标签:首页 链接 图片 没有 网络 robot ide 就是 模拟浏览器访问
一、爬虫介绍
网络爬虫,即Web Spider,是一个很形象的名字。如果把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛。网络蜘蛛是通过网页的链接地址来寻找网页的。从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。
爬虫就是一个程序模拟浏览器访问呢服务器获取动态资源
二、rebots.txt协议
如果自己的门户网站中的指定页面中的数据不想让爬虫程序爬取到的话,那么则可以通过编写一个robots.txt的协议文件来约束爬虫程序的数据爬取。robots协议的编写格式可以观察淘宝网的robots(访问www.taobao.com/robots.txt即可)。但是需要注意的是,该协议只是相当于口头的协议,并没有使用相关技术进行强制管制,所以该协议是防君子不防小人。
三、爬虫的流程
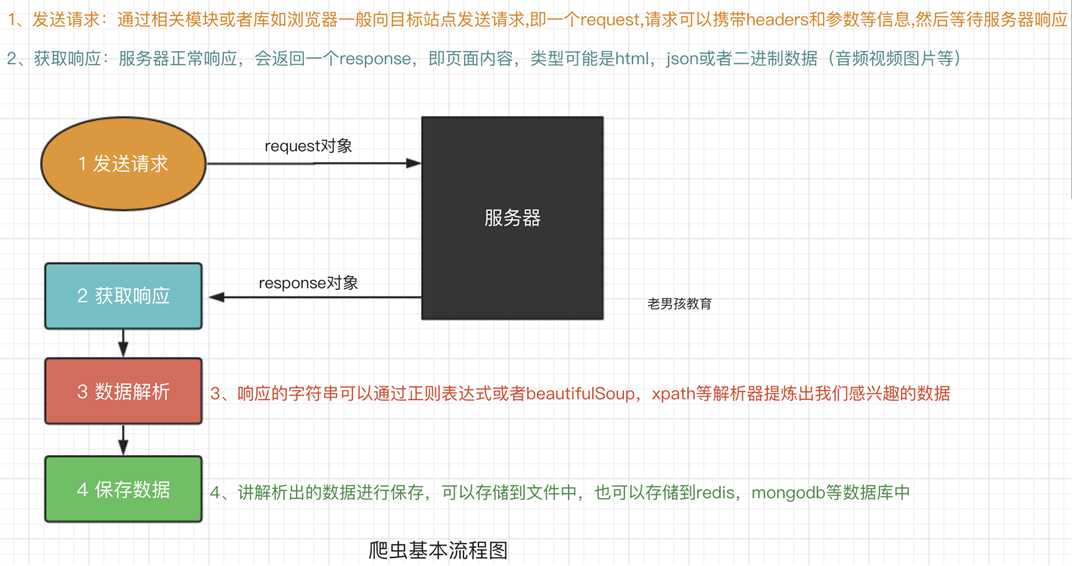
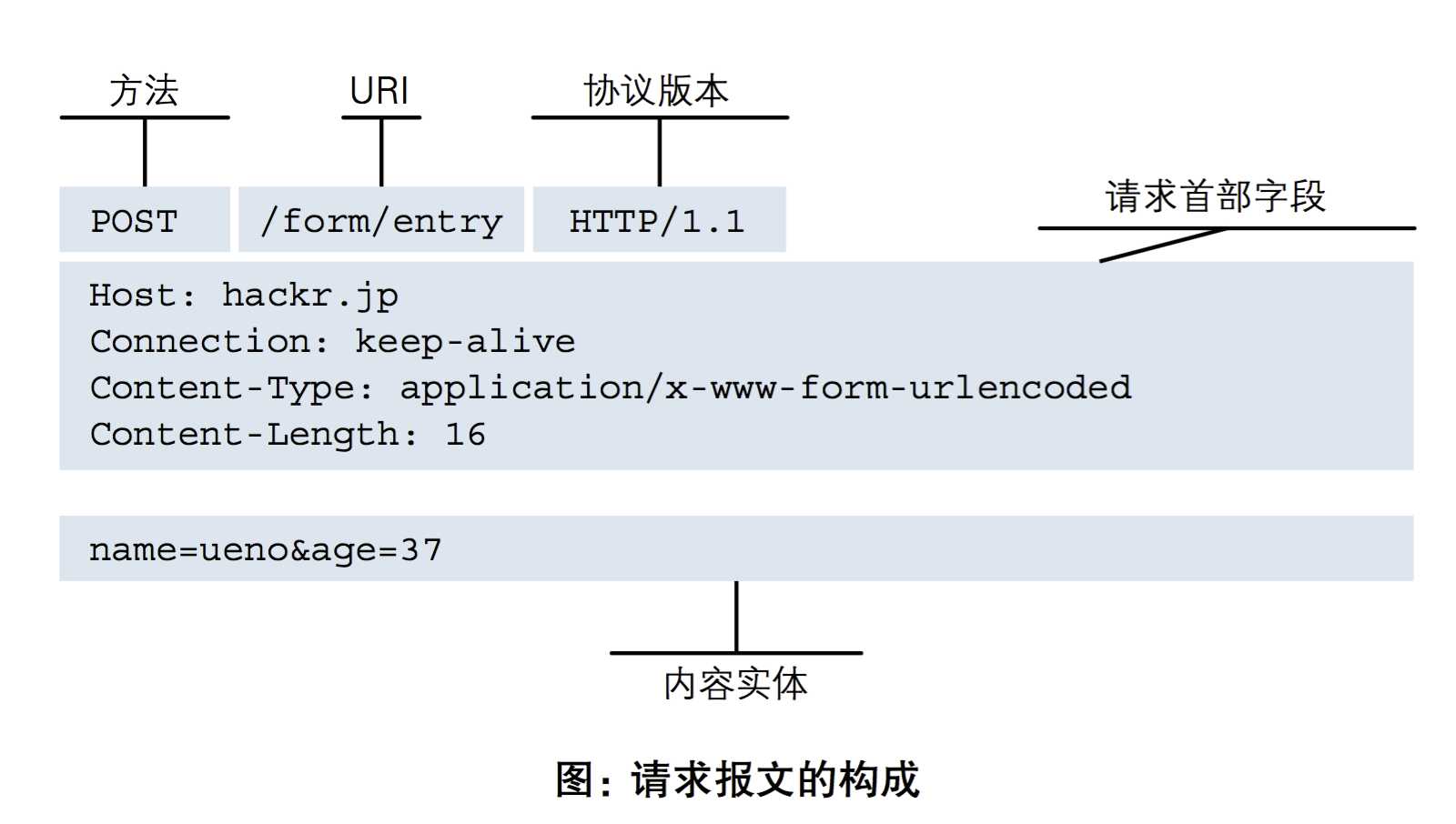
四、HTTP协议

标签:首页 链接 图片 没有 网络 robot ide 就是 模拟浏览器访问
原文地址:https://www.cnblogs.com/st-st/p/10300723.html