标签:firewalld secondary 0x03 oop sbin script shuff centos author
目录
准备jdk和Hadoop的安装包。建议删掉自带的Java,要不然后面配置环境变量会有坑
rpm -qa | grep java #查看相关Java的包然后删除涉及jdk的几个包
rpm -e --nodeps [+jdk名]之后将jdk和Hadoop上传到机子中就可以正式开始搭建了
同样是使用rpm查看是否安装ssh
rpm -qa | grep ssh如果出现openssh-server等,那么说明系统已经安装好ssh,如果没有,则需要自行安装
yum install openssh-clients
yum install openssh-server然后开始进行ssh 免密登陆,先执行一下ssh localhost 登陆一下,看看ssh是否正常使用,然后exit就会退出ssh,
cd ~/.ssh
ssh-keygen -t rsa
cat id_rsa.pub >> authorized_keys
chmod 600 ./authorized_keys之后我们再登陆ssh 就不需要密码了
vi /etc/hosts
#然后在文件末尾添加
#[你的ip] 用户名 大致如下图
[
我们将之前第一步准备的jdk安装包解压,我们用的是jdk1.7.0_91
这里我的安装目录是 /usr/local
tar -zxvf jdk-7u91-linux-x64.tar.gz -C /usr/local
# 然后是配置环境变量
vi ~/.bashrc
# 打开这个文件后,在末尾添加上
export JAVA_HOME=/usr/local/jdk1.7.0_91 # 这里填的就是你的jdk安装路径
export PATH=$JAVA_HOME/bin:$PATH
# 然后使用source 使环境变量生效,记住,每次修改环境变量都要使用一下
source ~/.bashrc将之前准备的Hadoop安装包解压,
tar -zxvf hadoop-2.6.0.tar.gz -C /usr/local解压好之后,(最好把解压之后的文件夹直接命名为hadoop,这样配置环境变量方便) 我们到Hadoop文件夹下
cd /usr/local/hadoop 然后我们查看Hadoop的版本,确保安装成功
./bin/hadoop version
vim ~/.bashrc
# 与配置jdk相同的道理:
export HADOOP_HOME=/usr/local/hadoop #hadoop 的目录
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
#同样source一下
source ~/.bashrc此文件与接下来几个配置文件都是在 /usr/local/hadoop/etc/hadoop 文件夹下,我们使用vi打开然后修改。首先是core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/data</value>
<description>hadoop_temp</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop01:8020</value> #这里注意一下,之前修改的映射时的用户名,我这里叫做hadoop01
<description>hdfs_derect</description>
</property>
</configuration><configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration><configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
这个配置文件刚开始文件名是叫做mapred-site.xml.template,我们可以在配置好之后把名字改一下
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>这个文件要配置好,一开始我就是这里出了错
hdfs namenode -format
如果执行成功的话,会出现如下图所示
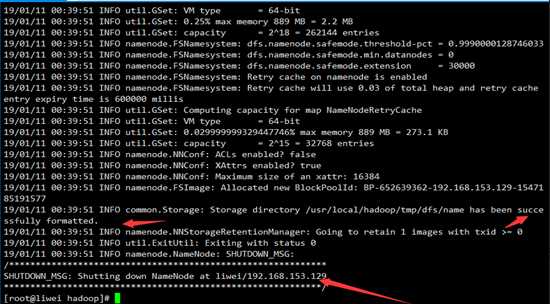
这里我用的是Centos7,关闭防火墙的命令是firewalld
启动: systemctl start firewalld
关闭: systemctl stop firewalld
开机禁用 systemctl disable firewalld
开机启用 systemctl enable firewalld我们来到 /usr/local/hadoop/sbin 文件夹下,使用 ls 我们可以看到许多启动文件
[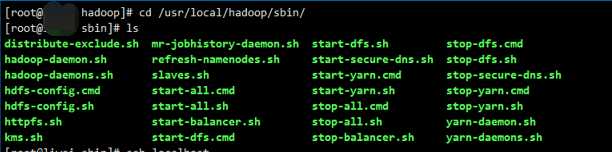
其中 start-all.sh 是启动全部的
我们在此目录下执行 ./start-all.sh
如果出现如下图则成功启动
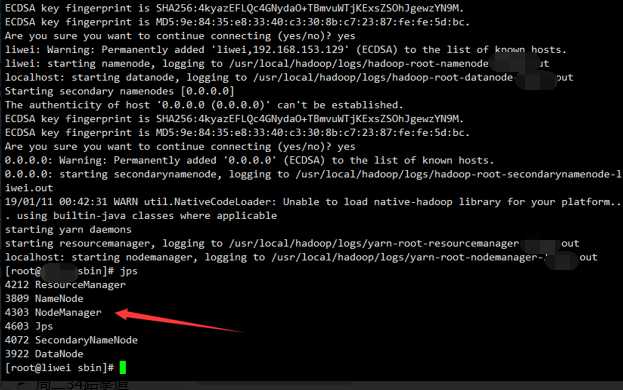
然后输入jps
看到以下5个进程,就算大功告成了
namenode
secondarynamenode
datanode
resourcemanager
nodemanager标签:firewalld secondary 0x03 oop sbin script shuff centos author
原文地址:https://www.cnblogs.com/c4ri5j/p/10321484.html