标签:情况下 激活 特征 边界条件 针对 ini 论文 mode 设计原则
2014年,牛津大学计算机视觉组(Visual Geometry Group)和Google DeepMind公司的研究员一起研发出了新的深度卷积神经网络:VGGNet,并取得了ILSVRC2014比赛分类项目的第二名(第一名是GoogLeNet,也是同年提出的).论文下载 Very Deep Convolutional Networks for Large-Scale Image Recognition。论文主要针对卷积神经网络的深度对大规模图像集识别精度的影响,主要贡献是使用很小的卷积核(\(3\times3\))构建各种深度的卷积神经网络结构,并对这些网络结构进行了评估,最终证明16-19层的网络深度,能够取得较好的识别精度。 这也就是常用来提取图像特征的VGG-16和VGG-19。
VGG可以看成是加深版的AlexNet,整个网络由卷积层和全连接层叠加而成,和AlexNet不同的是,VGG中使用的都是小尺寸的卷积核(\(3\times3\))。
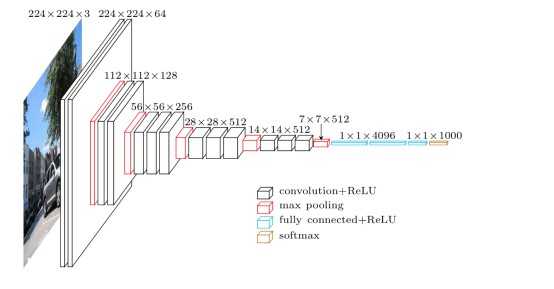
对比,前文介绍的AlexNet的网络结构图,是不是有种赏心悦目的感觉。整个结构只有\(3\times3\)的卷积层,连续的卷积层后使用池化层隔开。虽然层数很多,但是很简洁。
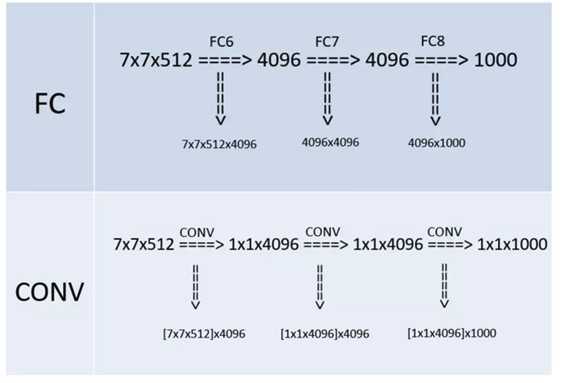
例如\(7 \times 7 \times 512\)的层要跟4096个神经元的层做全连接,则替换为对\(7 \times 7 \times 512\)的层作通道数为4096、卷积核为\(1 \times 1\)卷积。
这个“全连接转卷积”的思路是VGG作者参考了OverFeat的工作思路,例如下图是OverFeat将全连接换成卷积后,则可以来处理任意分辨率(在整张图)上计算卷积,这就是无需对原图做重新缩放处理的优势。
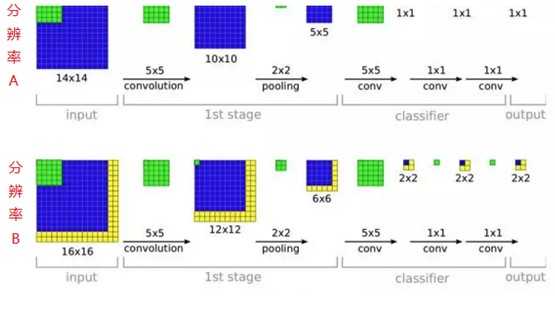
VGG网络相比AlexNet层数多了不少,但是其结构却简单不少。
VGG论文主要是研究网络的深度对其分类精度的影响,所以按照上面的描述设计规则,作者实验的了不同深度的网络结构
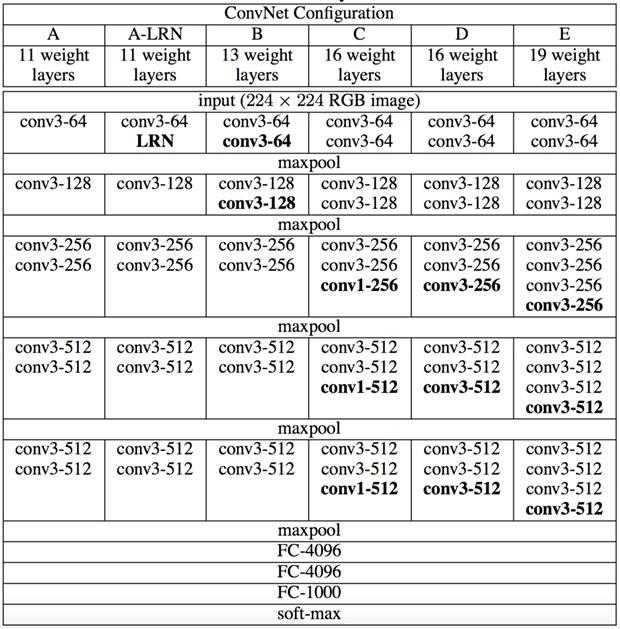
