标签:heap centos 最大 ima file syn home 3.2 tick
1) ZooKeeper
是一个分布式的、分层级的文件系统,能促进客户端间的松耦合,并提供最终一致的,用于管理、协调Kafka代理,zookeeper集群中一台服务器作为Leader,其它作为Follower
2) Apache Kafka
是分布式发布-订阅消息系统,kafka对消息保存时根据Topic进行归类,每个topic将被分成多个partition(区),每条消息在文件中的位置称为offset(偏移量),offset为一个long型数字,它是唯一标记一条消息,它唯一的标记一条消息。
一个partition中的消息只会被group中的一个consumer消费,每个group中consumer消息消费互相独立,不过一个consumer可以消费多个partitions中的消息。
kafka只能保证一个partition中的消息被某个consumer消费时,消息是顺序的。从Topic角度来说,消息仍不是有序的。
每个partition都有一个server为"leader";leader负责所有的读写操作,如果leader失效,那么将会有其他follower来接管成为新的leader(有zookeeper选举);follower只是单调的和leader跟进,同步消息即可..由此可见作为leader的server承载了全部的请求压力,因此从集群的整体考虑,有多少个partitions就意味着有多少个"leader",kafka会将"leader"均衡的分散在每个实例上,来确保整体的性能稳定.
使用3台服务器搭建集群
Server1:192.168.89.11
Server2:192.168.89.12
Server3:192.168.89.13
(jdk1.8.0_102)
# yum install -y java-1.8.0-openjdk java-1.8.0-openjdk-devel
Zookeeper集群的工作是超过半数才能对外提供服务,所以选择主机数可以是1台、3台、5台…。
3台中允许1台挂掉 ,是否可以用偶数,其实没必要。
如果有4台,那么挂掉一台还剩下三台服务器,如果再挂掉一个就不行了,记住是超过半数。
http://mirrors.shu.edu.cn/apache/zookeeper/zookeeper-3.4.13/zookeeper-3.4.13.tar.gz
1)创建zookeeper安装目录
# mkdir -p /data/zookeeper
2)将zookeeper解压到安装目录
# tar -zxvf zookeeper-3.4.13.tar.gz -C /data/zookeeper/
3)新建保存数据的目录
# mkdir -p /data/zookeeper/zookeeper-3.4.13/data
4)新建日志目录
# mkdir -p /data/zookeeper/zookeeper-3.4.13/dataLog
5)配置环境变量并刷新
# vim /etc/profile
===================================================
export ZK_HOME=/data/zookeeper/zookeeper-3.4.13
export PATH=$PATH:$ZK_HOME/bin
===================================================
# source /etc/profile
# cd /data/zookeeper/zookeeper-3.4.13/conf/
# cp -f zoo_sample.cfg zoo.cfg
# vim zoo.cfg
====================================================
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zookeeper/zookeeper-3.4.13/data/
dataLogDir=/data/zookeeper/zookeeper-3.4.13/dataLog/
clientPort=2181
server.1=192.168.89.11:2888:3888
server.2=192.168.89.12:2888:3888
server.3=192.168.89.13:2888:3888
#第一个端口是master和slave之间的通信端口,默认是2888,第二个端口是leader选举的端口,集群刚启动的时候选举或者leader挂掉之后进行新的选举的端口默认是3888
====================================================
# echo "1" > /data/zookeeper/zookeeper-3.4.13/data/myid #server1配置,各节点不同,跟上面配置server.1的号码一样
# echo "2" > /data/zookeeper/zookeeper-3.4.13/data/myid #server2配置,各节点不同,跟上面配置server.2的号码一样
# echo "3" > /data/zookeeper/zookeeper-3.4.13/data/myid #server3配置,各节点不同,跟上面配置server.3的号码一样
1)启动停止zookeeper命令
# zkServer.sh start #启动
# zkServer.sh stop #停止
# zkCli.sh #连接集群
2)设置开机启动
# cd /usr/lib/systemd/system
# vim zookeeper.service
=========================================
[Unit]
Description=zookeeper server daemon
After=zookeeper.target
[Service]
Type=forking
ExecStart=/data/zookeeper/zookeeper-3.4.13/bin/zkServer.sh start
ExecReload=/data/zookeeper/zookeeper-3.4.13/bin/zkServer.sh stop && sleep 2 && /data/zookeeper/zookeeper-3.4.13/bin/zkServer.sh start
ExecStop=/data/zookeeper/zookeeper-3.4.13/bin/zkServer.sh stop
Restart=always
[Install]
WantedBy=multi-user.target
=======================================================
# systemctl start zookeeper
# systemctl enable zookeeper
http://mirror.bit.edu.cn/apache/kafka/2.1.0/kafka_2.12-2.1.0.tgz
1) 新建kafka工作目录
# mkdir -p /data/kafka
2) 解压kafka
# tar -zxvf kafka_2.12-2.1.0.tgz -C /data/kafka/
3) 新建kafka日志目录
# mkdir -p /data/kafka/kafkalogs
4) 配置kafka配置文件
# vim /data/kafka/kafka_2.12-2.1.0/config/server.properties
=================================================
broker.id=1 #每一个broker在集群中的唯一标示,要求是正数
listeners=PLAINTEXT://192.168.89.11:9092 # 套接字服务器连接的地址
log.dirs=/data/kafka/kafkalogs/ #kafka数据的存放地址
message.max.byte=5242880 #消息体的最大大小,单位是字节
