标签:stack -- factor splay oid overview existing special F12
This week a customer called and asked (translated into my own words and shortened):
“We do composite services, orchestrating two or three CRUD-Services to do something more useful. Our architects want to use your workflow engine for this because the orchestration flow might be long running. Is this a valid scenario for workflow? Currently we run one big central cluster for the workflow engine?—?won’t this get a mess?”
These are valid questions which recently we get asked a lot, especially in the context of microservices, modern SOA initiatives or domain-driven design.
Modern workflow engines are incredibly flexible. In this blog post I will look at possible architectures using them. To illustrate these architecture I use the open source products my company provides(Camunda and Zeebe.io) as I know them best and saw them “in the wild“ at hundreds if not thousands of companies. But these thoughts are applicable to comparable tools on the market as well.
For over a decade, workflow engines (or BPM tools) were positioned as being something central. Very often this was the only way of running complex beasts that required challenging setups. Most vendors even cemented this approach into their licensing model which meant, not only was it horribly expensive but also tied to CPU cores.

This is not true any more with modern tools which are very flexible.
In Avoiding the “BPM monolith” when using bounded contexts I show that in an architecture which cleanly separated responsibilities you should run multiple engines. And all modern trends like DDD or Microservices call for de-central components to allow more agility and autonomy which is about getting changes into production as fast as possible which will be the key capabilities of successful enterprises in future.
So in the above scenario I would run an own workflow engine for every service that needs long running behavior.

Advantages:
But of course there are also drawbacks:
To get a proper overview our customers typically setup monitoring solutions collecting events from all engines. The central monitoring doesn’t show too many details but provides links to the right operating tool. You could e.g. use the Elastic stack for this. And simple workflow engine plugins can generically push events within a workflow to the central tool. This is comparable to what Camunda Optimize does, it collects data from many engines and makes them available for central analyzing (but with the goal of business analysis and improvement, not technical operations).

However, there is one interesting hybrid possible, at least in the Camunda world: Running multiple engines on top of a shared database.

This is actually what a reasonable amount of customers do and it’s not only a valid approach but often a good compromise, especially because Camunda has two features supporting it:
Some customers see the workflow engine as an infrastructure component, living on its own and not being part of a specific service.

This is very much the view of a BPM or ESB-like component of the first wave of SOA projects, it is a central engine as described above. We see a lot of customers in this scenario use workflows as rather small integration flows, replacing an ESB. This is technically feasible but it poses questions around the ownership and life-cycle of the workflow models. I dedicate a section especially to this very important aspect. It is a valid approach if you sort out these questions even if a lot of customers turn away from this view because of bad experiences back in the old SOA days.
Orchestrating serverless functions
A very related use case in modern architectures is the orchestration of stateless and rather small functions. Using these functions (e.g. Azure Functions, AWS Lambda or similar) you need a way to implement end-to-end business capabilities which often stretch across multiple functions. This is a perfect fit for a workflow engine. I published details of a recent customer project in the Azure Cloud in Orchestrating Azure Functions using BPMN and Camunda?—?a case study, this is how the high-level architecture looks like:

Every workflow model needs a clear owner which can decide not only for changes, but is also responsible that the workflow runs smoothly. In Microservices architectures (or similar) this ownership is typically given to teams building the service. In this scenario ownership for services is baked into the organization already. This makes it quite natural to make workflow models part of the service. If you have workflow models as own artifacts?—?as e.g. in the serverless example above?—?it is a bit harder but not less important to define a proper ownership.
Additionally you have to clarify for every workflow model when and how it gets deployed. Very often workflow models have a strong relationship to a certain domain meaning that you have to deploy them in-sync with the corresponding service (or function). This is easier to do if they are logically part of the service. If it’s a separated artifact with a separated owner it means you have to coordinate between teams which slows you down. And if it’s not really separated, why it’s not part of your service?
Once again there is not only a black and white approach. A hybrid solution is to run a centralized engine but to distribute ownership and responsibility for deployment of the workflow models to the services.

This is a common scenario for non-Java environments using Camunda. It mitigates the biggest problems arising from a central engine or seeing workflow engines as infrastructure. It is a valid approach. If you are developing Java services, it might be a bigger overhead than running the engine within your service itself. But to understand this let’s turn our attention on how to run a workflow engine at all.
Typically a workflow engine runs as a separate application allowing you to connect remotely, e.g. via REST in Camunda or Message Pack in Zeebe. This allows you to run the engine on a different host but of course it can also run just beside the service itself.
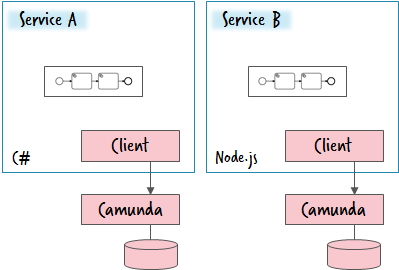
A code example can be found here: Use Camunda without touching Java and get an easy-to-use REST-based orchestration and workflow engine.
Forces:
By the way, remote communication doesn’t have to feel bad for the developer. For example, Zeebe provides native client libraries (currently for Java and GoLang but more support is planned) which allow to use it like an embedded engine in terms of coding but keep the separation of concerns.
Camunda is an example of an embeddable Java engine. That means the engine can also run as part of your Java application. In this case you can simply communicate with the engine by Java API and the engine can call Java code whenever it needs to transform data or call services. The following code snippet will work in any Java program and defines a workflow model, deploys it and starts instances (it is really that simple to get started!). You just need Camunda and a H2 database on the classpath:
This scenario is the de-facto standard for JUnit tests. I am very proud of the Camunda test support (also providing assertions, scenario tests and visualizations of test runs).
Spring Boot Starter
But running an embedded engine is also what you do if you use the Camunda Spring Boot Starter which is a nice way of implementing the one workflow engine per service approach described above.

