标签:分享图片 图片 img targe 遍历 name .text lte www.
上来先贴地址,刚入门的可以来van啊:
0x00 第一关
打开网址,看到如下页面:
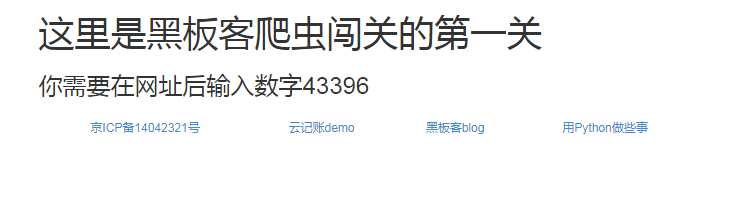
先抱着试试看的心态在网址后面加上数字看看效果:
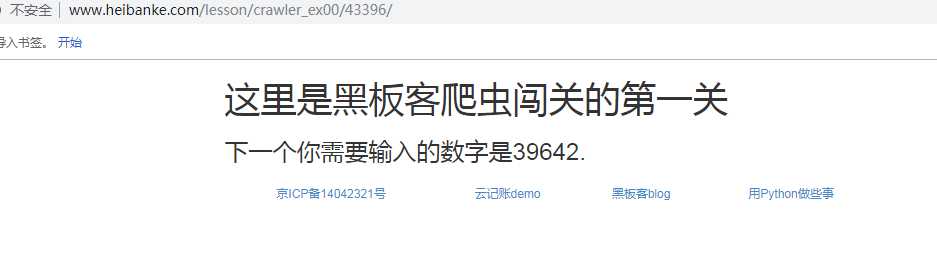
怕不是个循环,获取网页中的数字不断加到url中,验证猜想,继续试一试:
?????
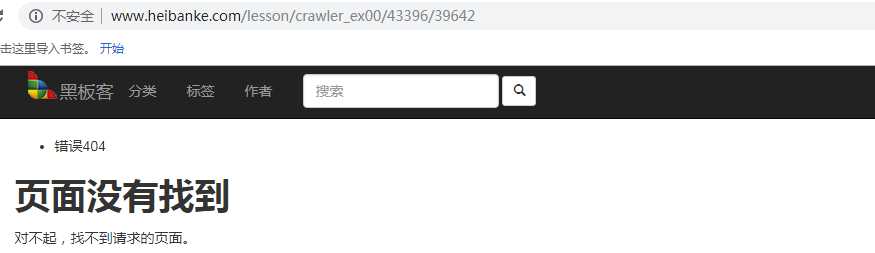
那就把原来的数字换掉:
妙啊:
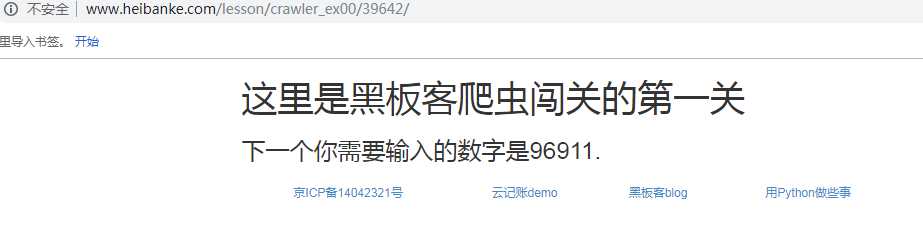
这里基本确定思路,获取网页内的数字,然后在将数字加入url进行循环提交
查看源码,确定获取的信息<h3>标签内,并使用re库匹配我们要的数字
import requests from bs4 import BeautifulSoup import re def getHTMLText(url): try: r = requests.get(url, timeout = 30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return ‘‘ def getNum(html): soup = BeautifulSoup(html, ‘html.parser‘) h3 = soup.find(‘h3‘).text num = re.findall(r‘\d{5}‘,h3)[0] return num def main(): start_url = ‘http://www.heibanke.com/lesson/crawler_ex00/‘ num = 39642 while num: url = start_url + str(num) html = getHTMLText(url) print(html) num = getNum(html) main()
跑起来:

0x01 第二关
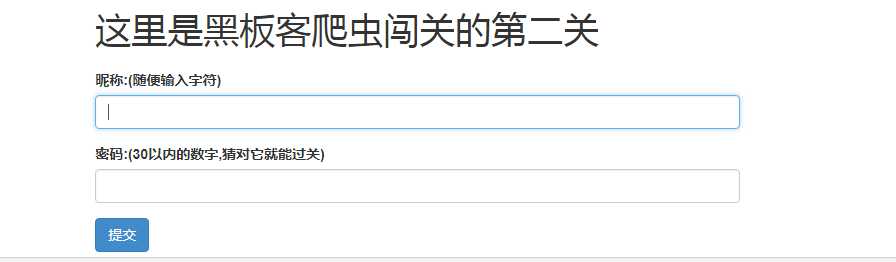
初步断定post两个参数,用for循环遍历30前的数字爆破密码
先抓个包,看看两个参数名叫啥

import requests from bs4 import BeautifulSoup def getHTMLText(url, kv): try: r = requests.post(url, data= kv) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return ‘‘ def getcontent(html): soup = BeautifulSoup(html, ‘html.parser‘) h3 = soup.find(‘h3‘).text if not u‘密码错误‘ in h3: print(html) def main(): url = ‘http://www.heibanke.com/lesson/crawler_ex01/‘ for i in range(31): print(i) kv = {‘username‘: ‘1‘, ‘password‘: i} html = getHTMLText(url, kv) getcontent(html) main()
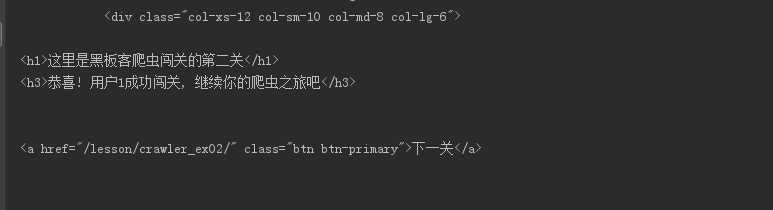
吼吼吼,成功辽
标签:分享图片 图片 img targe 遍历 name .text lte www.
原文地址:https://www.cnblogs.com/Ragd0ll/p/10316687.html