标签:使用场景 取出 ext 模糊 问题 请求 reduce 个数 sub
目录
以前没怎么写过技术类的文章,对于技术很多时候是现用现学,这样通常能解决遇到过的绝大多数问题,但也带来了一个弊端,那就是仅停留于解决问题的层面,而忽略了对技术背后的设计思想和设计理念进行深入的研究。虽然技术的发展日新月异,但那些终归只是由设计思想演绎出来的玩物,如果只是不断的去学习演绎出来的东西,而忽略了对思想的研究,就终究会陷入舍本逐末的恶性循环。
技术的提高离不开实践,实践有助于深化对技术的理解,但如果只实践而不加以总结的话也容易陷入只见树木不见森林的迷途。如果说实践是战术上的肉搏,那总结就是战略上的提炼,高屋建瓴,将实践中的精髓抽取出来,以达到去繁入简、返璞归真的境界。
鉴于此,也就打算把学习、实践过的技术进行再次的学习、总结,并以博文的形式记录下来,这样一方面有助于理清思路,建立知识体系,另一方面更有助于深入对技术的理解和掌握,这也是我打算开始写技术文章的初衷。
redux是一个库,用于管理状态,也可以说是一个容器,这个容器里容纳了各种需要的状态信息,并对外提供了一些方法来管理这些状态。目前redux更多的实践是和react结合,管理react的视图状态,但它也可以独立当作发布、订阅系统来使用。总之这些只是概念层面上的东西,实践完之后再来看概念就会容易理解,否则概念永远是模糊的。
redux有三大设计哲学:
1、单一数据源。
顾名思义就是所有的状态信息都存储在同一个容器里。
2、状态是只读的。