所有网络结构都遵从上面提到的设计规则,并且仅是深度不同,也就是卷积层的个数不同:从网络A中的11个加权层(8个卷积层和3个FC层)到网络E中的19个加权层(16个卷积层和3个FC层)。卷积层的宽度(通道数)相当小,从第一层中的64开始,然后在每个最大池化层之后增加2倍,直到达到512。
上图给出了各个深度的卷积层使用的卷积核大小以及通道的个数。最后的D,E网络就是大名鼎鼎的VGG-16和VGG-19了。
AlexNet仅仅只有8层,其可训练的参数就达到了60M,VGG系列的参数就更恐怖了,如下图(单位是百万)

由于参数大多数集中在后面三个全连接层,所以虽然网络的深度不同,全连接层确实相同的,其参数区别倒不是特别的大。
论文首先将训练图像缩放到最小边长度的方形,设缩放后的训练图像的尺寸为\(S \times S\)。网络训练时对训练图像进行随机裁剪,裁剪尺寸为网络的输入尺寸\(224 \times 224\)。如果\(S =224\),则输入网络的图像就是整个训练图像;如果\(S > 224\),则随机裁剪训练图像包含目标的部分。
对于训练集图像的尺寸设置,论文中使用了两种方法:
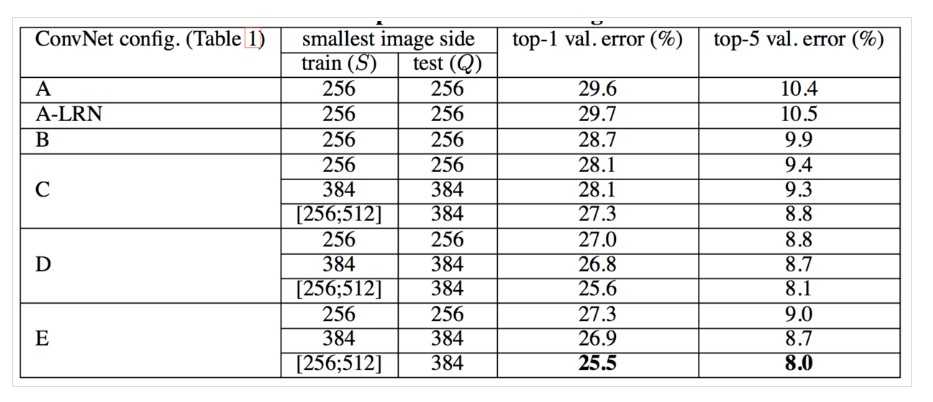
多尺度评估,测试图像的尺度抖动对性能的影响
对同一张测试图像,将其缩放到不同的尺寸进行测试,然后取这几个测试结果的平均值,作为最终的结果(有点像集成学习,所不同的是,这里是测试图像的尺寸不同)。使用了三种尺寸的测试图像:\(Q\)表示测试图像,\(S\)表示训练是图像尺寸:\(Q = S - 32\),\(Q = S + 32\),前面两种是针对训练图像是固定大小的,对于训练时图像尺寸在一定范围内抖动的,则可以使用更大的测试图像尺寸。\(Q = \{S_{min},0.5(S_{min} + S_{max}),S_{max}\}\).
评估结果如下:
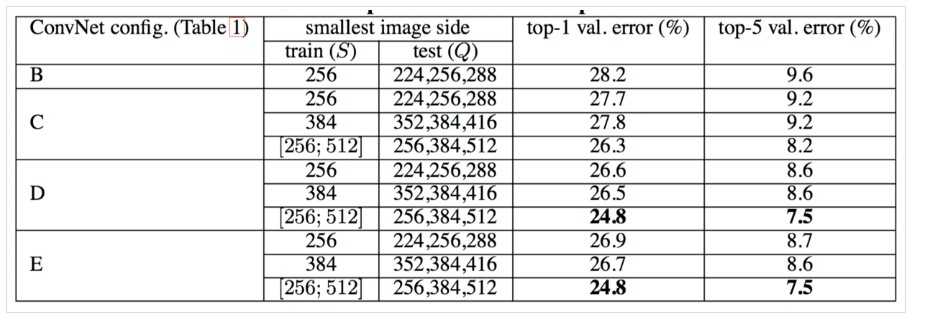
评估结果表明,训练图像尺度抖动优于使用固定最小边S。
稠密和多裁剪图像评估
Dense(密集评估),即指全连接层替换为卷积层(第一FC层转换到7×7卷积层,最后两个FC层转换到1×1卷积层),最后得出一个预测的score map,再对结果求平均。
multi-crop,即对图像进行多样本的随机裁剪,将得到多张裁剪得到的图像输入到网络中,最终对所有结果平均
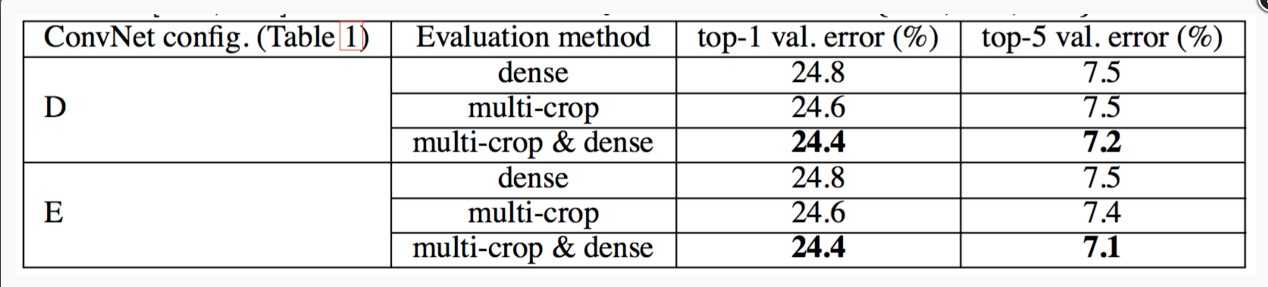
从上图可以看出,多裁剪的结果是好于密集估计的。而且这两种方法确实是互补的,因为它们的组合优于其中的每一种。
