标签:数据 student school 恰恰 作用域 cti 一个个 image ima
是一种编程模型设计,即把特征(数据属性)与技能(方法属性)整合作为一个结合体,这个结合体即对象,一切皆为对象。
基于面向对象设计程序就好比在创造一个世界,你就是这个世界的上帝,世间存在的万物皆为对象,不存在的也可以创造出来。
好比西游记中,如来佛祖要解决的问题是把经书传给东土大唐,如来想了想解决这个问题需要四个人:唐僧,沙和尚,猪八戒,孙悟空,每个人都有各自的特征和技能(这就是对象的概念,特征和技能分别对应对象的数据属性和方法属性),然而这并不好玩,于是如来又安排了一群妖魔鬼怪,为了防止师徒四人在取经路上被搞死,又安排了一群神仙保驾护航,这些都是对象。然后取经开始,师徒四人与妖魔鬼怪神仙交互着直到最后取得真经。如来根本不会管师徒四人按照什么流程去取经(面向过程)。
注意,这是一种程序设计思想,很多人存在一个误区:只有用class定义类的代码才是面向对象
def dog (name,type): def jiao(dog): print(‘一条叫%s的狗,汪汪汪‘%dog[‘name‘]) def init(name,type): dog = {‘name‘:name , ‘type‘:type , ‘jiao‘:jiao} #name和type是数据属性,jiao是方法属性,三者用一个字典封装,用来初始化实例 return dog return init(name,type) d1 = dog(‘小强‘,‘二哈‘) #实例化一个对象d1 print(d1) d1[‘jiao‘](d1)
结果:
{‘name‘: ‘小强‘, ‘type‘: ‘二哈‘, ‘jiao‘: <function dog.<locals>.jiao at 0x000001DB61F946A8>}
一条叫小强的狗,汪汪汪
这个例子用函数嵌套的的方式,没有用到class,却是一个地地道道的面向对象程序设计,狗的姓名和种类是数据属性,叫是狗的方法属性,这三者作为一个结合体,组成一个‘dog类‘,来实例化一个个对象。
用定义类+对象(实例)的方式去实现面向对象的设计
面向对象设计(OOD)不会特别要求面向对象编程语言。事实上,OOD完全可以由纯结构化语言来实现,只不过要想构造具备对象性质和特点的数据类型,就需要在程序上做更多的努力。比如用纯C写的linux kernel其实比c++/java写的大多数项目更加面向对象,linus的泛文件抽象(一切皆文件)恰恰就是面向对象的设计。
所以面向对象编程和面向对象设计是八竿子打不着两码事,一个是方法论,一个是设计思路
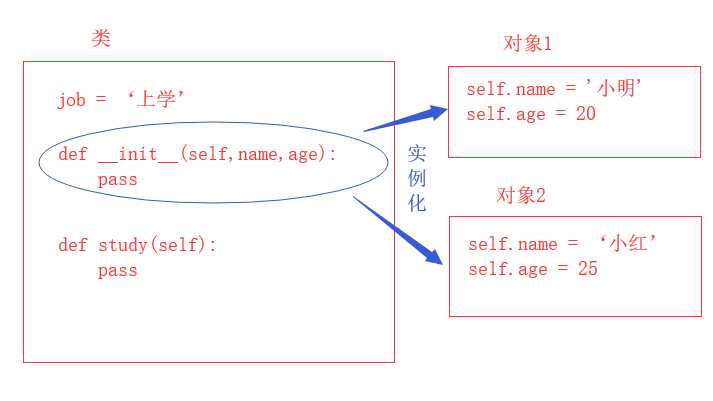
类即类别、种类,是面向对象设计最重要的概念,对象是特征与技能的结合体,而类则是一系列对象相似的特征与技能的结合体,调用类就可以实例化一个个对象
那么问题来了,先有的一个个具体存在的对象(比如一个具体存在的人),还是先有的人类这个概念,这个问题需要分两种情况去看
在现实世界中:先有对象,再有类
世界上肯定是先出现各种各样的实际存在的物体,然后随着人类文明的发展,人类站在不同的角度总结出了不同的种类,如人类、动物类、植物类等概念
也就说,对象是具体的存在,而类仅仅只是一个概念,并不真实存在
在程序中:务必保证先定义类,后产生对象
这与函数的使用是类似的,先定义函数,后调用函数,类也是一样的,在程序中需要先定义类,后调用类
不一样的是,调用函数会执行函数体代码返回的是函数体执行的结果return,而调用类会产生对象,返回的是对象
实例化:
class student: job = ‘上学‘ def __init__(self,name,age): self.name = name self.age = age def study(self): print(‘%s背着书包上学‘ %self.name) p1 = student(‘小明‘,18) print(student.__dict__) #类的属性列表 print(p1.__dict__) #对象的属性列表 print(student.job) #类的数据属性 print(p1.job) #对象访问类的数据属性 print(p1.study) #对象访问类的方法属性 print(p1.name) #对象的数据属性 # print(student.name) #类访问对象的数据属性,报错 p1.study()
结果:
{‘__weakref__‘: <attribute ‘__weakref__‘ of ‘student‘ objects>, ‘__doc__‘: None, ‘__dict__‘: <attribute ‘__dict__‘ of ‘student‘ objects>, ‘study‘: <function student.study at 0x000001A60C384620>, ‘__init__‘: <function student.__init__ at 0x000001A60C3846A8>, ‘__module__‘: ‘__main__‘, ‘job‘: ‘上学‘}
{‘name‘: ‘小明‘, ‘age‘: 18}
上学
上学
<bound method student.study of <__main__.student object at 0x000001A60C381DA0>>
小明
小明背着书包上学
个人总结:
类的实例化即产生一个个对象,通过执行类的__init__()方法
类和对象都有__dict__内置属性,返回一个属性列表;对数据属性和方法属性的所有操作,都可以当做在操作这个__dict__返回的字典
类有数据属性和方法属性,而严格的讲:对象只有数据属性没有方法属性;如下图类的__init__()方法中,只有对数据属性的定义赋值
那为什么每个对象都有方法属性,并可以访问类属性?是因为通过寻址引用的方式;所以,一旦类中的方法属性发生变化,对象中的方法属性也马上变化(不论这个对象是否已经被实例化)