log.cleaner.enable=true #开启日志清理
log.retention.hours=72 #segment文件保留的最长时间(小时),超时将被删除,也就是说3天之前的数据将被清理掉
log.segment.bytes=1073741824 #日志文件中每个segmeng的大小(字节),默认为1G
log.retention.check.interval.ms=300000 #定期检查segment文件有没有达到1G(单位毫秒)
num.partitions=3 #每个topic的分区个数, 更多的分区允许更大的并行操作default.replication.factor=3 # 一个topic ,默认分区的replication个数 ,不得大于集群中broker的个数
delete.topic.enable=true # 选择启用删除主题功能,默认false
replica.fetch.max.bytes=5242880 # replicas每次获取数据的最大大小
#以下三个参数设置影响消费者消费分区可以连接的kafka主机,详细请看第6点附录
offsets.topic.replication.factor=3 #Offsets topic的复制因子(备份数)
transaction.state.log.replication.factor=3 #事务主题的复制因子(设置更高以确保可用性)
transaction.state.log.min.isr=3 #覆盖事务主题的min.insync.replicas配置
zookeeper.connect=192.168.89.11:2181,192.168.89.12:2181,192.168.89.13:2181
#zookeeper集群的地址,可以是多个
=================================================
5) kafka节点默认需要的内存为1G,如果需要修改内存,可以修改kafka-server-start.sh的配置项
# vim /data/kafka/kafka_2.12-2.1.0/bin/kafka-server-start.sh
#找到KAFKA_HEAP_OPTS配置项,例如修改如下:
export KAFKA_HEAP_OPTS="-Xmx2G -Xms2G"
1)启动kafka
# cd /data/kafka/kafka_2.12-2.1.0/
./bin/kafka-server-start.sh -daemon ./config/server.properties
启动后可以执行jps命令查看kafka是否启动,如果启动失败,可以进入logs目录,查看kafkaServer.out日志记录。
2)设置开机启动
# cd /usr/lib/systemd/system
# vim kafka.service
=========================================
[Unit]
Description=kafka server daemon
After=kafka.target
[Service]
Type=forking
ExecStart=/data/kafka/kafka_2.12-2.1.0/bin/kafka-server-start.sh -daemon /data/kafka/kafka_2.12-2.1.0/config/server.properties
ExecReload=/data/kafka/kafka_2.12-2.1.0/bin/kafka-server-stop.sh && sleep 2 && /data/kafka/kafka_2.12-2.1.0/bin/kafka-server-start.sh -daemon /
data/kafka/kafka_2.12-2.1.0/config/server.properties
ExecStop=/data/kafka/kafka_2.12-2.1.0/bin/kafka-server-stop.sh
Restart=always
[Install]
WantedBy=multi-user.target
=======================================================
# systemctl start kafka
# systemctl enable kafka
创建3分区、3备份
# cd /data/kafka/kafka_2.12-2.1.0/
#./bin/kafka-topics.sh --create --zookeeper 192.168.89.11:2181,192.168.89.12:2181,192.168.89.13:2181 --replication-factor 3 --partitions 3 --topic SyslogTopic
# cd /data/kafka/kafka_2.12-2.1.0/
1) 停止kafka
./bin/kafka-server-stop.sh
2) 创建topic
./bin/kafka-topics.sh --create --zookeeper 192.168.89.11:2181,192.168.89.12:2181,192.168.89.13:2181 --replication-factor 1 --partitions 1 --topic topic_name
3) 展示topic
./bin/kafka-topics.sh --list --zookeeper 192.168.89.11:2181,192.168.89.12:2181,192.168.89.13:2181
4) 查看描述topic
./bin/kafka-topics.sh --describe --zookeeper 192.168.89.11:2181,192.168.89.12:2181,192.168.89.13:2181 --topic topic_name
5) 生产者发送消息
./bin/kafka-console-producer.sh --broker-list 192.168.89.11:9092 --topic topic_name
6) 消费者消费消息
./bin/kafka-console-consumer.sh --bootstrap-server 192.168.89.11:9092,192.168.89.12:9092,192.168.89.13:9092 --topic topic_name
7) 删除topic
./bin/kafka-topics.sh --delete --topictopic_name --zookeeper 192.168.89.11:2181,192.168.89.12:2181,192.168.89.13:2181
8) 查看每分区consumer_offsets(可以连接到的消费主机)
./bin/kafka-topics.sh --describe --zookeeper 192.168.89.11:2181,192.168.89.12:2181,192.168.89.13:2181 --topic __consumer_offsets
1、 消费者消费分区数据,kafka的负载均衡
在/data/kafka/kafka_2.12-2.1.0/config/server.properties文件中修改offsets.topic.replication.factor,这个值为kafka集群的主机数量(__consumer_offest不受server.properties中num.partitions和default.replication.factor参数的制约。相反地,它的分区数和备份因子分别由offsets.topic.num.partitions和offsets.topic.replication.factor参数决定。这两个参数的默认值分别是50和1,表示该topic有50个分区,副本因子是1。),设置正确如下图:
(执行命令:bin/kafka-topics.sh --describe --zookeeper 192.168.89.11:2181,192.168.89.12:2181,192.168.89.13:2181 --topic __consumer_offsets)
