标签:tokenize lower 调用函数 panda 建模 一个 bubuko 代码 softmax
函数说明:
1. from gensim.model import word2vec 构建模型 word2vec(corpus_token, size=feature_size, min_count=min_count, window=window, sample=sample)
参数说明:corpus_token已经进行切分的列表数据,数据格式是list of list , size表示的是特征向量的维度,即映射的维度, min_count表示最小的计数词,如果小于这个数的词,将不进行统计, window表示滑动窗口,表示滑动窗口的大小,用于构造训练集和测试集, sample表示对出现次数频繁的词进行一个随机下采样
2. model.wv[‘sky‘] 表示输出sky这个词的特征映射结果
3.model.wv.index2words 输出经过映射后的特征名,输出经过映射词的名字
这里简要的说明一下个人的理解
CBOW是word2vec的一种基础模型,他是通过选取一个词前后c个词进行训练
训练数据:一个词的前后2c个词做为训练
标签:当前这个词作为标签值
最后的输出结果是前一个隐含层的输出,即特征的个数,这个的特征是4即存在4个维度值
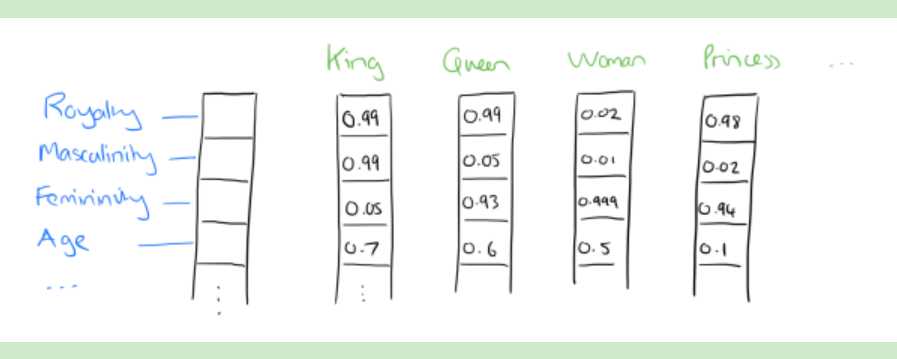
如果对4个特征做降维,降成2维,我们可以发现词义相似的词会被放在相近的位置上
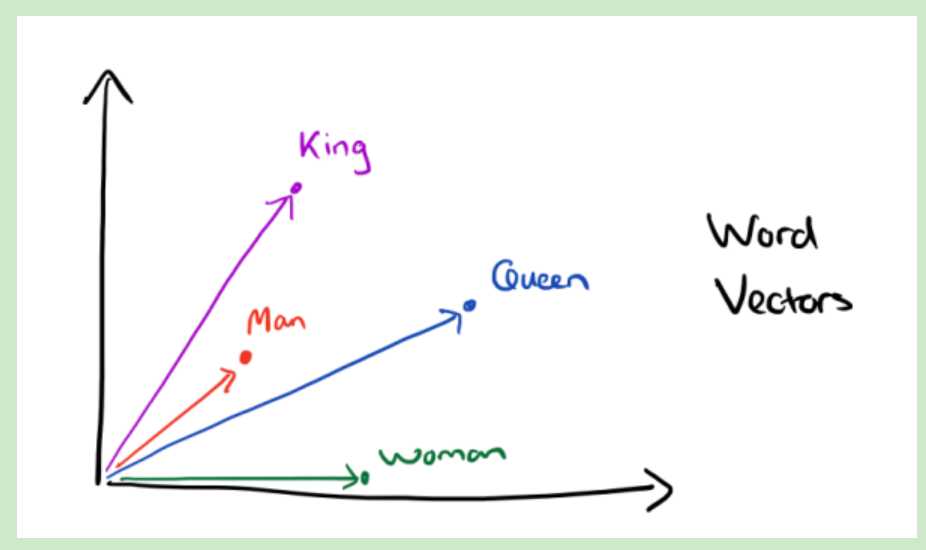
word2vec使用每一个特征向量词的平均用最为最终的特征表示
word2vec主要是构建了霍夫曼树用来取代softmax最后一个神经元的参数跟新
操作过程:
第一步:
首先使用最大似然估计 ∑p = yi*pi + (1-yi) * pi
然后对其根绝∑p/dtheta 进行求导操作, 获得梯度的方向。
第二步:
建立一颗霍夫曼树:每个叶子节点的个数是Xw = 1/2c∑xi 表示这个词左右两边c个词进行加和,xi表示初始值的one-hot编码
通过梯度上升法:来更新thetaj 和 Xw
thetaj = thetaj + a * g * Xw # a表示步长, g表示每个参数的梯度方向, Xw表示当前的值
Xw = 0 + g * thetaj # g表示每个参数的梯度方向, thetaj表示当前的梯度值
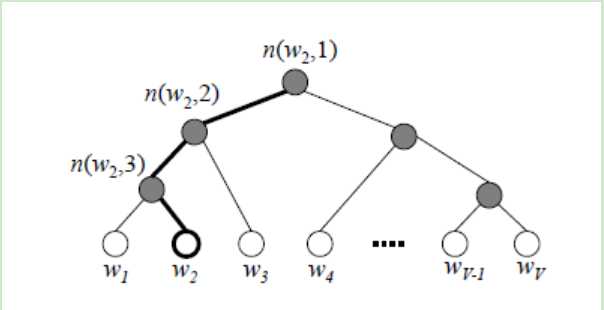
由于左子树的权重值大于右子树,左边的是sigmoid大于0.5的,右边是sigmoid小于0.5的
因此我们很容易找出sigmoid值最大的那个树(感觉有点点不是很理解,这么做的目的)
代码:
第一步:DataFrame化数据
第二步:进行分词和去除停用词,使用‘ ‘.join连接列表
第三步:np.vectorize 向量化函数和调用函数进行停用词的去除
第四步:构建gensim.models import word2vec 构造单个词的特征向量,使用model.wv[‘sky‘]
第五步:对第三步的字符串进行切分,将切分后的数据送入到word2vec建立模型,使用model.wv.index2word打印出当前的特征名,使用循环找出每个列表中词的特征向量,最后对每个列表中的词做一个特征向量的平均,作为列表的特征向量
import numpy as np import pandas as pd import matplotlib.pyplot as plt import re corpus = [‘The sky is blue and beautiful.‘, ‘Love this blue and beautiful sky!‘, ‘The quick brown fox jumps over the lazy dog.‘, ‘The brown fox is quick and the blue dog is lazy!‘, ‘The sky is very blue and the sky is very beautiful today‘, ‘The dog is lazy but the brown fox is quick!