标签:文件的 存在 bsp 如何 事件 资源 log heartbeat yarn
先从网上copy一些优势点
1、高容错性
数据自动保存多个副本。它通过增加副本的形式,提高容错性。
某一个副本丢失以后,它可以自动恢复,这是由 HDFS 内部机制实现的,我们不必关心。
2、适合批处理
它是通过移动计算而不是移动数据。
它会把数据位置暴露给计算框架。
3、适合大数据处理
处理数据达到 GB、TB、甚至PB级别的数据。
能够处理百万规模以上的文件数量,数量相当之大。
能够处理10K节点的规模。
4、流式文件访问
一次写入,多次读取。文件一旦写入不能修改,只能追加。
它能保证数据的一致性。
5、可构建在廉价机器上
它通过多副本机制,提高可靠性。
它提供了容错和恢复机制。比如某一个副本丢失,可以通过其它副本来恢复。
当然 HDFS 也有它的劣势,并不适合所有的场合:
1、低延时数据访问
比如毫秒级的来存储数据,这是不行的,它做不到。
它适合高吞吐率的场景,就是在某一时间内写入大量的数据。但是它在低延时的情况下是不行的,比如毫秒级以内读取数据,这样它是很难做到的。
2、小文件存储
存储大量小文件(这里的小文件是指小于HDFS系统的Block大小的文件(默认64M))的话,它会占用 NameNode大量的内存来存储文件、目录和块信息。这样是不可取的,因为NameNode的内存总是有限的。
小文件存储的寻道时间会超过读取时间,它违反了HDFS的设计目标。
3、并发写入、文件随机修改
一个文件只能有一个写,不允许多个线程同时写。
仅支持数据 append(追加),不支持文件的随机修改。
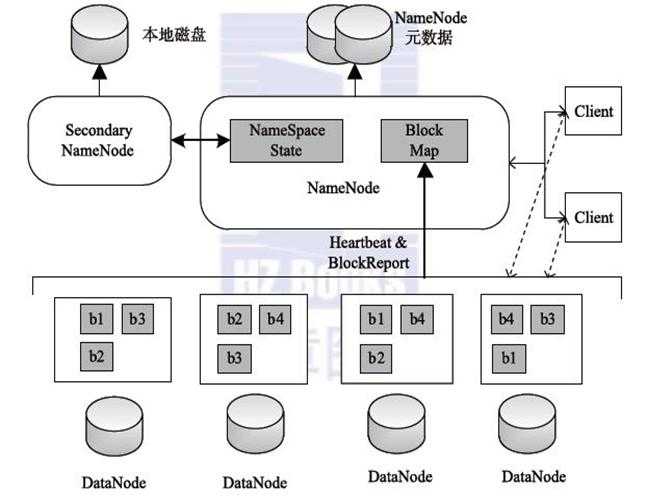
HDFS 架构图
hadoop 2.X 新特性
JournalNode的作用 (简单理解为一个集群namenode数据修改了,会向集群里面写数据,standbynamenode 会去读取这个集群里面的数据实现同步)
两个NameNode为了数据同步,会通过一组称作JournalNodes的独立进程进行相互通信。当active状态的NameNode的命名空间有任何修改时,会告知大部分的JournalNodes进程。standby状态的NameNode有能力读取JNs中的变更信息,并且一直监控edit log的变化,把变化应用于自己的命名空间。standby可以确保在集群出错时,命名空间状态已经完全同步了
DFSZKFailoverController作用 (简单理解为namenode失败切换选举namenode)
从HealthMonitor和ActiveStandbyElector中订阅事件并管理NN的状态,另外ZKFC还需要负责fencing。
fencing
当standby节点通过zookeeper集群检测到active节点已经宕机,它并不会立马切换到active状态,hadoop提供了fencing机制,它首先会通过ssh发送一条指令,将NameNode的进程杀死,并等待返回结果。当确认进程已经被杀死之后才会进行状态切换。但是由于网络问题,如何保证ssh命令一定能够发送成功,或者执行后的返回结果一定能够收到呢?如果收不到正确响应就永远无法切换成active状态了。hadoop提供了这样的解决方案,可以定义一个超时时间,当ssh命令发送出去后,超过超时时间后还没有收到正常返回值,zkfc进程可以执行一个自定义的shell脚本程序,进行节点的处理,去保证已经宕机的active节点不会重新切换成active状态
ResourceManager
ResourceManager 负责整个集群的资源管理和分配,是一个全局的资源管理系统。
QuorumPeerMain
zookeeper的进程
标签:文件的 存在 bsp 如何 事件 资源 log heartbeat yarn
原文地址:https://www.cnblogs.com/ZFBG/p/10341238.html