redux是用来管理状态的,竟然能管理,那就包含了对状态的增、删、改操作。这里的只读是指新状态不会破坏原来的旧状态,也就是说新状态的产生过程是:1、先从旧状态进行深拷贝得到一个复本。2、对复本进行操作得到新状态。
3、使用纯函数来更新状态。
纯函数是指输入相同的参数时,总能得到相同的输出结果,并且不会修改输入的参数。
这三大设计哲学主要是为了简化对状态的管理,让状态可预测、可追踪,从而易于维护代码,也更易于排查bug。
redux的工作流如下图所示:
https://slides.com/jenyaterpil/redux-from-twitter-hype-to-production#/9
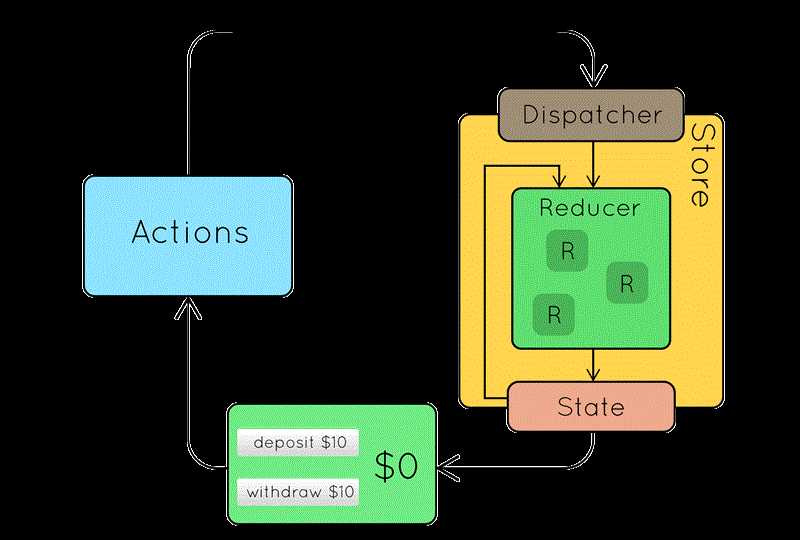
redux是管理状态的,所有的状态都存储在“store”里,所以store是一个数据中心,也是最核心的要素。同时store对外暴露了一些api用于管理store里的数据,这些api包括getState、dispatch、subscribe、replaceReducer。store是由createStore函数创建的,如:
const store = createStore(reducer, preloadedState, enhancer)createStore的实现原理如下:
const createStore = reducer => {
let state;
// listeners用来存储所有的监听函数
let listeners = [];
const getState = () => state;
