标签:类型 说明 会同 特征 尺度 包含 准确率 元类 操作
为了将逻辑回归值映射到二元类别,必须指定分类阈值(也称为判定阈值)。
如果值高于该阈值,则表示“1”;如果值低于该阈值,则表示“0”。
人们往往会认为分类阈值应始终为 0.5,但阈值取决于具体问题,因此必须对其进行调整。
准确率是一个用于评估分类模型的指标。
通俗来说,准确率是指我们的模型预测正确的结果所占的比例。
对于二元分类,也可以根据正类别和负类别按如下方式计算准确率(TP=真正例,TN=真负例,FP=假正例,FN=假负例):
$\text{Accuracy} = \frac{TP+TN}{TP+TN+FP+FN}$
当使用分类不平衡的数据集(比如正类别标签和负类别标签的数量之间存在明显差异)时,单单准确率一项并不能反映全面情况。
精确率
在被识别为正类别的样本中,确实为正类别的比例是多少?
定义:$\text{Precision} = \frac{TP}{TP+FP}$
注意:如果模型的预测结果中没有假正例,则模型的精确率为 1.0。
召回率
在所有正类别样本中,被正确识别为正类别的比例是多少?
定义:$\text{召回率} = \frac{TP}{TP+FN}$
注意:如果模型的预测结果中没有假负例,则模型的召回率为 1.0。
精确率和召回率:一场拔河比赛
要全面评估模型的有效性,必须同时检查精确率和召回率。
遗憾的是,精确率和召回率往往是此消彼长的情况。也就是说,提高精确率通常会降低召回率值,反之亦然。
一般来说,在逻辑回归模型中
ROC曲线
ROC曲线(接收者操作特征曲线)是一种显示分类模型在所有分类阈值下的效果的图表。
该曲线绘制了以下两个参数:真正例率、假正例率。
ROC 曲线用于绘制采用不同分类阈值时的 TPR 与 FPR。降低分类阈值会导致将更多样本归为正类别,从而增加假正例和真正例的个数。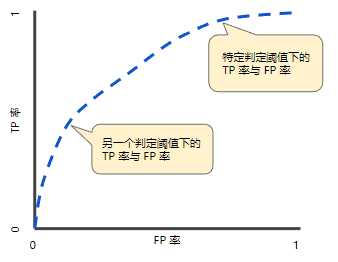
曲线下面积:ROC 曲线下面积
曲线下面积表示“ROC 曲线下面积”。也就是说,曲线下面积测量的是从 (0,0) 到 (1,1) 之间整个 ROC 曲线以下的整个二维面积。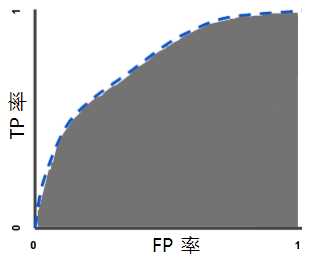
曲线下面积对所有可能的分类阈值的效果进行综合衡量。
曲线下面积的一种解读方式是看作模型将某个随机正类别样本排列在某个随机负类别样本之上的概率。
曲线下面积的取值范围为 0-1。预测结果 100% 错误的模型的曲线下面积为 0.0;而预测结果 100% 正确的模型的曲线下面积为 1.0。
曲线下面积比较实用的原因:
不过,这两个原因都有各自的局限性,这可能会导致曲线下面积在某些用例中不太实用:
并非总是希望尺度不变。
例如,有时我们非常需要被良好校准的概率输出,而曲线下面积无法告诉我们这一结果。
并非总是希望分类阈值不变。
在假负例与假正例的代价存在较大差异的情况下,尽量减少一种类型的分类错误可能至关重要。
例如,在进行垃圾邮件检测时,您可能希望优先考虑尽量减少假正例(即使这会导致假负例大幅增加)。
对于此类优化,曲线下面积并非一个实用的指标。
逻辑回归预测应当无偏差。即:“预测平均值”应当约等于“观察平均值”
预测偏差指的是这两个平均值之间的差值,即:$\text{预测偏差} = \text{预测平均值} - \text{数据集中相应标签的平均值}$
如果出现非常高的非零预测偏差,则说明模型某处存在错误,因为这表明模型对正类别标签的出现频率预测有误。
造成预测偏差的可能原因包括:
可能会通过对学习模型进行后期处理来纠正预测偏差,即通过添加校准层来调整模型的输出,从而减小预测偏差。
但是,添加校准层并非良策,具体原因如下:
如果可能的话,请避免添加校准层。
使用校准层的项目往往会对其产生依赖 - 使用校准层来修复模型的所有错误。
最终,维护校准层可能会令人苦不堪言。
注意:
出色模型的偏差通常接近于零。即便如此,预测偏差低并不能证明模型比较出色。
特别糟糕的模型的预测偏差也有可能为零。例如,只能预测所有样本平均值的模型是糟糕的模型,尽管其预测偏差为零。
分桶偏差和预测偏差
必须在“一大桶”样本中检查预测偏差。
也就是说,只有将足够的样本组合在一起以便能够比较预测值与观察值,逻辑回归的预测偏差才有意义。
可以通过以下方式构建桶:
为什么只有模型的某些部分所做的预测如此糟糕?以下是几种可能性:
1- 让我们以一种将电子邮件分为“垃圾邮件”或“非垃圾邮件”这两种类别的分类模型为例。如果提高分类阈值,精确率会怎样?
