标签:技术分享 主题 现在 高效 自己 关系数据库 section 数据库 读写
具有三个关键能力的流处理平台:
Kafka通常有两大类应用:
为了理解kafka是如何实现这些功能的,让我们深入了解并从头开始探索kafka的功能。
首先是几个概念:
kafka有四个核心API:
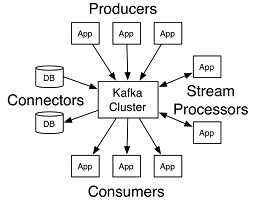
在Kafka中,客户端和服务器之间的通信是通过一个简单的、高性能的、与语言无关的TCP协议完成的。TCP协议受版本控制,并与旧版本保持向后兼容性。我们为Kafka提供了一个Java客户端,但是客户端可以使用多种语言。
让我们首先深入了解Kafka提供的记录流的核心抽象概念——主题(topic)
主题是发布记录的类别或概要名称。Kafka中的主题通常是多订阅的;也就是说,一个主题可以有0个、1个或多个消费者订阅写入主题的数据。
对于每个主题,Kafka集群都维护一个如下所示的分区日志:
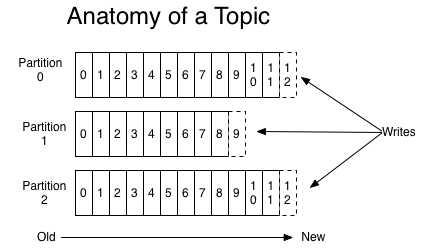
每个分区都是一个有序的、不可变的记录序列,记录被不断的添加到分区中。分区中的记录都被分配了一个有序的id号,叫做偏移,作为每个记录在分区中的唯一标示。
在一个可配置的时间内,kafka能够保留所有已发布的记录,无论记录是否被消费。例如,如果保留策略设置为2天,那么在发布记录后的2天内,记录是可以被消费的,之后记录将被丢弃来释放空间。Kafka的性能对于数据量来说是恒定的,因此长时间存储数据不是问题。
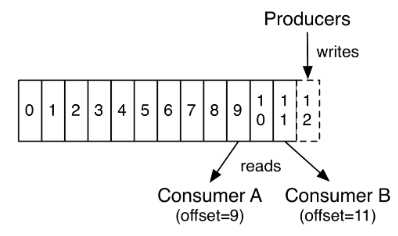
事实上,保留在每个消费者的基础上的唯一的元数据是消费者在日志中偏移或位置。偏移量由消费者控制:通常,消费者在读取记录时偏移量将线性增大;但实际上,由于位置是由消费者控制的,所以它可以按自己喜欢的任何顺序来消费记录。例如,使用者可以重置到旧的偏移量来重新处理过去的数据,或者跳到最近的记录并从“现在”开始消费。
这些特性的组合意味着Kafka的消费者非常轻量的,他们可以再对集群或其他消费者不造成太大影响下消费数据。例如,可以使用kafka的命令行工具“跟踪”任何主题的内容,而不更改任何现有消费者使用的内容。
日志中的分区有几个用途。首先,它们允许日志扩展到超出单个服务器的大小。每个单独的分区必须适合承载它的服务器,但是一个主题可以有多个分区,一个主题可以处理任意数量的数据。其次,它们作为平行的单元——关于这点,稍后会详细介绍。
日志的分区分布在Kafka集群中的服务器上,这样每个服务器都能够处理分区共享的数据和请求。为了容错,每个分区在任意数量的服务器之间复制。
每个分区都有一个服务器充当leader,其余服务器充当follower。leader处理分区的所有读写请求,而follower则被动地复制leader。如果leader down了,其中一个follower将自动成为新的领导者。每个服务器作为它的一些分区的leader和其他分区的追随者,因此负载在集群中得到很好的平衡。
kafka的映射机制为集群提供跨域复制的能力。基于映射机制,消息被复制到多个数据中心或云。可以用于各种场景的备份和恢复、或各种场景下将数据布置在离用户更近的地方、或者支撑局部的数据需求。
Producers 将消息发布到指定的topic中,并决定分配到主题中的哪个分区。可以通过循环的方式简单的实现负载平衡,或者可以根据某种特定的分区函数来实现(比如根据记录中的某个键)。
每个消费者都会打上消费者组的标签,发布到主题的每个记录被分配给到每个订阅消费者组中的一个消费者实例。消费者实例可以位于单独的进程中,也可以位于单独的机器上。
如果所有消费者实例具有相同的使用者组标签,则消息将有效地平均加载到使用者实例。
如果所有消费者实例具有不同的使用者组标签,则每个消息将广播到所有消费者进程。
标签:技术分享 主题 现在 高效 自己 关系数据库 section 数据库 读写
原文地址:https://www.cnblogs.com/gidybzc/p/10242006.html