const dispatch = action => {
state = reducer(state, action);
// 每一次状态更新后,都需要调用listeners数组中的每一个监听函数
listeners.forEach(listener => listener());
}
const subscribe = listener => {
// subscribe可能会被调用多交,每一次调用时,都将相关的监听函数存入listeners数组中
listeners.push(listener);
// 返回一个函数,进行取消订阅
return () => {
listeners = listeners.filter(item => item !== listener);
}
}
return { getState, dispatch, subscribe };
}dispatch用来派发一个action,所有对state的更新以及获取数据都是通过派发一个action来完成的。如:
let action1 = {
type: ‘READ_BOOK‘,
data: {
book: ‘book1‘
}
};
store.dispatch(action1);getState用于获取store里的状态数据,即state。如:
let state = store.getState();subscribe用于订阅store里的数据状态,当store里state数据变更时,通知订阅方。如:
const render = () => {
...
}
store.subscribe(render);这个一般开发用不到。
action是指一个操作动作,当需要操作store里的数据时,就需要分发一个action来通知store。每个action描述了一个操作,它是一个object的数据结构,有一个必填属性“type”,值是字符串常量,用于标识动作,可以理解为动作的ID,另外action对象里还可以携带其他数据信息,这要根据action所要完成的操作来定。
reducer是用来响应action来处理状态的,它会对每个分发的action进行操作,根据传过来的action和store里已有的sate值进行一些运算,然后返回新的state。
actionCreator是一个类似于工厂模式的生产工具,用于生产action。如:
const learnReduxActionFactory = book => {
type: ‘READ_REDUX_BOOK‘,
book
}combineReducers是Redux提供的一个工具函数,可以把多个拆分的reducer合并成一完整的reducer。
例如在页面状态中存储三种数据状态,分别为data1、data2和data3, 它们是相互独立的。如:
state = {
data1: {
...
},
data2: {
...
},
data3: {
...
}
};同样我们把处理这三种数据状态的reducer函数也拆分成三个小的reducer,分别为reducer1、reducer2和reducer3。如下:
const reducer1 = (previousState= {}, action) => {