2- 让我们以一种将电子邮件分为“垃圾邮件”或“非垃圾邮件”这两种类别的分类模型为例。如果提高分类阈值,召回率会怎样?
3- 以两个模型(A 和 B)为例,这两个模型分别对同一数据集进行评估。 以下哪一项陈述属实?
4- 将给定模型的所有预测结果都乘以 2.0(例如,如果模型预测的结果为 0.4,我们将其乘以 2.0 得到 0.8),会使按 AUC 衡量的模型效果产生何种变化?
1- 可能会提高。一般来说,提高分类阈值会减少假正例,从而提高精确率。
2- 始终下降或保持不变。提高分类阈值会导致真正例的数量减少或保持不变,而且会导致假负例的数量增加或保持不变。因此,召回率会保持不变或下降。
3- 如果模型 A 的精确率和召回率均优于模型 B,则模型 A 可能更好。
一般来说,如果某个模型在精确率和召回率方面均优于另一模型,则该模型可能更好。很显然,我们需要确保在精确率/召回率点处进行比较,这在实践中非常有用,因为这样做才有实际意义。例如,假设我们的垃圾邮件检测模型需要达到至少 90% 的精确率才算有用,并可以避免不必要的虚假警报。在这种情况下,将 {20% 精确率,99% 召回率} 模型与另一个 {15% 精确率,98% 召回率} 模型进行比较不是特别有意义,因为这两个模型都不符合 90% 的精确率要求。但考虑到这一点,在通过精确率和召回率比较模型时,这是一种很好的方式。
4- 没有变化。AUC 只关注相对预测分数。
没错,AUC 以相对预测为依据,因此保持相对排名的任何预测变化都不会对 AUC 产生影响。而对其他指标而言显然并非如此,例如平方误差、对数损失函数或预测偏差(稍后讨论)。
xxx
二元分类 (binary classification)
一种分类任务,可输出两种互斥类别之一。
例如,对电子邮件进行评估并输出“垃圾邮件”或“非垃圾邮件”的机器学习模型就是一个二元分类器。
分类阈值 (classification threshold)
一种标量值条件,应用于模型预测的得分,旨在将正类别与负类别区分开。
将逻辑回归结果映射到二元分类时使用。
以某个逻辑回归模型为例,该模型用于确定指定电子邮件是垃圾邮件的概率。
如果分类阈值为 0.9,那么逻辑回归值高于 0.9 的电子邮件将被归类为“垃圾邮件”,低于 0.9 的则被归类为“非垃圾邮件”。
混淆矩阵 (confusion matrix)
一种 NxN 表格,用于总结分类模型的预测效果;即标签和模型预测的分类之间的关联。
在混淆矩阵中,一个轴表示模型预测的标签,另一个轴表示实际标签。N 表示类别个数。在二元分类问题中,N=2。
例如,下面显示了一个二元分类问题的混淆矩阵示例:
上面的混淆矩阵显示,在 19 个实际有肿瘤的样本中,该模型正确地将 18 个归类为有肿瘤(18 个正例),错误地将 1 个归类为没有肿瘤(1 个假负例)。
同样,在 458 个实际没有肿瘤的样本中,模型归类正确的有 452 个(452 个负例),归类错误的有 6 个(6 个假正例)。
多类别分类问题的混淆矩阵有助于确定出错模式。
例如,某个混淆矩阵可以揭示,某个经过训练以识别手写数字的模型往往会将 4 错误地预测为 9,将 7 错误地预测为 1。
混淆矩阵包含计算各种效果指标(包括精确率和召回率)所需的充足信息。
正类别 (positive class)
在二元分类中,两种可能的类别分别被标记为正类别和负类别。
正类别结果是我们要测试的对象。(不可否认的是,我们会同时测试这两种结果,但只关注正类别结果。)例如,在医学检查中,正类别可以是“肿瘤”。
在电子邮件分类器中,正类别可以是“垃圾邮件”。
与负类别相对。
负类别 (negative class)
在二元分类中,一种类别称为正类别,另一种类别称为负类别。
