标签:架构 需求 特定 系统 sch scheduler 插入 requests 大致
在具体的学习scrapy之前,我们先对scrapy的架构做一个简单的了解,之后所有的内容都是基于此架构实现的,在初学阶段只需要简单的了解即可,之后的学习中,你会对此架构有更深的理解。
下面是scrapy官网给出的最新的架构图示。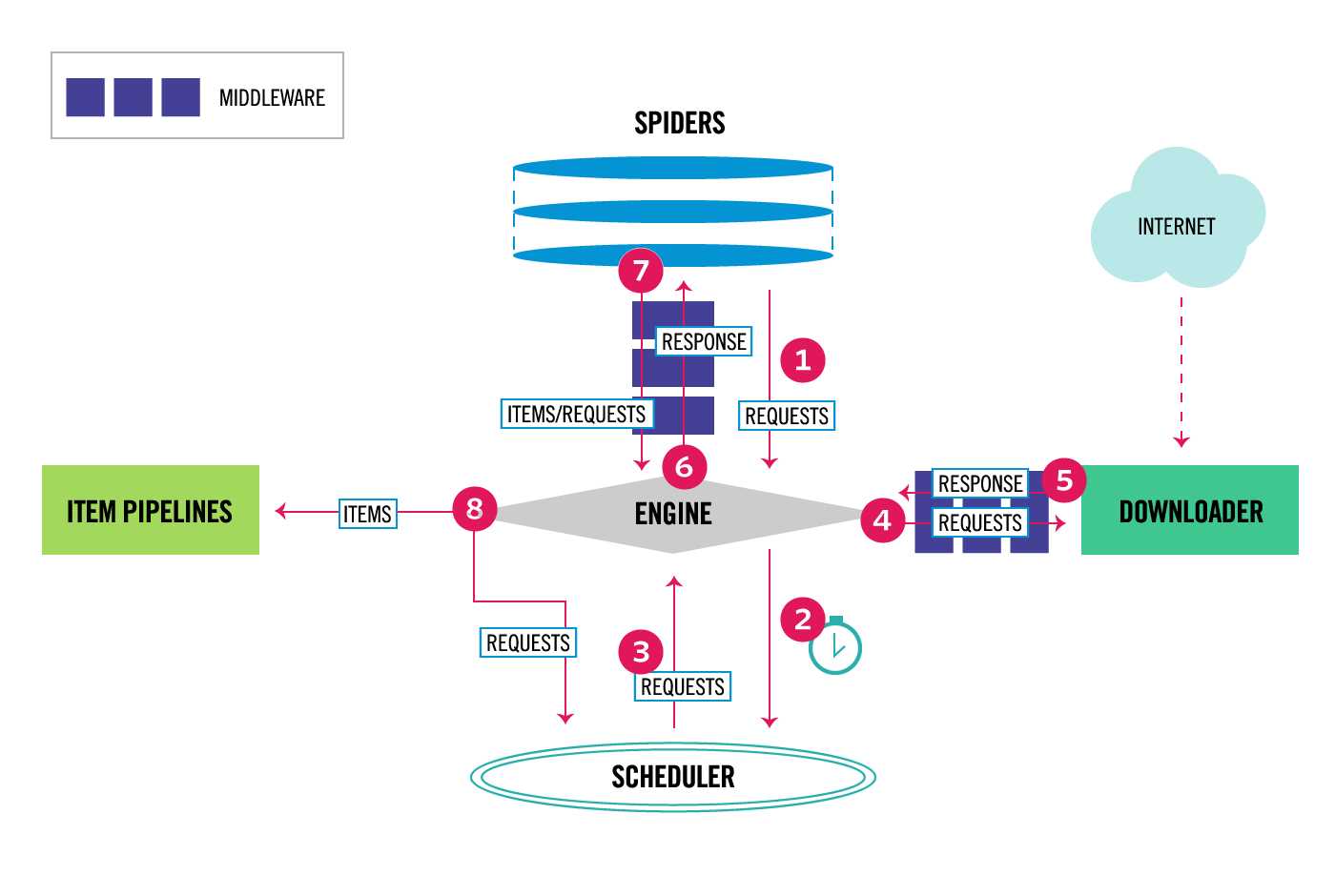
Scrapy的数据流由执行引擎(Engine)控制,其基本过程如下:
Scrapy的各个组件相互配合执行,有的组件负责任务的调度,有的组件负责任务的下载,有的组件负责数据的清洗保存,各组件分工明确。在组件之间存在middleware的中间件,其作用就是功能的拓展,当然还可以根据自身的需求自定义这些拓展功能,比如我们可以在Downloader middlewares里面实现User-Agent的切换,Proxy的切换等等。这些功能我们会在后续的学习中逐渐拓展。这里只需要大致的了解即可。
标签:架构 需求 特定 系统 sch scheduler 插入 requests 大致
原文地址:https://www.cnblogs.com/lxbmaomao/p/10345559.html