标签:slots 连接错误 左右 流程 python 必须 ++ 多实例 验证
在Redis中,与Sentinel(哨兵)实现的高可用相比,集群(cluster)更多的是强调数据的分片或者是节点的伸缩性,如果在集群的主节点上加入对应的从节点,集群还可以自动故障转移,因此相比Sentinel(哨兵)还是有不少优势的。
以下简单测试Redis的集群(单机多实例的模式),来体验一下集群的自动故障转移功能,同时结合Python,来观察自动故障转移过程中应用程序端的表现。
redis集群实例安装
启动6个redis集群实例,集群模式,除了正常的配置项目之外,需要在每个主节点中增加集群配置
cluster-enabled yes # 开启集群模 cluster-node-timeout 1000 # 节点超时时间,单位毫秒,设置一个较小的超时时间,目的是为了后面测试自动故障转移的效果

分配slot & 主节点握手
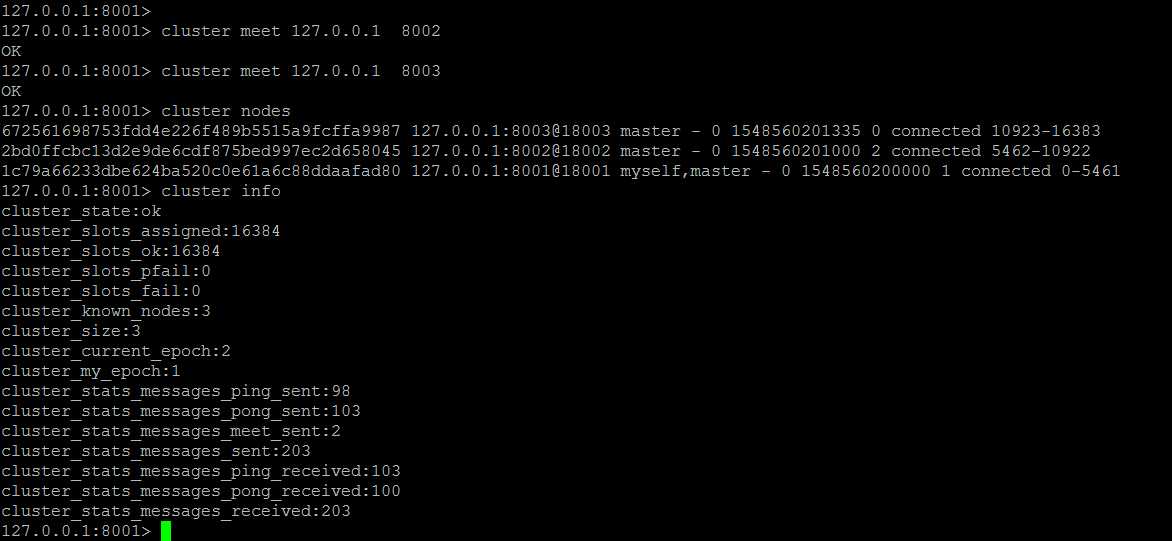
主节点分配slot给主节点,三个主节点分配16383个slot
8001主----->8004从
8002主----->8005从
8003主----->8006从
#!/bin/bash
for ((i=0;i<=16383;i++))
do
if [ $i -le 5461 ]; then
/usr/local/redis5_1/bin/redis-cli -h 127.0.0.1 -p 8001 -a root CLUSTER ADDSLOTS $i
elif [ $i -gt 5461 ]&&[ $i -le 10922 ]; then
/usr/local/redis5_1/bin/redis-cli -h 127.0.0.1 -p 8002 -a root CLUSTER ADDSLOTS $i