由于不同的卷积边界条件,多裁剪图像评估是密集评估的补充:当将ConvNet应用于裁剪图像时,卷积特征图用零填充,而在密集评估的情况下,相同裁剪图像的填充自然会来自于图像的相邻部分(由于卷积和空间池化),这大大增加了整个网络的感受野,因此捕获了更多的图像内容信息。
依照VGG的设计原则,只使用小尺寸的\(3\times3\)卷积核以及\(2 \times 2\)的池化单元,实现一个小型的网络模型。
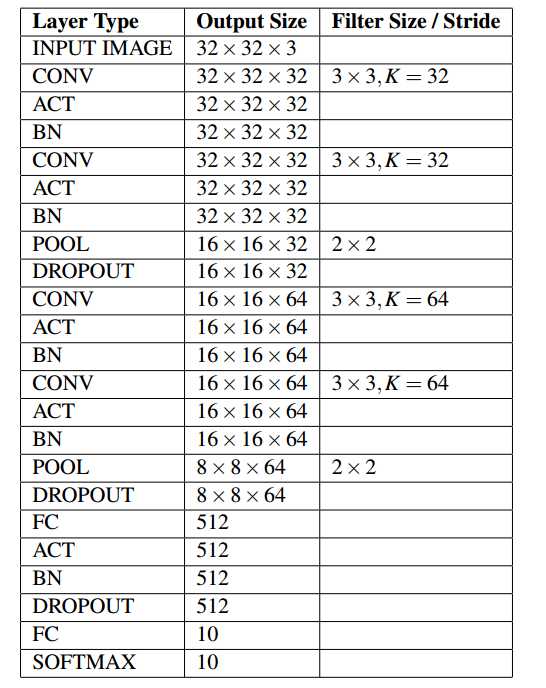
class MiniVGGNet:
@staticmethod
def build(width,height,depth,classes):
model = Sequential()
inputShape = (height,width,depth)
chanDim = -1
if K.image_data_format() == "channels_first":
inputShape = (depth,height,width)
chanDim = 1
model.add(Conv2D(32,(3,3),padding="same",input_shape=inputShape))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(32,(3,3),padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Conv2D(64,(3,3),padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(64,(3,3),padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation("relu"))
model.add(BatchNormalization())
model.add(Dropout(0.25))
model.add(Dense(classes))
model.add(Activation("softmax"))
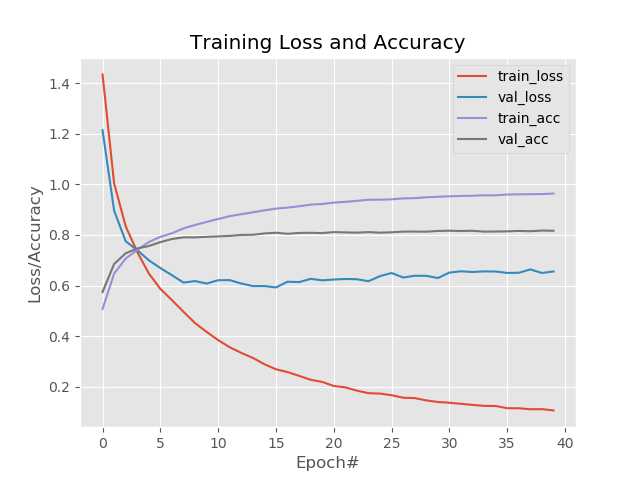
return model最终输出10分类,应用于CIFAR10,表现如下:
标签:情况下 激活 特征 边界条件 针对 ini 论文 mode 设计原则
原文地址:https://www.cnblogs.com/wangguchangqing/p/10338560.html