使用方法:nth_element(start, start+n, end)
使第n大元素处于第n位置(从0开始,其位置是下标为n的元素),并且比这个元素小的元素都排在这个元素之前,比这个元素大的元素都排在这个元素之后,但不能保证他们是有序的。
#include <algorithm> #include <iostream> #include <cstring> #include <cstdio> using namespace std; const int N=101; char s[N]; int main() { int len,n; gets(s); len=strlen(s); scanf("%d",&n); nth_element(s,s+n,s+len); puts(s); return 0; }
nth_element函数原型有四个,详细我就不一一累赘了,我们就用最普通的用法寻找第k位置的元素。
函数用法为:nth_element(first,kth,end)。
first,last 第一个和最后一个迭代器,也可以直接用数组的位置。
kth,要定位的第k个元素,能对它进行随机访问.
将第k_th元素放到它该放的位置上,左边元素都小于等于它,右边元素都大于等于它.
例如:
vector<int> a(9);
for(int i = 0; i < 9; i++)
a[i] = i+1;
random_shuffle(a.begin(),a.end());
for(int i = 0; i < 9; i++)
cout << a[i] << " ";
cout << endl;
nth_element(a.begin(),a.begin()+4,a.end());
cout << *(a.begin()+4) << endl;
for(int i = 0; i < 9; i++)
cout << a[i] << " ";
cout << endl;
结果为:
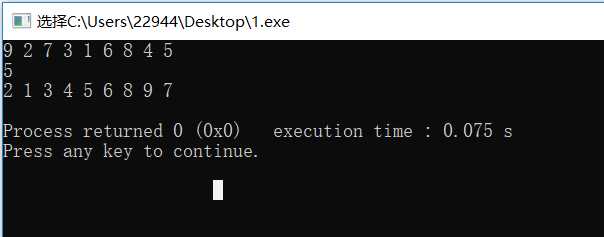
可以发现函数只是把kth的元素放在了正确位置,对其他元素并没有排序,所以可以利用这个函数快速定位第k个元素,当然,这个函数也支持你直接写比较函数,此处不再累赘因为ACM中基本不会用到。
那么为什么要选择这个函数呢,这就和复杂度有关了,nth_element的空间复杂度为O(1),在数据量大的时候时间复杂度为O(n),数据少的情况最坏为O(n^2),因为函数原理是随机访问,但实际运用过程中,基本都会是O(n)的时间复杂度。所以说是非常迅速的。
https://ac.nowcoder.com/acm/contest/327/A


#include <bits/stdc++.h> using namespace std; #define ll long long int t,n,k; struct point { ll x,y; } a[105]; int main() { scanf("%d",&t); while (t--) { scanf("%d%d",&n,&k); for (int i=1; i<=n; i++) { scanf("%lld%lld",&a[i].x,&a[i].y); } vector<ll> v; for (int i=1; i<=n; i++) { for (int j=i+1; j<=n; j++) { for (int w=j+1; w<=n; w++) { ll area=abs((a[j].x-a[i].x)*(a[w].y-a[i].y)-(a[w].x-a[i].x)*(a[j].y-a[i].y)); v.push_back(area); } } } nth_element(v.begin(),v.begin()+n*(n-1)*(n-2)/6-k,v.end()); ll ans=v[n*(n-1)*(n-2)/6-k]; if (ans%2==0) printf("%lld.00\n",ans/2); else printf("%lld.50\n",ans/2); } return 0; }