‘ ] labels = [‘weather‘, ‘weather‘, ‘animals‘, ‘animals‘, ‘weather‘, ‘animals‘] # 第一步:进行DataFrame化操作 corpus = np.array(corpus) corpus_df = pd.DataFrame({‘Document‘: corpus, ‘category‘: labels}) # 第二步:进行分词和停用词的去除 import nltk stopwords = nltk.corpus.stopwords.words(‘english‘) wps = nltk.WordPunctTokenizer() def Normalize_corpus(doc): tokens = re.findall(r‘[a-zA-Z0-9]+‘, doc.lower()) doc = [token for token in tokens if token not in stopwords] doc = ‘ ‘.join(doc) return doc # 第三步:向量化函数,调用函数进行分词和停用词的去除 Normalize_corpus = np.vectorize(Normalize_corpus) corpus_array = Normalize_corpus(corpus) # 第四步:对单个词计算word2vec特征向量 from gensim.models import word2vec corpus_token = [wps.tokenize(corpus) for corpus in corpus_array] print(corpus_token) # 特征的维度 feature_size = 10 # 最小的统计个数,小于这个数就不进行统计 min_count = 1 # 滑动窗口 window = 10 # 对出现次数频繁的词进行随机下采样操作 sample = 1e-3 model = word2vec.Word2Vec(corpus_token, size=feature_size, min_count=min_count, window=window, sample=sample) print(model.wv.index2word) # 第五步:对每一个corpus做平均的word2vec特征向量 def word2vec_corpus(corpuses, num_size=10): corpus_tokens = [wps.tokenize(corpus) for corpus in corpuses] model = word2vec.Word2Vec(corpus_tokens, size=num_size, min_count=min_count, window=window, sample=sample) vocabulary = model.wv.index2word score_list = [] for corpus_token in corpus_tokens: count_time = 0 score_array = np.zeros([10]) for word in corpus_token: if word in vocabulary: count_time += 1 score_array += model.wv[word] score_array = score_array / count_time score_list.append(list(score_array)) return score_list print(np.shape(word2vec_corpus(corpus_array, num_size=10)))

部分的特征数据:我们可以看出维度为(6, 10)上述的特征是6个,每个特征的维度为10
标签:tokenize lower 调用函数 panda 建模 一个 bubuko 代码 softmax
原文地址:https://www.cnblogs.com/my-love-is-python/p/10326045.html