标签:参数 经验 [1] rest boosting 冗余 避免 网络层 lin
上一篇提到的DQN是基于Q-learning,更新也是基于贪婪算法,$Q \leftarrow Q + \alpha (R + \gamma \max Q‘ - Q)$。虽然可以快速让Q值向可能的优化目标靠拢,但是很容易过度估计(Overestimation)。因为算法每次更新包括了比估计的Q值更大的后一步的max值,这往往倾向于高估Q值。为了解决这个问题, Double DQN[1]通过将,选择Q值对应的动作和评估动作对应的Q值,这两步分隔开来,消除贪婪算法带来的过度估计,得到更精确的Q值估计,从而使学习更加稳定和可靠。
首先来回顾一下DQN的更新方式。DQN基于两个神经网络,在训练神经网络$Q$中,针对参数更新的目标值$y_j$,利用梯度下降来更新参数$\theta$,
\[{({y_j} - Q({\phi _j},{a_j};\theta ))^2}\]
其中参数更新的目标值$y_j$是从目标神经网络$Q‘$的下一步的max中寻找,
\[{y_j} = \left\{ \begin{array}{l}
{r_j}\\
{r_j} + \gamma {\max _{a‘}}Q‘({\phi _{j + 1}},a‘;\theta ‘)
\end{array} \right.\]
在DQN的基础上,Double DQN不直接从目标神经网络$Q‘$中找到参数更新的目标值$y_j$,而是现在训练神经网络$Q$中找到最大Q值对应的动作,再利用这个选择出来的动作a在目标神经网络$Q‘$中计算参数更新的目标值$y_j$,
\[\begin{array}{l}
a{‘_{\max }} = \mathop {\arg \max }\limits_a Q({\phi _{j + 1}},a;\theta )\\
{y_j} = {r_j} + \gamma {\max _{a‘}}Q‘({\phi _{j + 1}},a{‘_{\max }};\theta ‘)
\end{array}\]
Double DQN改进了DQN的参数更新部分,针对DQN的随机经验回放,Prioritized DQN[3]利用带优先级的经验回放,赋予了不同样本不一样的重要性,加快了收敛速度,使学习更加有效。比如说,对于一些最相关的转移隐藏在大量冗余的失败转移中的学习任务,我们应该采用带优先级的经验回放策略,而不是均匀随机采样,提高了收敛速度,避免了一些没有价值的冗余迭代,从而提高了学习的效率。
怎样评估经验,给予不同的权重呢?DQN系列的更新过程和Q-learning一样,利用TD-error $R + \gamma \max Q‘- Q$来更新Q。TD-error越大,证明这次更新越“惊喜”越出乎意料,这类似与集成的Boosting思想,对错误的样本关注度更大,从而尽可能纠正这些错误。
但是如果是完全贪婪的TD-error优先级会带来一些问题。首先为了避免对整个记忆全部回放更新,只对重放的记忆更新TD-error,这导致了如果第一次得到了一个低的TD-error,就可能长时间都无法被回放。其次这样的机制对噪声很敏感,并且随着bootstrapping会恶化,导致拟合误差。最后贪婪优先级只关注了经验的小部分,高错误的样本会频繁回放,这就使系统缺乏多样性从而过拟合。
为了避免这些问题,我们引入了随机采样方法来折中完全贪婪的优先采样和均匀随机采样。我们确保在采样过程中,优先级越高,被采样的概率也越高,同时保证对于最低优先级的记忆也存在一定的非零概率被采样。具体而言,我们定义概率如下,
\[P(i) = \frac{{p_i^\alpha }}{{\sum\nolimits_k {p_k^\alpha } }}\]