elif [ $i -gt 10922 ]; then
/usr/local/redis5_1/bin/redis-cli -h 127.0.0.1 -p 8003 -a root CLUSTER ADDSLOTS $i
fi
done
分配完slot之后,在第一个主节点上执行cluster meet 127.0.0.1 8002,cluster meet 127.0.0.1 8003
无须在其他两个主节点上meet另外两个主节点,随后三个主节点之间关系确定会自动确定,目前集群中是三个主节点
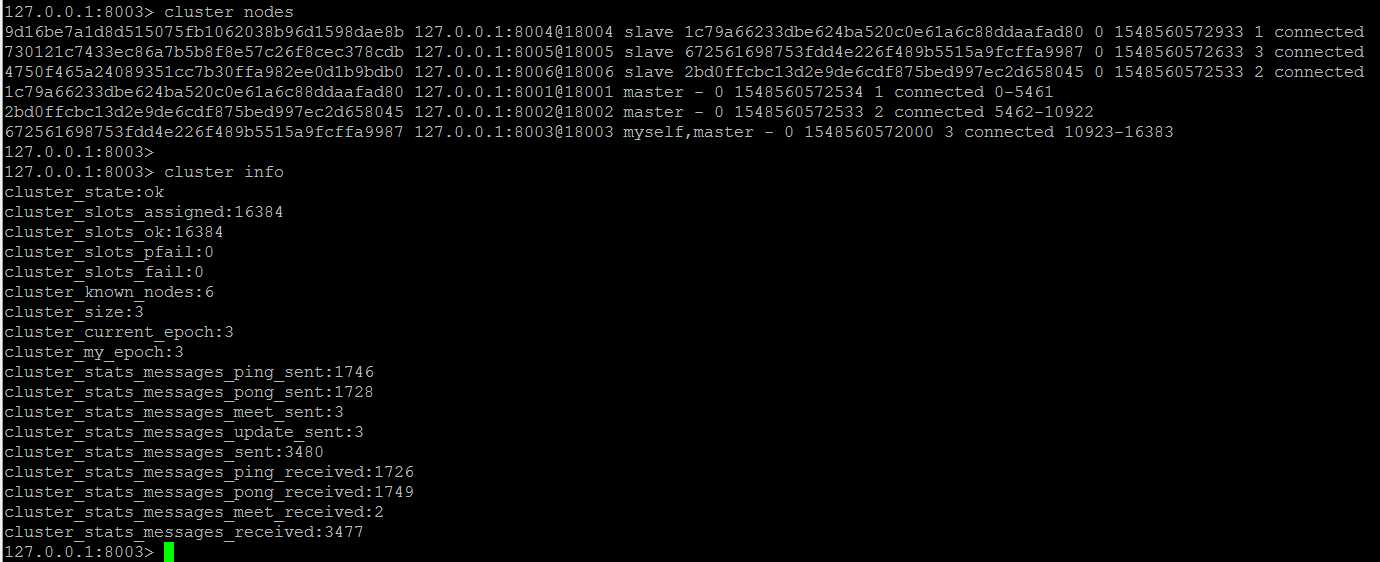
添加主节点对应的从节点,需要登录到每个主节点的实例上,执行
![]()
![]()
![]()
三个从节点分别加入到主节点之后,此时6个节点全部加入到集群中
Python连接至集群测试
这里需要安装redis-py-cluster依赖包
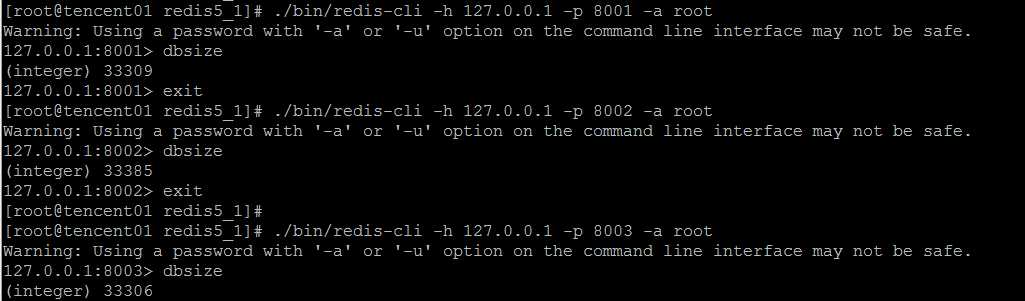
#!/usr/bin/env python3 import time from time import ctime,sleep from rediscluster import StrictRedisCluster startup_nodes = [ {"host":"111.231.253.***", "port":8001}, {"host":"111.231.253.***", "port":8002}, {"host":"111.231.253.***", "port":8003}, {"host":"111.231.253.***", "port":8004}, {"host":"111.231.253.***", "port":8005}, {"host":"111.231.253.