标签:方法 parse pychar ati response tps 修改 需要 允许
Scrapy是一个异步处理框架,是纯Python实现的爬虫框架,其架构清晰,模块之间的耦合程度低,可拓展性强,可以灵活完成各种需求。我们只需要定制几个模块就可以轻松实现一个爬虫。
1.架构
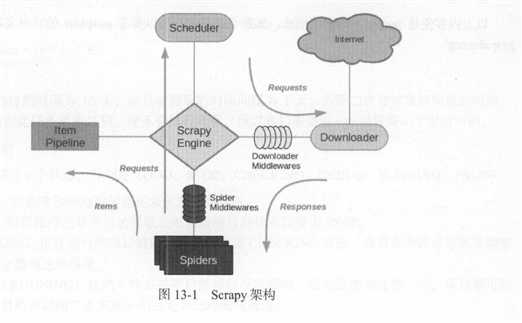
Scrapy Engine,引擎,负责整个系统的数据流处理、触发事务,是整个框架的核心。
Item,项目,它定义了爬取结果的数据结构,爬取的数据会被赋值成Item对象。
Scheduler,调度器,接受引擎发送过来的请求,并将其加入到队列之中,在引擎再次请求时将请求提供给引擎。
Downloader,下载器,下载网页内容,并将网页内容返回给爬虫。
Sprider,爬虫,其内定义了爬取逻辑和网页的解析规则,它主要负责解析响应并生成提取结果的新的请求。
Item Pipeline,项目管道,负责处理由爬虫从网页中提取的项目,它的主要任务是清洗、验证和存储数据。
Downloader Middlewares,下载器中间件,位于引擎和下载器直接的钩子框架,主要处理引擎与下载器之间的请求和响应。
Spider Middle,爬虫中间件,位于引擎和爬虫之间的钩子框架,主要处理爬虫输入的响应和输出的结果及新请求。
2.数据流
Scrapy中的数据流由引擎控制,数据流的过程如下:
(1)scrapy engine打开一个网站,找到该网站的Sprider,并向该Sprider请求第一个需要爬取的URL。
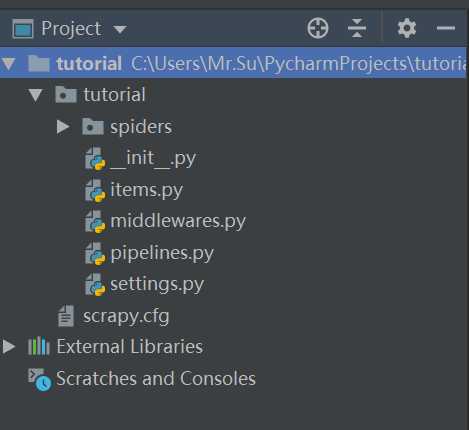
3.创建项目
在pycharm的终端Terminal : scrapy startproject tutorial ,
然后在pycharm打开该项目得到如下目录:
4.创建Spider
spider是自己定义的类,Scrapy用它来抓取内容。并解析抓取的结果。不过这个类必须继承Scrapy提供的Spider类scrapy.Sprider,还要定义Spider的名称和起始请求。
命令行创建spider : scrapy genspider quotes quotes.toscrape.com
# -*- coding: utf-8 -*- import scrapy class QuotesSpider(scrapy.Spider): name = ‘quotes‘ #用来区分不同的Spider allowed_domains = [‘quotes.toscrape.com‘] #允许爬取的域名 start_urls = [‘http://quotes.toscrape.com/‘] #spider启动时爬取的url列表 def parse(self, response):#负责解析返回的响应、提取数据或者进一步生成要处理的请求。
#response是爬取start_url的结果
pass
4.创建item
item需要继承scrapy.Item类,并且定义类型为scrapy.Field的字段。假设我们需要获取的内容是name、age、 sex。
修改item.py如下:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#保存和爬取数据的容器
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class QuoteItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
age = scrapy.Field()
sex = scrapy.Field()
pass
5.解析Response
spider里的parse()方法中的参数response是start——urls里面的链接爬取后的结果。所以在parse方法中,我们可以直接对response变量包含的内容进行解析。
标签:方法 parse pychar ati response tps 修改 需要 允许
原文地址:https://www.cnblogs.com/2sheep2simple/p/10331222.html