标签:image isp hold 叠加 mat for 结果 target img
通常我们使用的最小二乘都需要预先设定一个模型,然后通过最小二乘方法解出模型的系数。
而大多数情况是我们是不知道这个模型的,比如这篇博客中z=ax^2+by^2+cxy+dx+ey+f 这样的模型。
局部加权线性最小二乘就不需要我们预先知道待求解的模型,因为该方法是基于多个线性函数的叠加,最终只用到了线性模型。
计算线性模型时引入了一个加权函数:
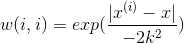 来给当前预测数据分配权重,分配机制是:给距离近的点更高的权重,给距离远的点更低的权重。
来给当前预测数据分配权重,分配机制是:给距离近的点更高的权重,给距离远的点更低的权重。
公式中的k类似与高斯函数中的sigma。
当sigma变大时,函数变得矮胖,计算局部线性函数时更多的使用全局数据;
当sigma变小时,函数变得瘦高,计算局部线性函数时更多的使用局部数据。
代码如下:
clear all; close all; clc; x=(1:0.1:10)‘; y=x.^2+x+3 +rand(length(x),1)*6; plot(x,y,‘.‘) sigma=0.1; %设置局部窗口,越大越使用全局数据,越小越使用局部数据 W=zeros(length(x)); C=[]; for i=1:length(x) for j=1:length(x) W(j,j)=exp(-((x(i)-x(j))^2)/(2*sigma^2)); %权重矩阵 end XX=[x ones(length(x),1)]; YY=y; C=[C inv(XX‘*W*XX)*XX‘*W*YY]; %加权最小二乘,计算求得局部线性函数的系数 end re=diag(XX*C); hold on; plot(x,re);
结果如下:
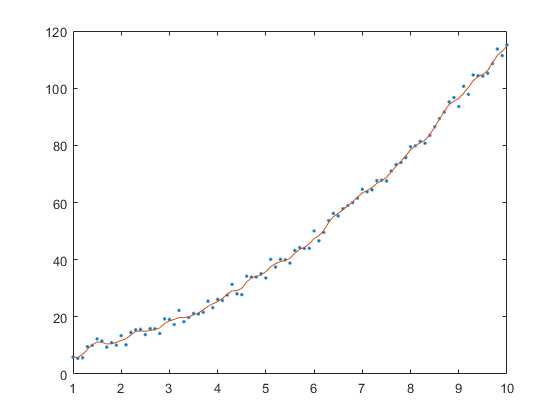
可以看出,红色的局部线性函数最终拟合出了全局的数据。
不过该方法既然不需要知道模型,那我们如何预测未来的数据结果呢?
标签:image isp hold 叠加 mat for 结果 target img
原文地址:https://www.cnblogs.com/tiandsp/p/10349822.html