A Camunda Spring Boot code example can be found here: https://github.com/berndruecker/camunda-spring-boot-amqp-microservice-cloud-example/
Container-managed engine
Within Camunda we provide something unique: A container-managed engine running as part of Tomcat or application servers like WildFly or WebSphere. Having this available, you can deploy normal WAR artifacts which can contain workflow models which are automatically deployed to the container-managed engine. This allows for a clean distinction between infrastructure (container) and domain logic (WAR).

A code example can be found here: https://github.com/camunda-consulting/camunda-showcase-insurance-application.
In the past, it was often advocated to deploy multiple applications (WAR files) onto a single app server. We also support this model in Camunda. However, we do not see this being applied often any more as it breaks isolation between deployments. If one application goes nuts it can very well affect other applications on this server. And with technologies like Docker it’s super easy to run multiple app servers instead so I also favor the one app per application server approach.
Spring Boot or container-managed engine?
Deciding between Spring Boot or an application server is hard as it‘s still a very religious decision. Conceptually I like separating the infrastructure into an application server. And if you are running Docker, the WildFly approach might even allow for faster turnaround times (see below). But it’s also true that the environment around Spring Boot is quite active, pragmatic, stable, innovative and often ahead of Java EE (sorry, EE4J of course). My advice would be to base your decision on what works best in your company, either way will be fine. Keep your team and the target runtime environment in mind when doing this selection.
In general, we do not recommend running an embedded Camunda engine and configuring it on your own (e.g. via plain Java or Spring). There are some things you have to do right (e.g. thread pooling, transactions, id generation) especially to guarantee proper behavior under load. So better use the Spring Boot Starter or the container-managed engine.
Pros and cons of the embeddable engine approach
Running the engine in the previously mentioned ways is optimal in a Java world as it provides many advantages including:
But of course it has a major drawback:
Our current rule of thumb for Camunda customers is:
For Camunda there is a funny recursion: When running the workflow engine as a separate application, the Camunda engine itself has to be started up using one of the options already stated above (e.g. container-managed or using Spring Boot). The typical way is to run a container-managed engine on Tomcat, maybe using Docker.
Assume you have a payment workflow that needs to communicate with a remote service to charge a credit card:

There are two basic patterns to implement this communication:


Pulling work has a couple of advantages:
Of course it has drawbacks:
We regularly have customers which want to have true temporal decoupling in a way that service unavailability doesn’t cascade. They don’t want to do synchronous calls which needs to be retried when a service is unavailable. But a lot of them shy away from introducing messaging systems as they are an additional component in the stack which are hard to operate. As an alternative they often use the pull model to implement asynchronism and temporal decoupling. This works very well.
Overall we cannot give a general recommendation for the best communication style. It depends on too many factors. If you’re in doubt, we recently tend to favor the pull approach. But in the Java space most customers use the push approach as it is quite natural and simple to setup?—?and works very well for most use cases.
Embedded engines are part of your Java application and can basically run everywhere. Spring Boot packages a so-called uber-jar containing all dependencies. Some people also call this fat-jar as it typically grows around the same size as containers because it contains all dependencies they need (including the webserver, transaction manager, etc). Either way, you can run it on Docker, in Java build packs from CloudFoundry or Heroku or any other environment you like. A code example for Spring Boot and Cloud Foundry can be found here: https://github.com/berndruecker/camunda-spring-boot-amqp-microservice-cloud-example/
With app servers like Tomcat or WildFly you will typically run Docker nowadays. There is one interesting thought on this: Docker works in layers, and new docker images just add new layers on top of existing ones.

So you could define a base image for workflow applications and then just add WAR files to this. The WAR files are typically tiny (some kilobytes) allowing for very quick turnaround. Whether this advantage affects you depends on the development workflow in your company.
There are Docker images available of Camunda and Zeebe and we provide several examples on how to build custom Docker images. These Docker images can run in basically all cloud environments providing container services.
Gee, that was a long blog post. Sorry. I couldn’t stop writing. But I know that this is relevant information for a lot of people who are going to introduce workflow engines in their architecture?—?or to fix bad decisions from the past.
Modern tools allow for greater flexibility. And this flexibility comes with the burden that you have to make decisions. This post lists the most important aspects to consider and should help you make a well informed decision. Feel free to approach me or the Camunda team if you need help in this endeavor. It is really important to think this through as some basic decisions have a huge impact on your architectures future.
For everybody who thinks: “I have no clue what this guy is writing about, I just want to get going” we defined a so-called greenfield stack in the Camunda Best Practices (which are reserved for our Enterprise Customers, sorry!). It is not superior to any other stack, it is just the one we recommend if you don’t care. And because you read this till the end, you get it free as a bonus ;-)
We suggest as runtime environment:
For development:
As runtime environment on the local developer machine we recommend:
We strongly discourage that multiple developers share the same database during development as this can lead to a multitude of problems.
Architecture options to run a workflow engine
标签:stack -- factor splay oid overview existing special F12
原文地址:https://www.cnblogs.com/rongfengliang/p/10347106.html