***", "port":8006} ] redis_conn= StrictRedisCluster(startup_nodes=startup_nodes, decode_responses=True,password="root") for i in range(0, 100000): try: redis_conn.set(‘name‘ + str(i), str(i)) print(‘setting name‘ + str(i) +"--->" + time.strftime(‘%Y-%m-%d %H:%M:%S‘,time.localtime(time.time()))) except: print("connect to redis cluster error") time.sleep(2)
执行上述写入测试脚本之后,数据基本上均匀地落在三个节点上
自动故障转移测试
修改Python脚本,每隔1s写入一条数据,目的是便于观察在主节点宕机,集群自动故障转移这个时间段之之内(1s钟左右),对于应用程序的影响,或者说应用程序在自动故障转移前后的表现。
如下脚本循环往Redis集群中写入数据,执行期间,强制杀掉一个主节点,观察应用程序连接情况。
同时,如果发生异常,暂停应用程序2s,因为上面一开始配置的集群故障转移时间是1s,如果应用程序暂停2s,完全可以跳过故障转移的过程,
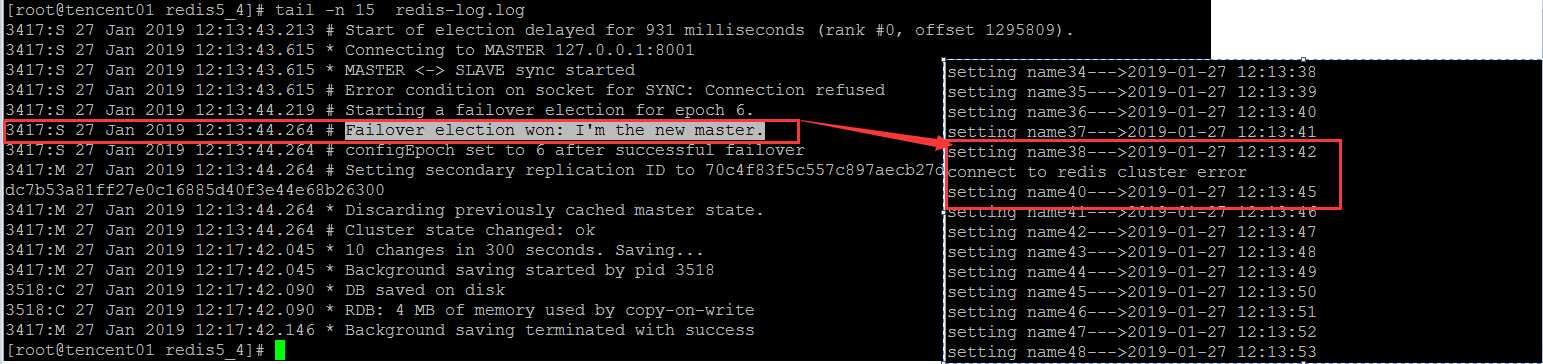
当故障转移完成之后,应用程序又恢复成正常状态,虽然8001节点宕机,应用程序继续连接8001节点,但是应用程序完全无感知。