// 根据action和state.data1计算产生新的state.data1
return state.data1;
};
const reducer2 = (previousState= {}, action) => {
// 根据action和state.data2计算产生新的state.data2
return state.data2;
}
const reducer3 = (previousState= {}, action) => {
// 根据action和state.data3计算产生新的state.data3
return state.data3;
}最后利用combineReducer将这三个子reducer函数合并成一个完整的reducer并返回。如下:
const { combineReducers } = Redux;
const finalReducer = combineReducers({
data1: reducer1,
data2: reducer2,
data3: reducer3
});在ES6开发环境下,常用的做法是令子reducer函数名称和数据状态的命名保持一致,即将reducer1、reducer2、reducer3分别命名为data1、data2、data3。即:
const finalReducer = combineReducers({
data1: data1,
data2: data2,
data3: data3
});也可以简写为:
const finalReducer = combineReducers({data1, data2, data3});日常开发中,通常会将大的reducer拆分成多个小的reducer进行单独维护,这样的分治能提高维护效率。
redux中间件提供的是位于action被派发之后,到达reducer之前的扩展点,因此可以利用redux中间件来完成日志记录、调用异步接口或者路由等。redux中间件的作用主要有两个:
1、截获action
2、发出action
redux中间件异步请求的工作流如下图所示:
https://slides.com/jenyaterpil/redux-from-twitter-hype-to-production#/23
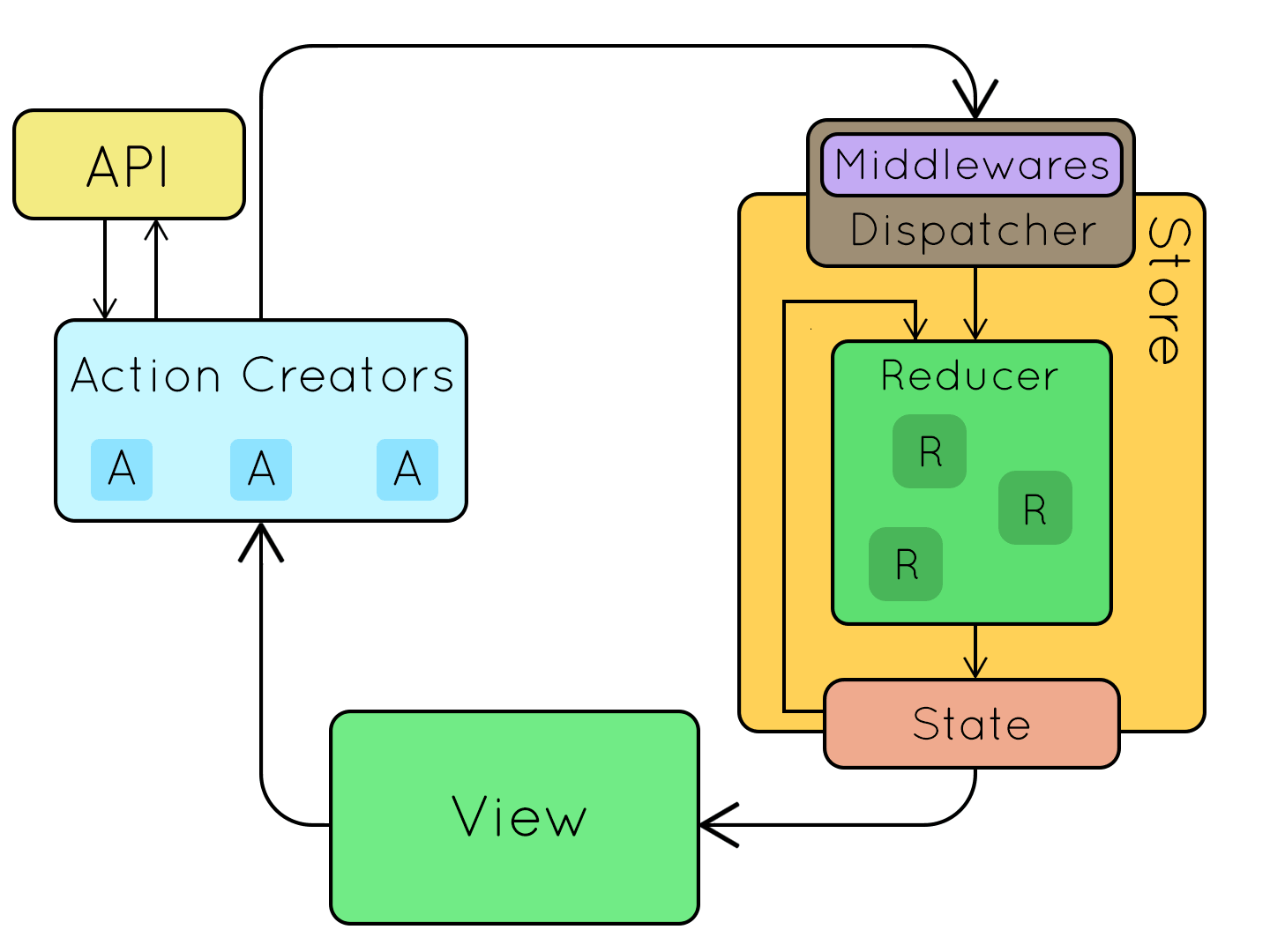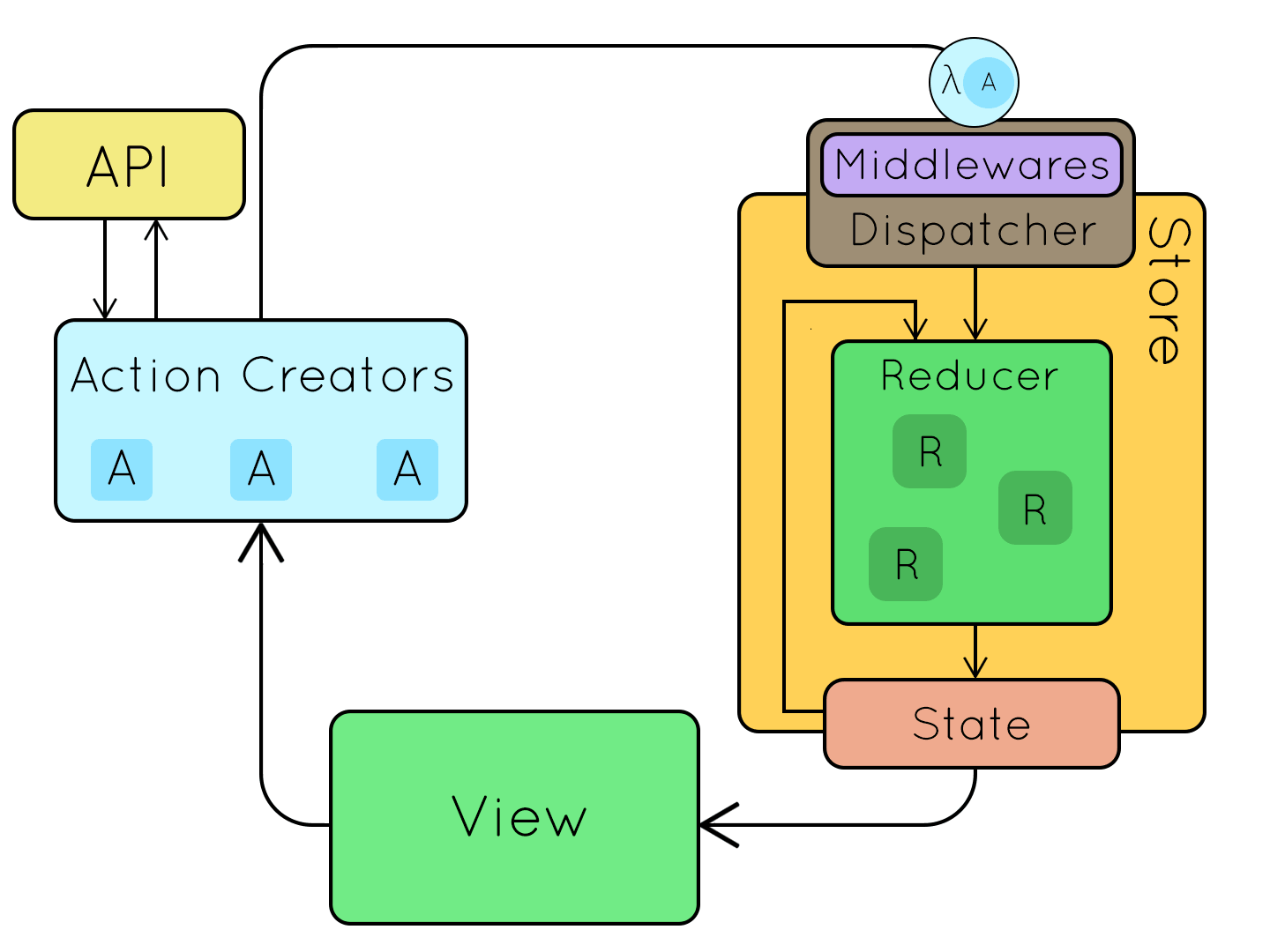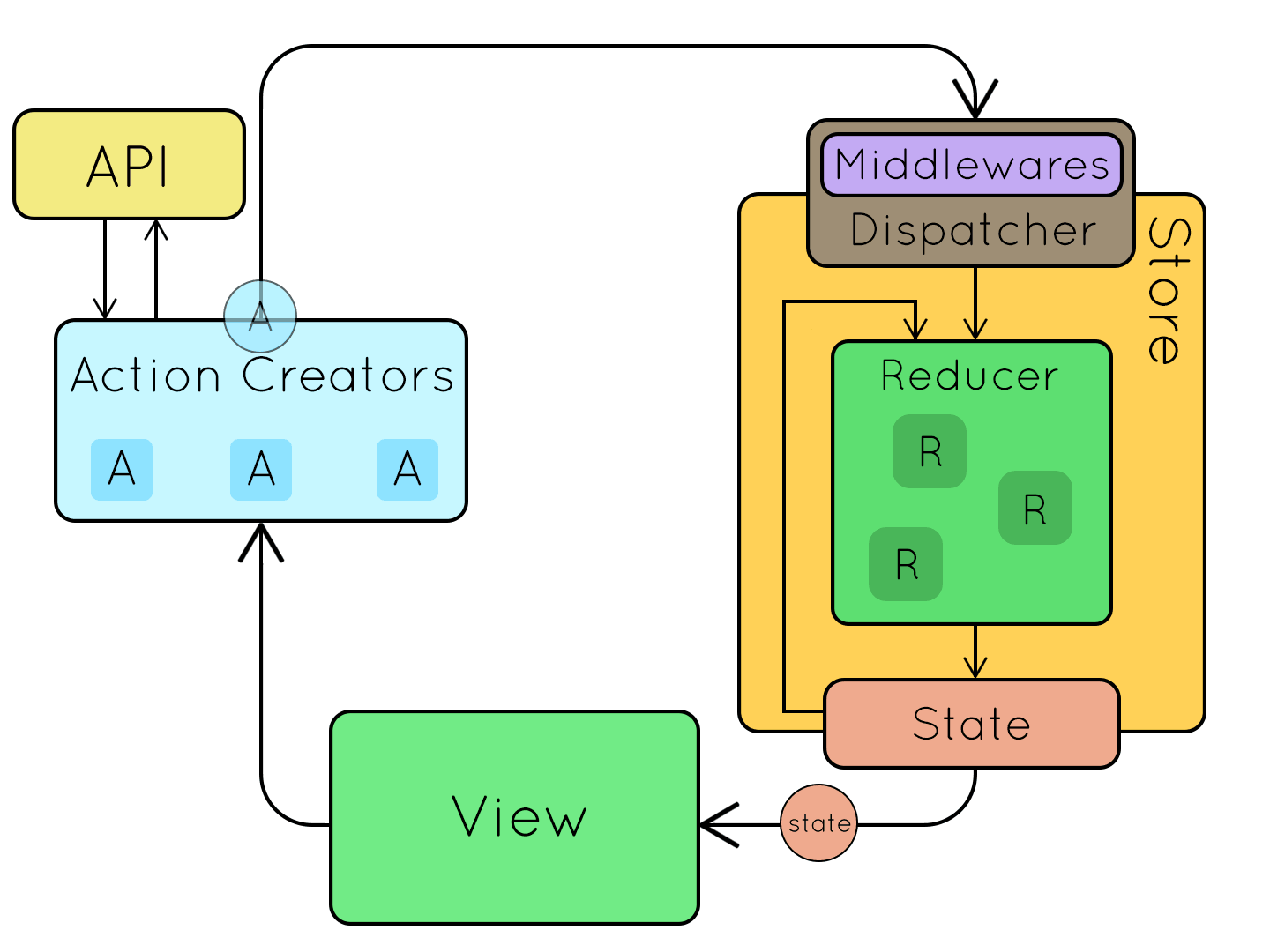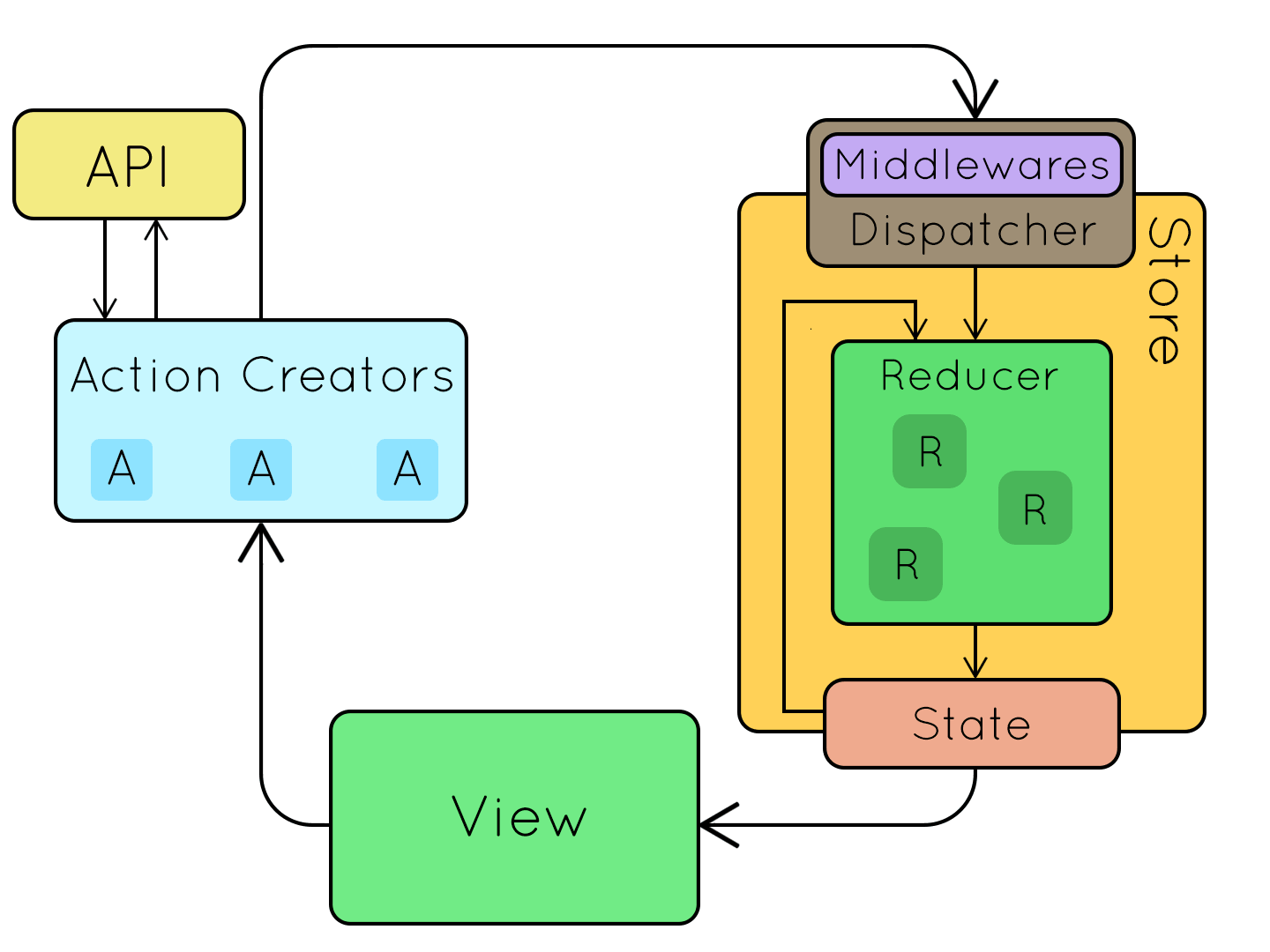
redux既可以作为发布订阅系统独立使用,也可以和react结合来管理react组件的状态。目前最常见的使用场景是与react结合,让react组件间通信更加容易。另外通过使用丰富的redux中间件,能扩展系统的特性。
标签:使用场景 取出 ext 模糊 问题 请求 reduce 个数 sub
原文地址:https://www.cnblogs.com/anlewo/p/10328201.html