为 500,那么这个张量就会被 tile 成 2 4 一共 8 个 chunk。对于后续的算子,比如加法(Add)和求和(SUM),也都会自动执行 tile 操作。一个张量的运算的 tile 过程如下图所示。
延迟执行和 Fusion 优化
目前 Mars 编写的代码需要显式调用 execute 触发,这是基于 Mars 的延迟执行机制。用户在写中间代码时,并不会需要任何的实际数据计算。这样的好处是可以对中间过程做更多优化,让整个任务的执行更优。目前 Mars 里主要用到了 fusion 优化,即把多个操作合并成一个执行。
对于前面一个图的例子,在 tile 完成之后,Mars 会对细粒度的 Chunk 级别图进行 fusion 优化,比如8个 RAND+ADD+SUM,每个可以被分别合并成一个节点,一方面可以通过调用如 numexpr 库来生成加速代码,另一方面,减少实际运行节点的数量也可以有效减少调度执行图的开销。
多种调度方式
Mars 支持多种调度方式:
| 多线程模式:Mars 可以使用多线程来在本地调度执行 Chunk 级别的图。对于 Numpy 来说,大部分算子都是使用单线程执行,仅使用这种调度方式,也可以使得 Mars 在单机即可获得 tile 化的执行图的能力,突破 Numpy 的单机内存限制,同时充分利用单机所有 CPU/GPU 资源,获得比 Numpy 快数倍的性能。
| 单机集群模式: Mars 可以在单机启动整个分布式运行时,利用多进程来加速任务的执行;这种模式适合模拟面向分布式环境的开发调试。
| 分布式 : Mars 可以启动一个或者多个 scheduler,以及多个 worker,scheduler 会调度 Chunk 级别的算子到各个 worker 去执行。
下图是 Mars 分布式的执行架构:
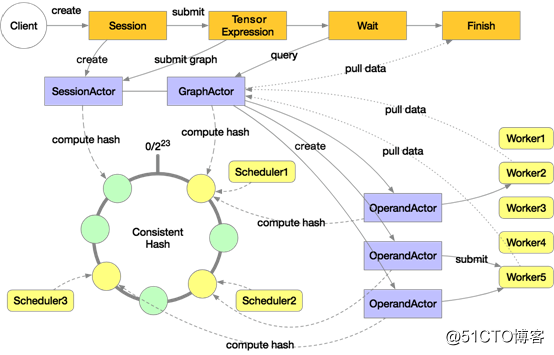
Mars 分布式执行时会启动多个 scheduler 和 多个 worker,图中是3个 scheduler 和5个 worker,这些 scheduler 组成一致性哈希环。用户在客户端显式或隐式创建一个 session,会根据一致性哈希在其中一个 scheduler 上分配 SessionActor,然后用户通过 execute 提交了一个张量的计算,会创建 GraphActor 来管理这个张量的执行,这个张量会在 GraphActor 中被 tile 成 chunk 级别的图。这里假设有3个 chunk,那么会在 scheduler 上创建3个 OperandActor 分别对应。这些 OperandActor 会根据自己的依赖是否完成、以及集群资源是否足够来提交到各个 worker 上执行。在所有 OperandActor 都完成后会通知 GraphActor 任务完成,然后客户端就可以拉取数据来展示或者绘图。
向内和向外伸缩
Mars 灵活的 tile 化执行图配合多种调度模式,可以使得相同的 Mars 编写的代码随意向内(scale in)和向外(scale out)伸缩。向内伸缩到单机,可以利用多核来并行执行科学计算任务;向外伸缩到分布式集群,可以支持到上千台 worker 规模来完成单机无论如何都难以完成的任务。
Benchmark
在一个真实的场景中,我们遇到了巨型矩阵乘法的计算需求,需要完成两个均为千亿元素,大小约为2.25T的矩阵相乘。Mars通过5行代码,使用1600 CU(200个 worker,每 worker 为 8核 32G内存),在2个半小时内完成计算。在此之前,同类计算只能使用 MapReduce 编写千余行代码模拟进行,完成同样的任务需要动用 9000 CU 并耗时10个小时。
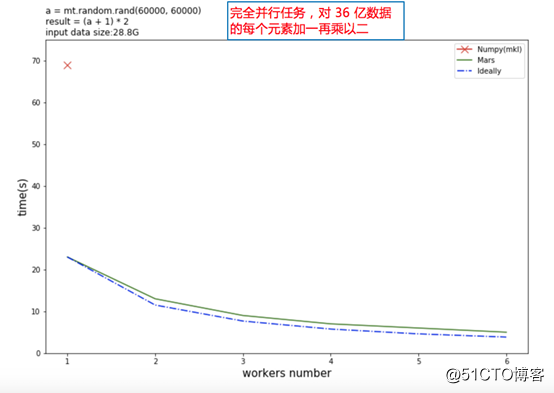
让我们再看两个对比。下图是对36亿数据矩阵的每个元素加一再乘以二,红色的叉表示 Numpy 的计算时间,绿色的实线是 Mars 的计算时间,蓝色虚线是理论计算时间。可以看到单机 Mars 就比 Numpy 快数倍,随着 Worker 的增加,可以获得几乎线性的加速比。
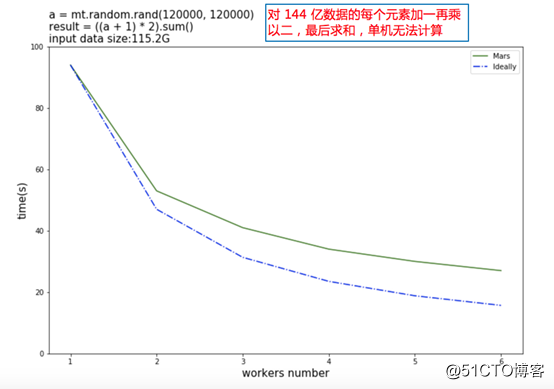
下图是进一步扩大计算规模,把数据扩大到144亿元素,对这些元素加一乘以二以后再求和。这时候输入数据就有 115G,单机的 Numpy 已经无法完成运算,Mars 依然可以完成运算,且随着机器的增多可以获得还不错的加速比。
开源地址
Mars 已经在 Github 开源:https://github.com/mars-project/mars ,且后续会全部在 Github 上使用标准开源软件的方式来进行开发,欢迎大家使用 Mars,并成为 Mars 的 contributor。
阿里重磅开源首款自研科学计算引擎Mars,揭秘超大规模科学计算
标签:模型 pre dac 应用 图片 开源软件 云栖大会 蓝色 匹配
原文地址:http://blog.51cto.com/14031893/2345096