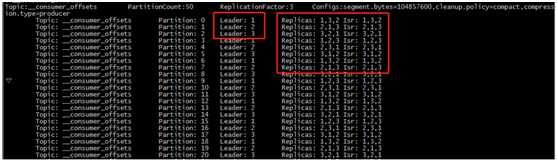
注:如果配置文件offsets.topic.replication.factor设置成1后启动了一次,再设置成3重新启动副本因子不会更改,需要以下方法:
另外一种方法设置:
1) 创建规则json
cat > increase-replication-factor.json <<EOF
{"version":1, "partitions":[
{"topic":"__consumer_offsets","partition":0,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":1,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":2,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":3,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":4,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":5,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":6,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":7,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":8,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":9,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":10,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":11,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":12,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":13,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":14,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":15,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":16,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":17,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":18,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":19,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":20,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":21,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":22,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":23,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":24,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":25,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":26,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":27,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":28,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":29,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":30,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":31,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":32,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":33,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":34,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":35,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":36,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":37,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":38,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":39,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":40,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":41,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":42,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":43,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":44,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":45,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":46,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":47,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":48,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":49,"replicas":[1,2,3]}]
}
EOF
2) 执行
bin/kafka-reassign-partitions.sh --zookeeper 192.168.89.11:2181,192.168.89.12:2181,192.168.89.13:2181 --reassignment-json-file increase-replication-factor.json --execute
3) 验证
bin/kafka-reassign-partitions.sh --zookeeper 192.168.89.11:2181,192.168.89.12:2181,192.168.89.13:2181 --reassignment-json-file increase-replication-factor.json --verify
标签:heap centos 最大 ima file syn home 3.2 tick
原文地址:https://www.cnblogs.com/longBlogs/p/10340251.html