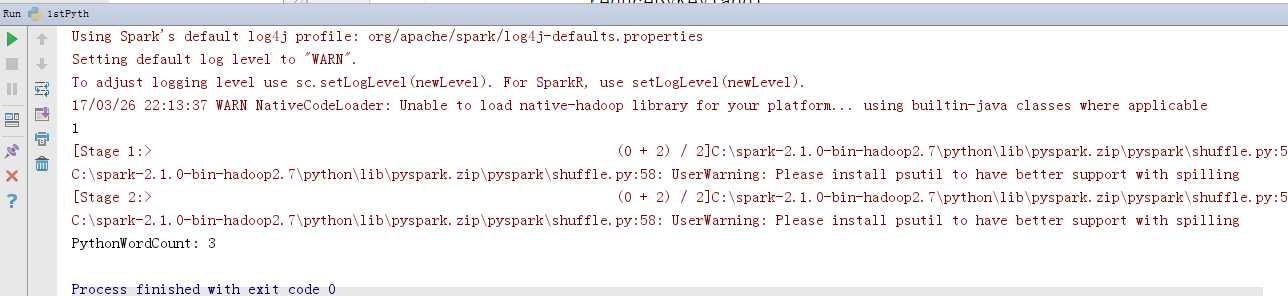
AS WE ALL KNOW,学机器学习的一般都是从python+sklearn开始学,适用于数据量不大的场景(这里就别计较“不大”具体指标是啥了,哈哈)
数据量大了,就需要用到其他技术了,如:spark, tensorflow,当然也有其他技术,此处略过一坨字...
先来看看如何让这3个集成起来吧(WINDOWS环境):pycharm(python开发环境), pyspark.cmd(REPL命令行接口), spark(spark驱动、MASTER等)
download Anaconda, latest version, which 64bit support for windows, 这里必须安装64位版本的Anaconda,因为后面tensorflow只支持64位的
https://www.continuum.io/downloads/
安装Anaconda,都是默认选项就行
dowload pycharm from jetbrain site, and install (please do it by yourself),这个很简单,直接略过
接下来是下载spark,我下的是最新版2.1.0的 http://spark.apache.org/downloads.html
解压缩后把它复制到一个容易找的目录,我这是C:\spark-2.1.0-bin-hadoop2.7
这个时候如果直接双击bin下的spark-shell.cmd文件的话是会报错的,主要原因是没有winutils.exe这东西(用来在windows环境下模拟文件操作的),因此还需要做几个小步骤才能正常启动
1. 设置一个假的hadoop目录,在这个目录的bin下放刚才说的那个winutils.exe文件(需要自己创建bin目录)
2. 设置环境变量HADOOP_HOME,值为这个假的hadoop目录
3. 拷贝winutils.exe到这个bin里,下载
OK,这时可以双击spark-shell.cmd了,如下:
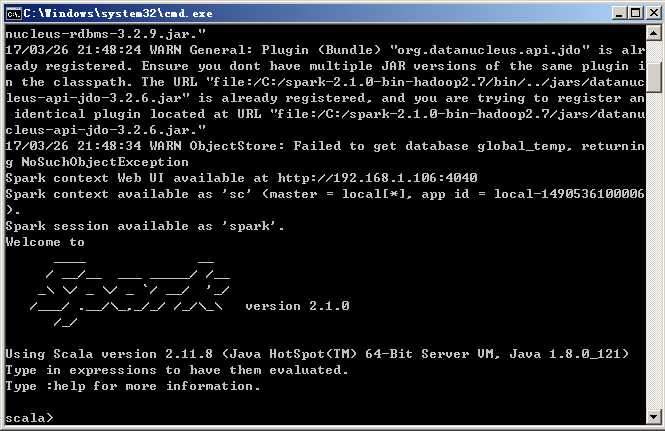
HOHO, ==,==,我们不是要搞PYTHON环境嘛,怎么搞scala了,别急,先搞scala是因为先要把基本的给走通,再去搞python环境的接口。
python接口的REPL是这个文件,pyspark.cmd,双击,也报错...