正类别是我们要寻找的类别,负类别则是另一种可能性。例如,在医学检查中,负类别可以是“非肿瘤”。
在电子邮件分类器中,负类别可以是“非垃圾邮件”。
另请参阅正类别。
正例 (TP, true positive)
被模型正确地预测为正类别的样本。
例如,模型推断出某封电子邮件是垃圾邮件,而该电子邮件确实是垃圾邮件。
负例 (TN, true negative)
被模型正确地预测为负类别的样本。
例如,模型推断出某封电子邮件不是垃圾邮件,而该电子邮件确实不是垃圾邮件。
假正例 (FP, false positive)
被模型错误地预测为正类别的样本。
例如,模型推断出某封电子邮件是垃圾邮件(正类别),但该电子邮件其实不是垃圾邮件。
假负例 (FN, false negative)
被模型错误地预测为负类别的样本。
例如,模型推断出某封电子邮件不是垃圾邮件(负类别),但该电子邮件其实是垃圾邮件。
准确率 (accuracy)
分类模型的正确预测所占的比例。
在多类别分类中,准确率的定义:$\text{准确率} = \frac{\text{正确的预测数}} {\text{样本总数}}$
在二元分类中,准确率的定义:$\text{准确率} = \frac{\text{正例数} + \text{负例数}} {\text{样本总数}}$
分类不平衡的数据集 (class-imbalanced data set)
一种二元分类问题,在此类问题中,两种类别的标签在出现频率方面具有很大的差距。
例如,在某个疾病数据集中,0.0001 的样本具有正类别标签,0.9999 的样本具有负类别标签,这就属于分类不平衡问题;但在某个足球比赛预测器中,0.51 的样本的标签为其中一个球队赢,0.49 的样本的标签为另一个球队赢,这就不属于分类不平衡问题。
精确率 (precision)
一种分类模型指标。精确率指模型正确预测正类别的频率,即:
$\text{精确率} = \frac{\text{正例数}} {\text{正例数} + \text{假正例数}}$
召回率 (recall)
一种分类模型指标,用于回答以下问题:在所有可能的正类别标签中,模型正确地识别出了多少个?即:
$\text{召回率} = \frac{\text{正例数}} {\text{正例数} + \text{假负例数}}$
ROC 曲线下面积 (AUC, Area under the ROC Curve)
一种会考虑所有可能分类阈值的评估指标。
ROC 曲线下面积是,对于随机选择的正类别样本确实为正类别,以及随机选择的负类别样本为正类别,分类器更确信前者的概率。
受试者工作特征曲线(receiver operating characteristic,简称 ROC 曲线)
不同分类阈值下的正例率和假正例率构成的曲线。另请参阅曲线下面积。
分桶 (bucketing)
将一个特征(通常是连续特征)转换成多个二元特征(称为桶或箱),通常根据值区间进行转换。
例如,您可以将温度区间分割为离散分箱,而不是将温度表示成单个连续的浮点特征。
假设温度数据可精确到小数点后一位,则可以将介于 0.0 到 15.0 度之间的所有温度都归入一个分箱,将介于 15.1 到 30.0 度之间的所有温度归入第二个分箱,并将介于 30.1 到 50.0 度之间的所有温度归入第三个分箱。
校准层 (calibration layer)
一种预测后调整,通常是为了降低预测偏差的影响。
调整后的预测和概率应与观察到的标签集的分布一致。
预测偏差 (prediction bias)
一种值,用于表明预测平均值与数据集中标签的平均值相差有多大。
标签:类型 说明 会同 特征 尺度 包含 准确率 元类 操作
原文地址:https://www.cnblogs.com/anliven/p/10336463.html