标签:生产者和消费者 离线 produce 企业 数据丢失 cal 最大 访问 time
1. Kafka简介
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等,用scala语言编写,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
Kafka具有以下特性:
- 高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition, consumer group 对partition进行consume操作。
- 可扩展性:kafka集群支持热扩展
- 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
- 容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
- 高并发:支持数千个客户端同时读写
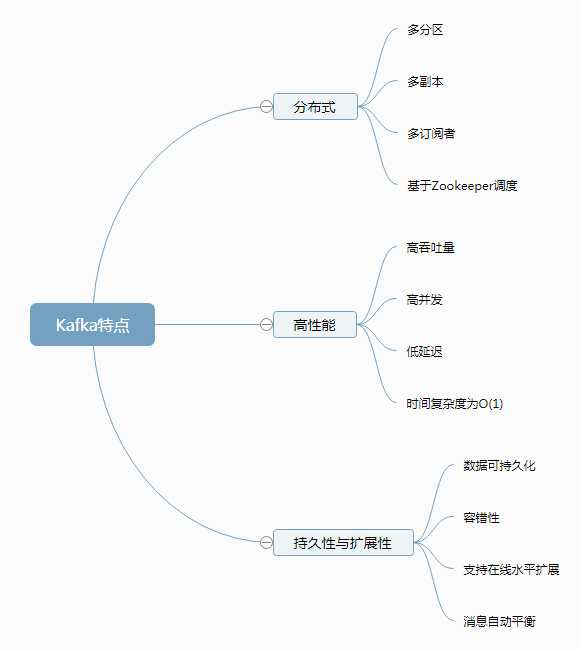
Kafka的使用场景:
- 日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等。
- 消息系统:解耦和生产者和消费者、缓存消息等。
- 用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
- 运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
- 流式处理:比如spark streaming和storm
- 事件源
通过上面的介绍也可以看出:Kafka给自身的定位并不仅仅是一个消息系统,而是通过发布订阅消息机制实现的分布式流平台。
流平台有三个关键的能力:
- 发布订阅记录流,和消息队列或者企业新消息系统类似。
- 以可容错、持久的方式保存记录流
- 当记录流产生时就进行处理
Kafka通常用于应用中的两种广播类型:
- 在系统和应用间建立实时的数据管道,能够可信赖的获取数据。
- 建立实时的流应用,可以处理或者响应数据流。
2. Kafka基本概念及延伸
2.1 基本概念
Producer:数据生产者
- 消息和数据的生产者
- 向Kafka的一个topic发布消息的进程或代码或服务
Consumer:数据消费者
- 消息和数据的消费者
- 向Kafka订阅数据(topic)并且处理其发布的消息的进程或代码或服务
Consumer Group:消费者组
- 对于同一个topic,会广播给不同的Group
- 一个Group中,只有一个Consumer可以消费该消息
Broker:服务节点
Topic:主题
Partition:分区
- Kafka中数据存储的基本单元
- 一个topic数据,会被分散存储到多个Partition
- 一个Partition只会存在一个Broker上
- 每个Partition是有序的
Replication:分区的副本
- 同一个Partition可能会有多个Replication
- 多个Replication之间数据是一样的
Replication Leader:副本的老大
- 一个Partition的多个Replication上
- 需要一个Leader负责该Partition上与Producer和Consumer交互
Replication Manager:副本的管理者
- 负责管理当前Broker所有分区和副本的信息
- 处理KafkaController发起的一些请求
- 副本状态的切换
- 添加、读取消息等
2.2 概念延伸
Partition:分区
- 每一个Topic被切分为多个Partition
- 消费者数目少于或等于Partition的数目
- Broker Group中的每一个Broker保存Topic的一个或多个Partition
- Consumer Group中的仅有一个Consumer读取Topic的一个或多个Partition,并且是惟一的Consumer
Replication:分区的副本
- 当集群中有Broker挂掉的情况,系统可以主动地使Replication提供服务
- 系统默认设置每一个Topic的Replication系数为1,可以在创建Topic时单独设置
- Replication的基本单位是Topic的Partition
- 所有的读和写都从Replication Leader进行,Replication Followers只是作为备份
- Replication Followers必须能够及时复制Replication Leader的数据
- 增加容错性与可扩展性
3. 基本结构
Kafka功能结构
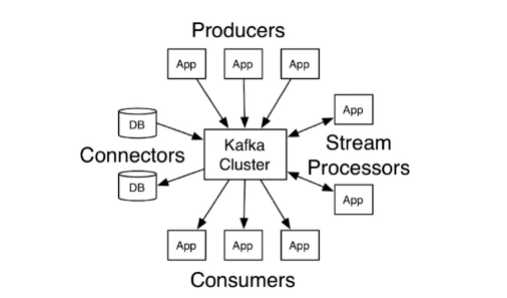
Kafka数据流势
Kafka消息结构

- Offset:当前消息所处于的偏移
- Length:消息的长度
- CRC32:校验字段,用于校验当前信息的完整性
- Magic:很多分布式系统都会设计该字段,固定的数字,用于快速判定当前信息是否为Kafka消息
- attributes:可选字段,消息的属性
- Timestamp:时间戳
- Key Length:Key的长度
- Key:Key
- Value Length:Value的长度
- Value:Value
4. Kafka安装部署
Kafka依赖于zookeeper实现分布式系统的协调,所以需要同时安装zookeeper。两个的安装包到官网下载。

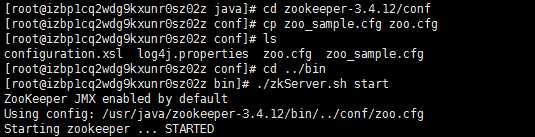
4.1 zookeeper安装配置
在zookeeper解压后的目录下找到conf文件夹,进入后,复制文件zoo_sample.cfg,并命名为zoo.cfg。zoo.cfg中一共五个配置项,可以使用默认配置。
4.2 Kafka安装配置
进入kafka根目录下的config文件夹下,打开server.properties,修改如下配置项(一般默认即为如下,无需修改)
zookeeper.connect=localhost:2181
broker.id=0
log.dirs=/tmp/kafka-logs
另外,config文件夹下也包含有zookeeper的配置文件,可以在其中设置配置项,启动zookeeper时引用这个配置文件,实现定制化。

Kafka的bin目录包含了大多数功能的启动脚本,可以通过它们控制Kafka的功能开启。
启动Kafka

4.3 使用控制台操作生产者和消费者
创建Topic:sudo ./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 3 --topic myimooc-kafka-topic
查看Topic:sudo ./bin/kafka-topics.sh --list --zookeeper localhost:2181
启动生产者:sudo ./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic myimooc-kafka-topic
启动消费者:sudo ./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic myimooc-kafka-topic --from-beginning
生产消息:first message
生产消息:second message
https://blog.csdn.net/liyiming2017/article/details/82790574
https://blog.csdn.net/YChenFeng/article/details/74980531
Kafka流处理平台
标签:生产者和消费者 离线 produce 企业 数据丢失 cal 最大 访问 time
原文地址:https://www.cnblogs.com/zjfjava/p/10325526.html