别急,这里是因为python版本问题,anaconda最新版的python解释器版本是3.6.1,这个版本的spark不支持,需要降低版本 到3.5
卸载python? 不用,用anaconda的环境切换就行了
1. 先创建一个新的开发环境: conda create -n my_new_env_python35
2. 激活这个新的开发环境: activate my_new_env_python35
3. 在这个新的开发环境中安装python 3.5: conda install python=3.5
这时python3.5版本的解释器就算是安装完成了,默认目录在C:\ProgramData\Anaconda3\envs\my_new_env_python35\python.exe
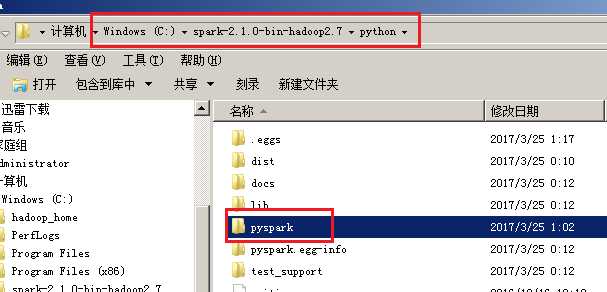
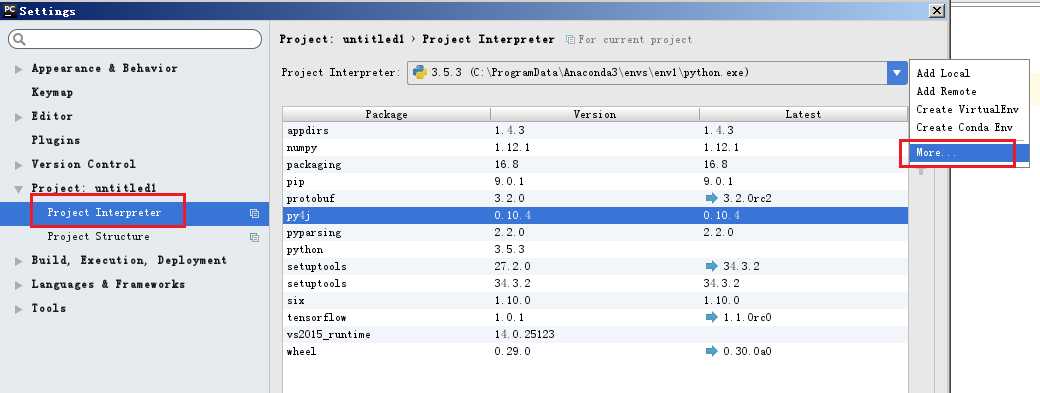
然后就是需要把spark的python支持包复制到相应的路径中了,从下图1复制到my_new_env_python35环境的Lib\site-packages目录下
接下来需要把python默认版本改成python3.5,需要修改PATH路径,把python3.5的路径放在第一个查找路径下就行了
然后就开始整pycharm开发环境了。
首先肯定是新建一个python项目了,然后改设置,用来指定python解释器的路径,菜单:File-->Settings
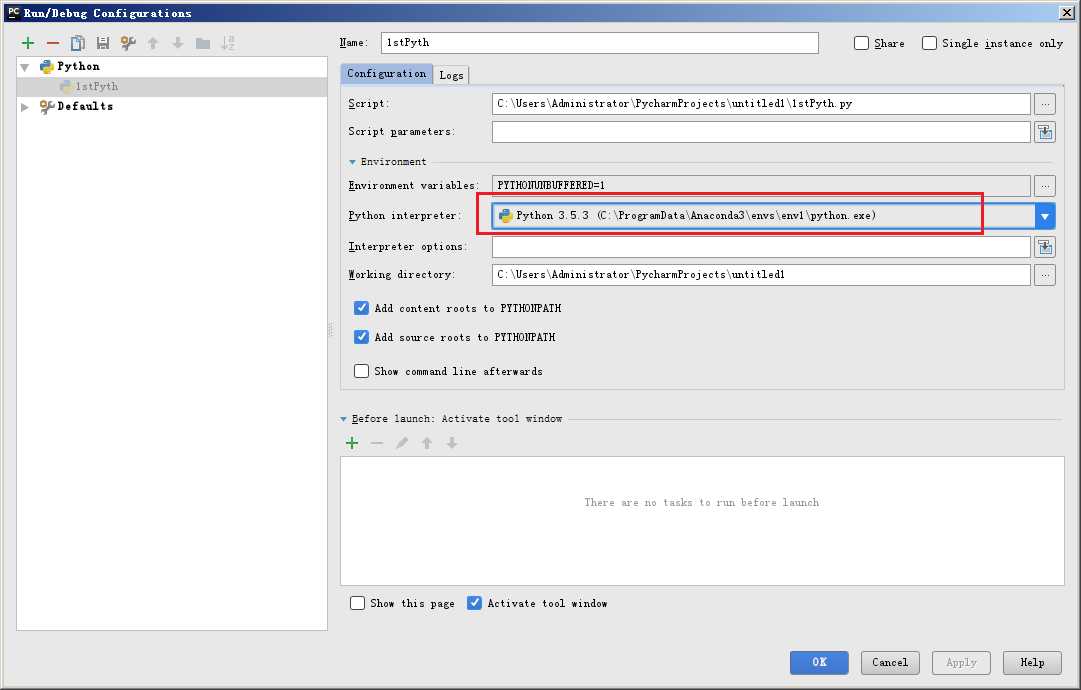
接着设置运行时候的配置参数
漏了python调用pyspark的代码了,代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
import sysfrom operator import addfrom pyspark import SparkContextif __name__ == "__main__": sc = SparkContext(appName="PythonWordCount") lines = sc.textFile(‘words.txt‘) count=lines.count() print(count) counts = lines.flatMap(lambda x: x.split(‘ ‘)) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) output = counts.collect() for (word, count) in output: print("%s: %i" % (word, count)) sc.stop() |
至此,python环境算是搞定了。