import time from time import ctime,sleep from rediscluster import StrictRedisCluster startup_nodes = [ {"host":"111.231.253.***", "port":8001}, {"host":"111.231.253.***", "port":8002}, {"host":"111.231.253.***", "port":8003}, {"host":"111.231.253.***", "port":8004}, {"host":"111.231.253.***", "port":8005}, {"host":"111.231.253.***", "port":8006} ] redis_conn= StrictRedisCluster(startup_nodes=startup_nodes, decode_responses=True,password="root") for i in range(0, 100000): try: redis_conn.set(‘name‘ + str(i), str(i)) print(‘setting name‘ + str(i) +"--->" + time.strftime(‘%Y-%m-%d %H:%M:%S‘,time.localtime(time.time()))) time.sleep(1) except: print("connect to redis cluster error") time.sleep(2)
发现在杀掉主节点之后,仅发生了一次连接错误,随后因为Redis集群的自动故障转移成功,对应于程序来说是透明的,因此应用程序随后正常工作,不受其中一个主节点宕机的影响。

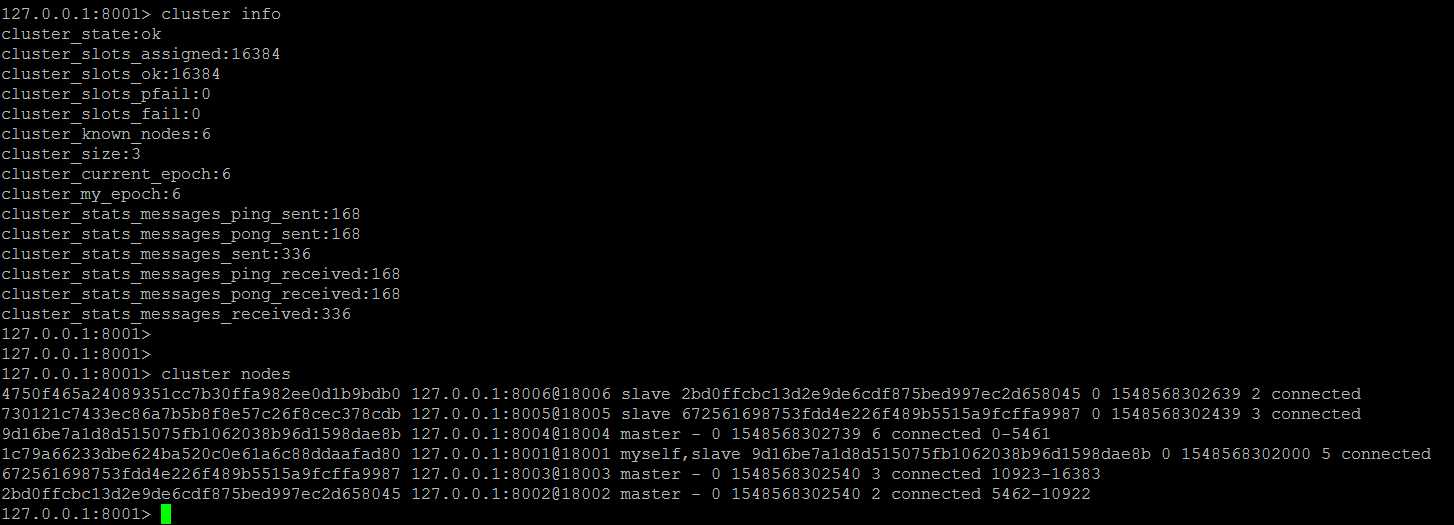
集群此时的状态,8001节点宕机,明显,8001对应的从节点8004接管主节点,升级为master,对外提供服务
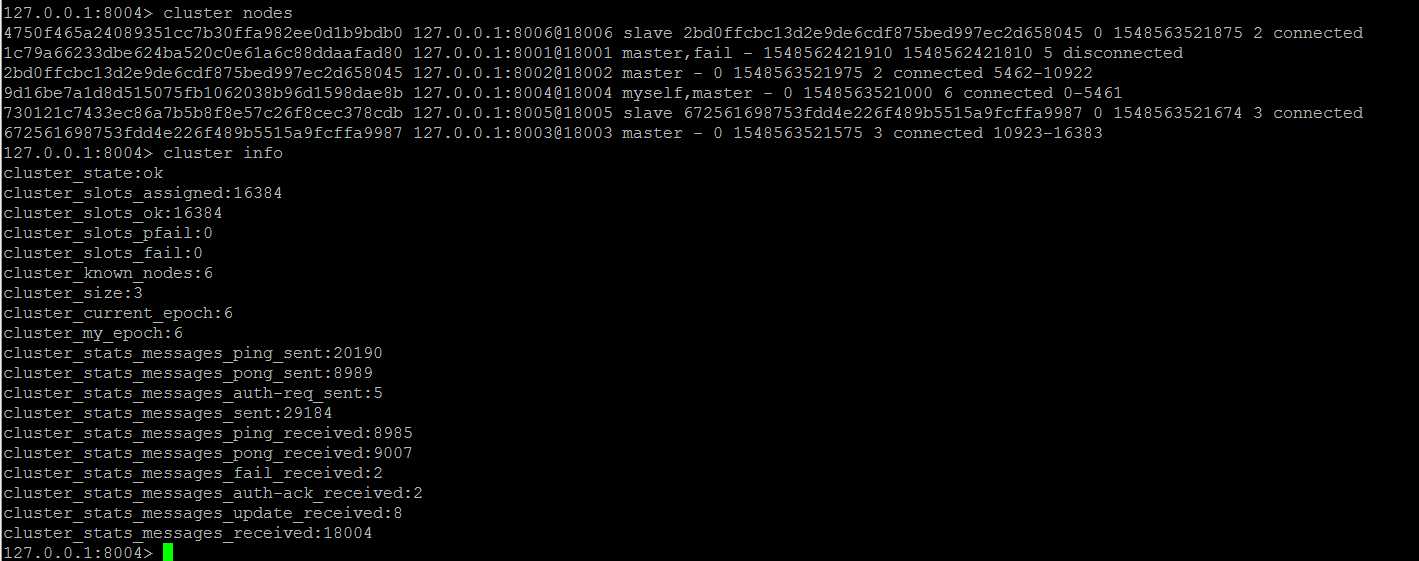
