标签:com 化学 一个 jpg 技术分享 小例子 info 解决方法 image
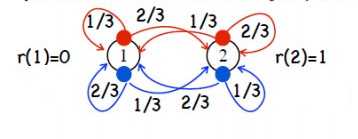
强化学习中动态规划是解决已知状态转移概率和奖励值情况下的解决方法,这种情况下我们一般可以采取动态规划中的 策略迭代和值迭代的方式来进行求解,下面给出一个具体的小例子。
动态规划中 策略迭代 和 值迭代 的一个小例子
原文地址:https://www.cnblogs.com/devilmaycry812839668/p/10314049.html