实例化只赋予对象的数据属性,而对象通过寻址引用的方式调用类的方法属性,这样可以节省内存
对象可以访问类的属性,而类无法访问对象的属性,对象的作用域是先找自己的属性列表(__dict__方法),再找类的属性列表
class student: #定义student类 job = ‘上学‘ #类的数据属性 def __init__(self,name,age): self.name = name self.age = age def study(self): #类的方法属性 print(‘%s背着书包上学‘ %self.name) p1 = student(‘小明‘,18) #实例化一个对象p1 #查 print(student.job) #类名加.的方式访问类属性 print(p1.job) #对象也可以访问类属性,对象名加.的方式访问类属性 #增 student.country = ‘中国‘ #新增类的数据属性 print(p1.country) def eat_food(self,food): #新增类的方法属性 print(‘%s正在吃%s‘ %(self.name,food)) student.eat = eat_food #把eat_food函数的内存地址给student类的eat方法属性,这里eat_food不能加括号,加了括号就是eat_food()执行后的返回值 p1.eat(‘米饭‘) #改 student.country = ‘日本‘ #修改类的数据属性 print(p1.country) def test(self): #修改类的方法属性,但方法属性名还是study print(‘test‘) student.study = test p1.study() #删 del student.job print(p1.job) #删除类的数据属性后会报错
class student: job = ‘上学‘ def __init__(self,name,age): self.name = name self.age = age def study(self): print(‘%s背着书包上学‘ %self.name) p1 = student(‘小明‘,18) #查 print(p1.age) #查看对象的数据属性 print(p1.study) #查看对象的方法属性,是寻址引用类的方法属性 #增 p1.female = ‘boy‘ #新增对象的数据属性 print(p1.female) def test(): #新增对象的方法属性,一般不这么用,对象不会独自去定义一个类中没有的方法,没有意义 print(‘aaa‘) p1.test = test p1.test() #改 #修改对象的数据属性 p1.age = 20 print(p1.age) #删 # del p1.age #删除对象的数据属性 # print(p1.age)
结果:
18
<bound method student.study of <__main__.student object at 0x00000248CB26A828>>
boy
aaa
20
1.通过对象可以访问类的数据属性,但无法修改类的数据属性
class student: job = ‘上学‘ def __init__(self,name,age): self.name = name self.age = age def study(self): print(‘%s背着书包上学‘ %self.name) p1 = student(‘小明‘,18) p1.job = ‘上班‘ #这样定义其实是新增了一个p1对象的数据属性,与类的数据属性无关。可以这样理解:一个个对象是类实例化出来的,如果通过一个对象就可以改变类的数据属性,那么其他的对象岂不是也变了 print(p1.job) #上班 print(student.job) #上学
但是,也有个例:
class student: job = ‘上学‘ l = [‘a‘,‘b‘] def __init__(self,name,age): self.name = name self.age = age def study(self): print(‘%s背着书包上学‘ %self.name) p1 = student(‘小明‘,18) # p1.l = [1,2,3] #通过这种方式不会改变类的数据属性,而是新增了p1对象的数据属性,会在对象的__dict__列表属性中添加,不会在类的__dict__列表属性中添加 # print(student.l) p1.l.append(‘c‘) #通过这种方式会改变类的数据属性,引用了类的数据属性,恰恰是一个list可变数据类型 print(student.l)
结果: [‘a‘, ‘b‘, ‘c‘]
2.加点的调用方式才是类和对象的属性,不加点的调用方式与类和对象都无关
school = ‘初中‘ #全局变量school class student: job = ‘上学‘ school = ‘高中‘ #类的数据属性school def __init__(self,name,age): self.name = name self.age = age print(school) #初中 不加点的调用方式,这个school既不会去类的属性列表中找,也不会去对象的属性列表中找,所以就是全局变量school print(student.school) #高中 在类的属性列表中找到school这个键值对 def study(self): print(‘%s背着书包上学‘ %self.name) p1 = student(‘小明‘,18)
标签:数据 student school 恰恰 作用域 cti 一个个 image ima
原文地址:https://www.cnblogs.com/xulan0922/p/10321649.html