我们在分析算法时,偶然发现了另一种现象,回想起来很明显。有些存储的记忆在他们因为记忆的滑动窗口被丢掉时都从来没有被回放过,大部分的记忆在距离第一次存储很久之后才会被回放,而且均匀随机抽样倾向于过时抽样。带优先级的回放解决了第一个有些记忆不会被回放的问题,因为直接给了一定的概率。对于第二个过时采样的问题,Prioritized DQN则更倾向于新的记忆,因为旧的记忆已经被纠正很多次了,新的记忆往往有更大的TD-error。
Double DQN改进了DQN的参数更新部分,Prioritized DQN改进了DQN的经验回放部分,Dueling DQN则是通过优化神经网络的结构来优化算法。在许多基于视觉的感知的DRL任务中,不同的状态动作对的值函数是不同的,但是在某些状态下,值函数的大小与动作无关。因此Dueling DQN把Q值更新分开成两个部分,一个是状态v函数,一个是独立于状态的动作优势函数。比如对于避撞游戏,道路上如果暂时没有出现障碍,向左或向右的动作估计意义不大。所以对于很多状态来说,没有必要估计每个动作的Q值。但是对于基于自举的算法来说,对于状态的值估计是很有必要的。为此我们设计了一个新的网络结构,称之为Dueling network。不同于全连接层,该网络有两条估计路径(stream),分别对状态值估计和动作优势函数估计。最后两者合起来成为Q-network的输出。
\[Q(s,a;\theta ,\alpha ,\beta ) = V(s;\theta ,\beta ) + A(s,a;\theta ,\alpha )\]
其中$\theta$是蓝色部分公共卷积层的参数,$\alpha$和$\beta$分别是红色两个stream独有网络层的参数,最后通过绿色部分加起来。
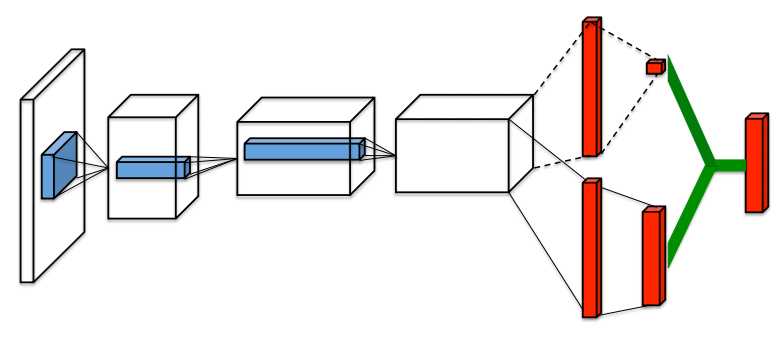
我们最终的目标是对$Q(s,a;\theta ,\alpha ,\beta ) $估计准确,不只是对$V(s;\theta ,\beta )$或者$A(s,a;\theta ,\alpha )$。直接利用相加的Q值是不可辨识的,也就是我们是无法分离V和A来选择动作的,这就很不实用了。因此,对同一个状态,我们固定状态值估计$V(s;\theta ,\beta )$,更新动作优势函数,
\[Q(s,a;\theta ,\alpha ,\beta ) = V(s;\theta ,\beta ) + \left( {A(s,a;\theta ,\alpha ) - \mathop {\max }\limits_{a‘ \in \left| A \right|} A(s,a‘;\theta ,\alpha )} \right)\]
而在实际中,一般要将动作优势流设置为单独动作优势函数减去某状态下所有动作优势函数的平均值,这样做可以保证该状态下各动作的优势函数相对排序不变,而且可以缩小 Q 值的范围,去除多余的自由度,提高算法稳定性,
\[Q(s,a;\theta ,\alpha ,\beta ) = V(s;\theta ,\beta ) + \left( {A(s,a;\theta ,\alpha ) - \frac{1}{{\left| A \right|}}\sum\limits_{a‘} {A(s,a‘;\theta ,\alpha )} } \right)\]
参考:
6. Double DQN、Prioritized DQN、Dueling DQN
标签:参数 经验 [1] rest boosting 冗余 避免 网络层 lin
原文地址:https://www.cnblogs.com/yijuncheng/p/10289615.html