观察升级为主节点的8004实例日志,会发现在强制杀掉原8001主节点之后,1秒钟之内,成功替代8001升级为master节点
如果在故障转移的过程中,没有应用程序访问Redis,应用程序甚至完全不知道Redis集群发生了故障转移,只要不发生集群中某一个节点的主从节点同时宕机,整个集群就没有问题,且对应用程序完全透明。
随后重启宕机的8001节点,会发现8001节点自动变为其原从节点(8004)的从节点
整体上来看,Redis集群的配置和使用以及自动故障转移还是比较简单易容的,这里没有用redis-trib.rb 而是采用手动分配slot和创建集群的方式,目的是了解完整的配置流程。
需要注意的是:
1,如果开启了密码验证模式,所有的主从节点必须配置masterauth,因为某一个节点宕机重启之后,会自动变为从节点,此时如果想要从master复制数据,就必须需要主节点的密码
2,StrictRedisCluster决定了所有主从节点的密码必须要是一样的。
表面上看Redis集群简单易用,自动故障转移是没有问题的,保证了高可用,看似没有问题。
如果细想,这个过程还是有问题的,有没有发现,虽然故障转移保证了高可用,但是当从节点升级为主节点之后,如果保证升级为主节点的从节点(8004)一定能够完全复制原主节点(8001)上的数据?
这个就类似于MySQL的半同步复制,主节点上的数据,一定要同步(虽然是relaylog)到从节点,主节点才会提交。
不过回头想想,取决于如何去对待Redis或者怎么使用Redis,Redis更多的时候是作为一个缓存使用,而不是落地的数据库,既然是缓存,就应该更多地去考虑性能。
标签:slots 连接错误 左右 流程 python 必须 ++ 多实例 验证
原文地址:https://www.cnblogs.com/wy123/p/10325904.html