标签:elf 9.png settings useragent cloud 随机 data 取数 int
今天分享下scrapy爬虫的基本使用方法,scarpy是一个比较成熟稳定的爬虫框架,方便了爬虫设计,有较强的逻辑性。我们以旅游网站为例进行介绍,一方面是旅游网站多,各个网站的适用情况不同,方便我们的学习。最后有网易云评论的一个爬取思路和不同的实现方法。
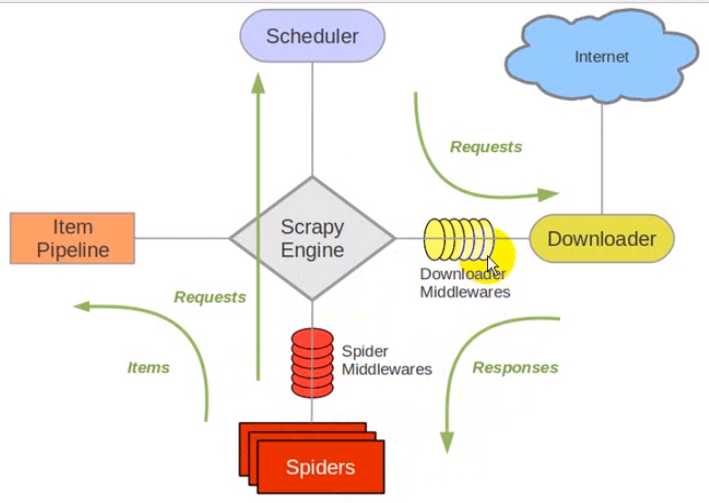
话不多说,下面是scrapy的框架:
创建scrapy爬虫的命令可以在cmd中输入
scrapy project XXXX
之后创建蜘蛛文件使用
scrapy genspider xxx "xxxx.com"
接着初始化工作就做完了,下面正式开始编写工作,流程如下:
编写item.py
编写spider/xxx.py,编写爬虫文件,处理请求和响应,以及提取数据(yield item)
编写pipelines.py,编写管道文件,处理spider返回item数据
编写settings.py,启动管道组件,以及其他相关设置
执行爬虫
以百度旅游的评论数据为例,其评论数据是按页存储的,这种网站数据比较好爬取
items文件中设置我们需要爬取的字段:
markText = scrapy.Field()
在蜘蛛文件中设置爬取域、初始url、步长等参数
allowed_domains = [‘baidu.com‘]
baseURL="https://lvyou.baidu.com/shenzhen/remark/?rn=15&pn="
endword="&style=hot#remark-container"
offset=0
start_urls = [baseURL+str(offset)+endword]
在parse函数中获取到评论的node。这里推荐xpath,语法简单还有对应的工具,方便查找,还可以用正则(万能查找方式),css选择器等等等等:
node_list=response.xpath("//div[@class=‘remark-item clearfix‘]//div[@class=‘ri-remarktxt‘]")
for node in node_list:
item=xxxItem()
item[‘markText‘]=str(node.xpath("string(.)").extract()[0])
yield item
if self.offset<300:#爬取数量
self.offset+=15
url=self.baseURL+str(self.offset)+self.endword
yield scrapy.Request(url,callback=self.parse)
管道文件处理爬取到的数据,这里以json存储,也可以保存到mongodb、sqlite等数据库,量不大,也不需要管理就没必要了:
def __init__(self):
self.f=open("shenzhen.json","w")
def process_item(self, item, spider):
content = json.dumps(dict(item), ensure_ascii=False) + ",\n"
self.f.write(content)
return item
def close_spider(self,spider):
self.f.close()
最后要设置下settings文件,启动管道组件,很多人都会忘掉这种细节。最后可以添加个main.py文件作为爬虫入口:
from scrapy import cmdline
cmdline.execute(‘scrapy crawl baidu‘.split())
下面是爬取结果的一个展示:

进一步的词汇分析,这里用的jieba进行的分词,用wordcloud库进行词云构建,频率统计如下:

如果是去哪儿这种反扒机制比较强的网站,爬取次数过多会封锁ip,我们需要进行比如代理ip的设置、useraget的设置、设置时间间隔、甚至验证码的识别等,具体可看这篇文章:https://www.jianshu.com/p/afd873a42b2d,这里给出一个设置代理ip的方法:
from bs4 import BeautifulSoup
import requests
import random
#随机生成useragent
from fake_useragent import UserAgent
import random
ua = UserAgent()
print(ua.random)
#print(random.random())
headers={
"‘User-Agent‘:"+ua.random
}
def getHTMLText(url, proxies):
try:
r = requests.get(url, proxies=proxies)
r.raise_for_status()
r.encoding = r.apparent_encoding
except BaseException:
return 0
else:
return r.text
#从代理ip网站获取代理ip列表函数,并检测可用性,返回ip列表
def get_ip_list(url):
web_data = requests.get(url, headers)
soup = BeautifulSoup(web_data.text, ‘html‘)
ips = soup.find_all(‘tr‘)
ip_list = []
for i in range(1, len(ips)):
ip_info = ips[i]
tds = ip_info.find_all(‘td‘)
ip_list.append(tds[1].text + ‘:‘ + tds[2].text)
# 检测ip可用性,移除不可用ip:(这里其实总会出问题,你移除的ip可能只是暂时不能用,剩下的ip使用一次后可能之后也未必能用)
for ip in ip_list:
try:
proxy_host = "https://" + ip
proxy_temp = {"https": proxy_host}
res = urllib.urlopen(url, proxies=proxy_temp).read()
except Exception as e:
ip_list.remove(ip)
continue
return ip_list
#从ip池中随机获取ip列表
def get_random_ip(ip_list):
proxy_list = []
for ip in ip_list:
proxy_list.append(‘http://‘ + ip)
proxy_ip = random.choice(proxy_list)
proxies = {‘http‘: proxy_ip}
return proxies
#调用代理
if __name__ == ‘__main__‘:
url = ‘http://www.xicidaili.com/nn/‘
ip_list = get_ip_list(url)
proxies = get_random_ip(ip_list)
print(proxies)
不过爬虫不是一个一招鲜吃遍天的工具,需要我们根据具体的网站灵活的选用合适的方法
关于网易云评论这种没有页码信息的网站,是通过浏览器接收包再由浏览器动态渲染出来的,这个问题知乎有大神回答了:https://www.zhihu.com/question/47765646
好了,今天的介绍就是这些,不是要给现成的代码,而是重点讲一下爬虫的基本思想分享给大家,希望有帮助。
标签:elf 9.png settings useragent cloud 随机 data 取数 int
原文地址:https://www.cnblogs.com/Leo-Do/p/10304585.html
{kind=link}